

2 - Análise Técnica Básica (ATB)
Parte 1
A Análise Técnica Básica (ATB) da B3/BOVESPA compreende as etapas de:
- Aquisição do arquivo zipado (extensão ".zip")", baixado do site da B3.
- Carregamento dos dados do arquivo baixado.
- Ajuste dos dados para otimização da consulta.
- Consulta do conjunto e subconjuntos de dados, dos códigos de negociações, por faixas de datas.
- Transformação dos dados em informações.
- Plotagem e apresentação dos gráficos de dados e informações.
2.1 - Importe os pacotes Python
2.2 - Prepare os dados
Os dados utilizados estão disponíveis no site da B3 e devem ser baixados, e depois copiados, da pasta onde foram baixados em arquivos (no Windows é a pasta Downloads), para pasta de trabalho BOVESPA.
Os arquivos baixados estão em formato compactado (com extensão .zip), geralmente referido como formato zipado, e são baixados por períodos (diário, mensal ou anual).
Confirme que é humano na opção de confirmação da janela do captcha anti-robô.
Após baixados, os arquivos de cotação devem ser transferidos para o diretório de trabalho BOVESPA, onde poderão ser localizados, carregados e utilizados.
Pasta BOVESPA
Crie uma pasta nomeada "BOVESPA" na raiz do seu disco "C:" (ou no disco em que desejar, usaremos C como referência).
Baixe os arquivos da BOVESPA do site da B3
Com o navegador da Internet carregue a página de séries históricas da B3/BOVESPA.
O site de séries históricas pode ser acessado aqui.

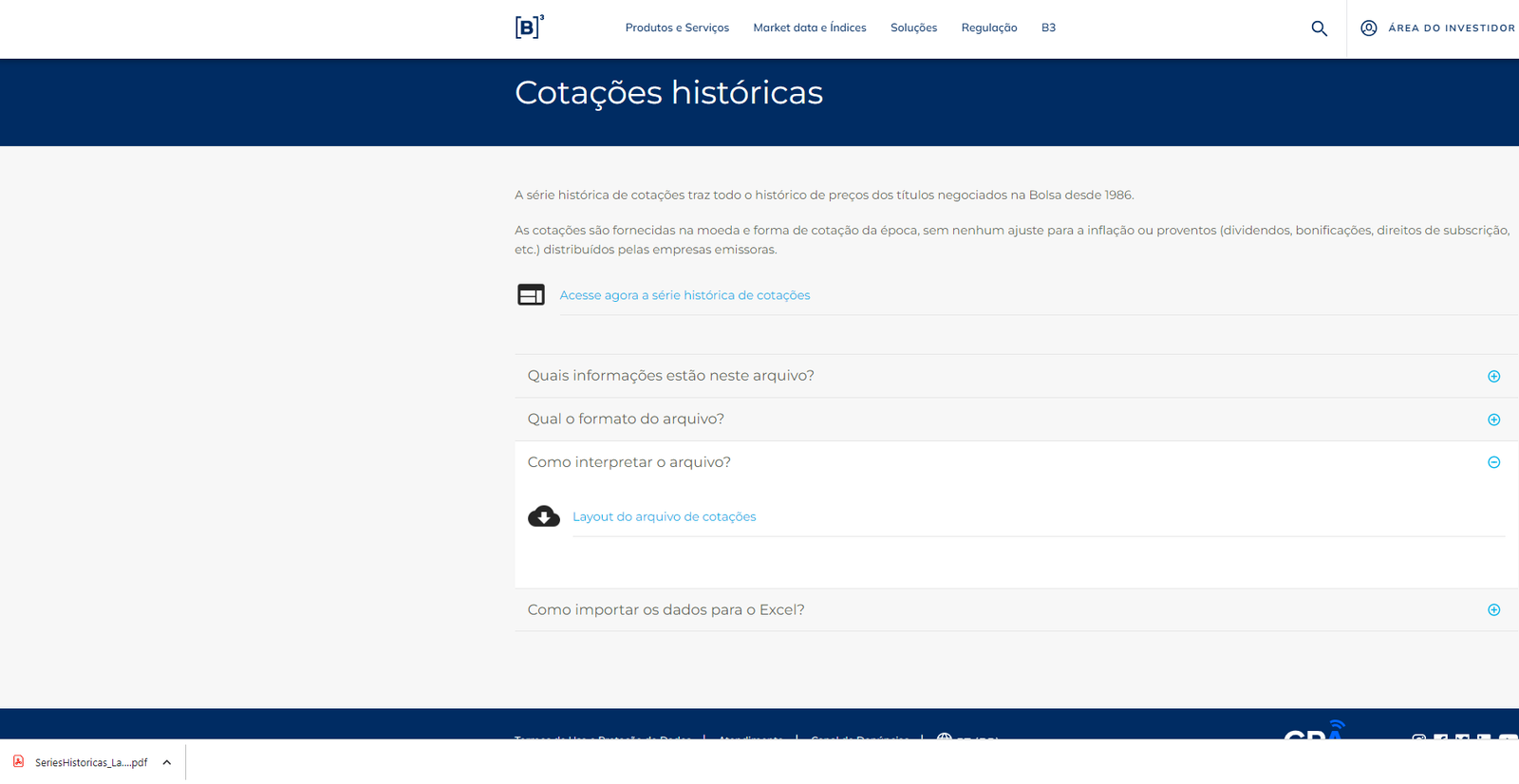
Clique em "Qual o formato do arquivo?" e depois clique em "Arquivo de demonstração".
Observe no canto inferior esquerdo o arquivo baixado.
Copie o arquivo de demonstração "SeriesHistoricas_ DemoCotacoesHistoricas12022003.zip" da pasta onde foi baixado (geralmente a pasta Downloads do Windows) para a pasta "BOVESPA".
Clique nesse arquivo e com o botão direito do mouse selecione a opção "extrair aqui" (ou "extract here"), para extrair o arquivo-texto de dentro do arquivo-zip.

