7 - Seleção e filtragem
As principais formas de seleção de um ou mais valores de um dataframe df do tipo DataFrame são os métodos:
- df.loc[]
- df.iloc[]
- df.at[]
- df.iat[]
Um subconjunto de dados do dataframe, seja por seleção de linhas, colunas ou ambas, é denominado de fatia ou slice.
A principal diferença entre loc/at e iloc/iat é a seguinte:
- loc[] e at[] são baseados em rótulos ou nomes das linhas ou colunas
- iloc[] e iat[] são baseados nos índices numéricos (mesmo que tenham nomes) sempre com base 0.
at[] e loc[]
- df.at[rot_lin, rot_col]
- df.loc[rot_lin,rot_col]
iat[] e iloc[]
- df.iat[pos_lin, pos_col]
- df.iloc[pos_lin,pos_col]
Tipos retornados
Os tipos retornados podem ser:
| Simbolo | Descrição |
|---|---|
| O | O elemento da m-ésima linha, n-ésima coluna. |
| S | Linha (tipo Series). |
| D | Tabela (tipo DataFrame). |
Nas operações df.at[] e df.iat[] os índices de linhas e colunas se referem a posições.
| Operações df.iat e df.at | Tipo | Retorno |
|---|---|---|
| df.iat[m,n] | O | elemento da m-ésima linha, n-ésima coluna |
| df.at[rot_lin,rot_col] | O | elemento linha/coluna relativas aos labels rot_lin/rot_col |
Nas operações df.iloc[] os índices de linhas e colunas se referem a posições.
| Operações df.iloc | Tipo | Retorno |
|---|---|---|
| df.iloc[n] | S | n-ésima linha |
| df.iloc[[n]] | D | n-ésima linha |
| df.iloc[-n] | S | n-ésima linha, contando do final |
| df.iloc[i,j:, n] | S | linhas i, até j (excluindo), coluna n |
| df.iloc[[i,j,k]:[m,n,o]] | D | linhas i, j, k, colunas m, n, o |
| df.iloc[:, n] | S | n-ésima coluna |
| df.iloc[:, [n]] | D | n-ésima coluna |
| df.iloc[:,-1] | S | última coluna |
| df.iloc[i:j,m:n] | D | linhas i até j (excluindo), colunas m até n (inclusive) |
Nas operações df.loc[] os índices de linhas e colunas se referem aos rótulos.
| Operações df.loc | Tipo | Retorno |
|---|---|---|
| df.loc[n] | S | linha de índice n |
| df.loc[[n]] | D | linha de índice n |
| df.loc[:] | D | todas as linhas e colunas |
| df.loc[:, 'col'] | S | todas as linhas, coluna 'col' |
| df.loc[:, ['col']] | D | todas as linhas, coluna 'col' |
| df.loc[:, ['col1', 'col2']] | D | todas as linhas, colunas 'col1' e 'col2' |
| df.loc[i:j, ['col1', 'col2']] | D | linhas com índices de i até i (inclusive), colunas 'col1' e 'col2' |
| df.loc[[i,j,k] , ['col1', 'col2']] | D | linhas com índices i, j, k, colunas 'col1' e 'col2' |
| df.loc[i:j, 'col1':'coln'] | D | linhas com índices i até j (inclusive), colunas 'col1' até 'coln' (inclusive) |
Atalhos e equivalentes:
| Atalho | Tipo | Equivalente |
|---|---|---|
| df['col1'] ou df.col1 | S | df.loc[:,'col1'] |
| df[['col1','col2']] | D | df.loc[:,['col1','col2']] |
Em todos esses métodos uma exceção de KeyError é levantada se um índice ou label não existir no dataframe.
Se o index da linha coincidir com sua posição então df.loc[n] e df.iloc[n] serão as mesmas linhas.
Isso nem sempre é verdade, como se verá abaixo com o reordenamento das linhas.
São incorretas as sintaxes, como a seguir, de loc[] usando n numérico, pois devem ser utilizados rótulos.
n = 1
df.loc[-n]
df.loc[:,n]
df.loc[:,[n]]7.1 - Exemplos de consultas e seleções.
7.2 - Manipulando linhas e colunas
7.3 - Seleção por array booleano com múltiplas condições
7.4 - Testes das funções loc e iloc
7.5 - Ordenamento com Sort
7.6 - Exemplo com dados de exercícios físicos
Pandas usa o método plot() do Pyplot do pacote Matplotlib para criar diagramas.
Importe os módulos necessários para os exemplos a seguir: o pandas e o pyplot do Matplotlib.
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as snsmpl.rcParams['figure.figsize'] = [12,9]
mpl.rcParams['figure.dpi'] = 80
mpl.rcParams['figure.titlesize'] = 32
mpl.rcParams['axes.titlesize'] = 24
mpl.rcParams['axes.labelsize'] = 20
mpl.rcParams['axes.xmargin'] = 0.01
mpl.rcParams['axes.ymargin'] = 0.01
mpl.rcParams['xtick.labelsize'] = 14
mpl.rcParams['ytick.labelsize'] = 14
mpl.rcParams["figure.subplot.left"] = 0.1
mpl.rcParams["figure.subplot.bottom"] = 0.07
mpl.rcParams["figure.subplot.right"] = 0.97
mpl.rcParams["figure.subplot.top"] = 0.9
mpl.rcParams['font.size'] = 10
mpl.rcParams['savefig.dpi'] = 100Os exemplos sobre os dados de exercícios físicos usam os do arquivo 'exercicios_fisicos.csv' no formato CSV.