O arquivo-texto "DemoCotacoesHistoricas12022003.txt" de demostração contem as linhas dos dados do pregão do dia 12/02/2003.
2.3 - Posicionamento de diretório
2.4 - Layout do arquivo de cotações
2.5 - Arquivo "SeriesHistoricas_Layout.pdf" (PDF do Layout)
Agora clique em "Como interpretar o arquivo?" e então clique em "Layout do arquivo de cotações" para baixar o arquivo "SeriesHistoricas_Layout.pdf".
Observe no canto inferior esquerdo o ícone do arquivo baixado.
Copie o arquivo, da pasta onde foi baixado (no Windows é a pasta Downloads), para a pasta de trabalho BOVESPA.

Abra este arquivo para ver o conteúdo do layout.
A seguir temos a sequência das páginas contidas no arquivo PDF com o layout dos arquivos de cotações.





2.6 - Preparação do arquivo CSV de layout
Criamos na pasta de trabalho BOVESPA um arquivo-texto no formato CSV, nomeado "bovespa_layout.csv", esquematizando, a partir das informações de layout no PDF da B3, os dados dos campos nas linhas de cotações dos arquivos zipados da B3.
Este arquivo pode ser baixado aqui.
Baixe o arquivo e copie para a pasta de trabalho BOVESPA.
Abra o arquivo no modo de leitura de texto ("rt") e imprima as linhas para ver o conteúdo do arquivo.
f = open("bovespa_layout.csv","rt",encoding='UTF-8')
line = f.readline()
while line:
print(line)
line = f.readline()
f.close()Conteúdo do arquivo:
Leitura do arquivo de layout
Carregue na variável dfbvlay o dataframe do Pandas, a partir do arquivo-csv do layout.
Observe a declaração do formato "UTF-8" de texto e o uso do caracter ";" como separador das colunas usadas no layout.
dfbvlay = pd.read_csv("bovespa_layout.csv",encoding='UTF-8',sep=";")Imprima o dataframe e veja o conteúdo do dataframe do layout de cotações.
print(dfbvlay)Função cieda_b3_tipos_tamanhos_decimais
A função cieda_b3_tipos_tamanhos_decimais carrega em 3 listas - tipos, tamanhos e decimais - os dados de layout dos campos da variável fbvlay, a fim de otimizar o acesso a estes dados.
def cieda_b3_tipos_tamanhos_decimais(dfbvlay):
tipos = []
tamanhos = []
decimais = []
for row in dfbvlay.itertuples(index=True, name='Pandas'):
tipos.append(row.TIPO)
tamanhos.append(row.TAM)
decimais.append(row.DEC)
return tipos, tamanhos, decimaisVerifique o conteúdo das listas.
Carregue as listas com a função e as imprima para ver o conteúdo.
As listas são de mesmo tamanho, e têm correspondência de índices, formando conjuntos com o tipo, tamanho e decimais do campo.
tipos, tamanhos, decimais = cieda_b3_tipos_tamanhos_decimais(dfbvlay)
print("TIPOS :", tipos)
print("TAMANHOS :", tamanhos)
print("DECIMAIS :", decimais)2.7 - Carregamento da lista de cotações
2.8 - Dataframe de tipos ajustados
2.9 - Função cieda_b3_col_data
2.10 - Função cieda_b3_df_dp()
2.11 - Função cieda_b3_df_cndp
2.12 - Função cndp
2.13 - Subconjunto VALE3/PETR4 no dia 12/0203
2.14 - Função cieda_b3_plot_cndp
2.15 - Tamanho e fonte da figura
2.16 - Exemplo
2.17 - Função cieda_b3_ler_arquivo_zip_cotacoes()
2.18 - Função cieda_b3_df_ler_arq_zip_cot()
2.19 - Exemplo: dados de 2022 (de janeiro a setembro)
2.20 - Dataframe dos meses de julho a setembro de 2022
2.21 - Dataframe com o mês de agosto de 2022
2.22 - Função cieda_b3_plot_col_codneg()
2.23 - Função cieda_b3_show_multi_cndp()
2.24 - Média Móvel Simples (MMS)
2.25 - Bandas de Bollinger
2.26 - Gráficos de uma lista de códigos de negociação
2.27 - Histogramas
2.28 - Considerações finais