Carregue o arquivo "exercicios_fisicos.csv" no formato CSV usando o método read_csv().
Baixar exercicios_fisicos.csv ou abrir exercicios-fisicos.csv
df = pd.read_csv('exercicios-fisicos.csv')
df_len = len(df)Imprima o cabeçalho do dataframe para relembrar. O completo se encontra em "Correlações".
print(df.head(5))Selecione as linhas com duração de 30 minutos.
df_aux = df[(df['Pulsomax'] >= 145)]
print(df_aux)Gráfico da seleção anterior.
df_aux.plot()
fig, axes = plt.subplots(nrows=1, ncols=3)
fig.suptitle('Pulso, Pulso máximo e calorias / 30 minutos')
fig.tight_layout(pad=3.0)
fig.subplots_adjust(left=0.1, top=0.7, right=0.9, bottom=0.1, wspace=0.2, hspace=0.5)
df_aux['Duracao'].plot(ax=axes[0],title='Duração (minutos)')
df_aux['Pulso'].plot(ax=axes[1],title='Pulso')
df_aux['Calorias'].plot(ax=axes[2],title='Calorias')
plt.show()
Seleção de valores únicos da coluna "Duracao".
df_duracao_unica = pd.unique(df['Duracao'])
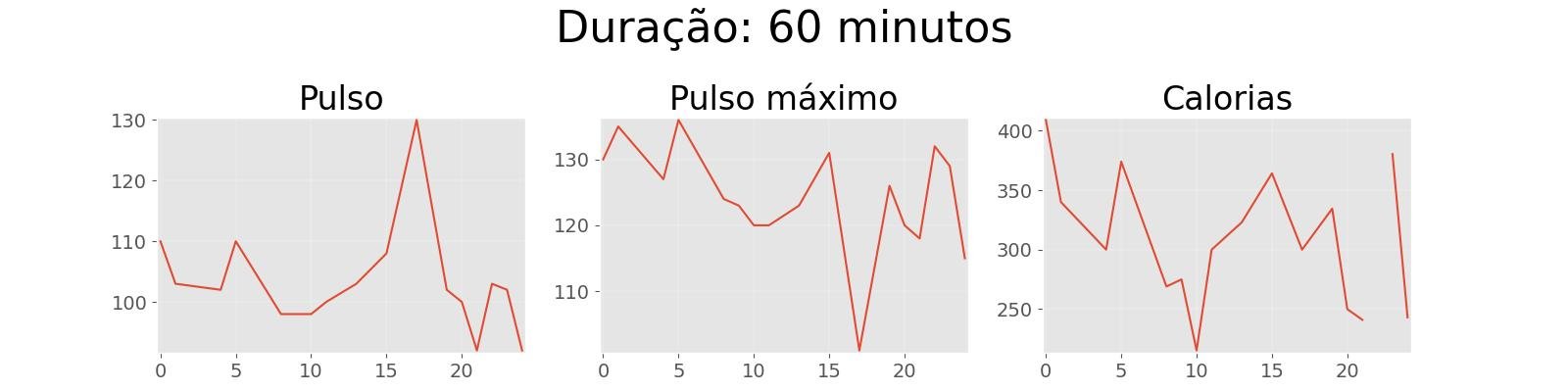
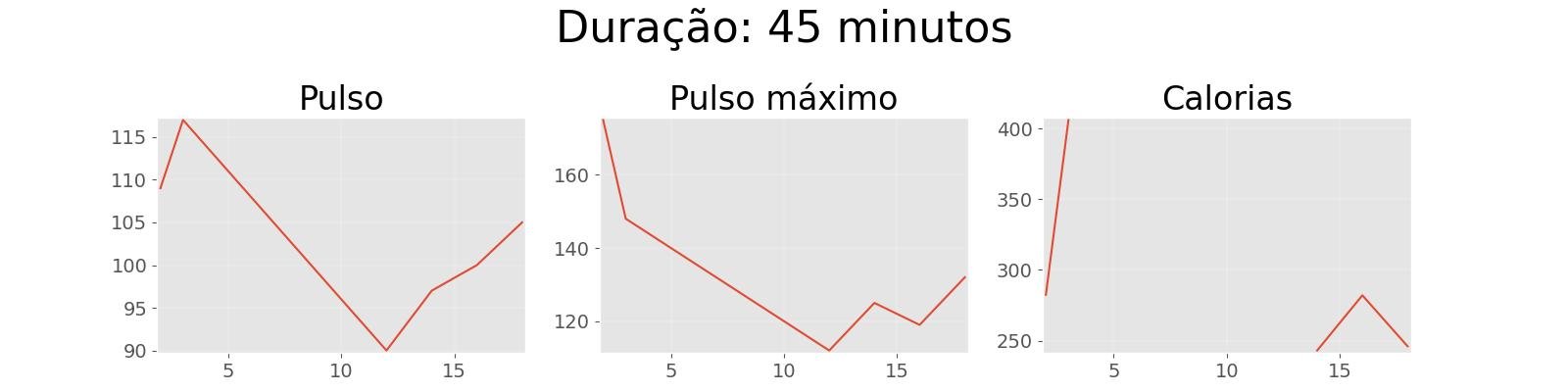
print(df_duracao_unica)Gráficos de dispersão de pulsos das durações únicas:
for duracao in df_duracao_unica:
df_aux = df[df['Duracao'] == duracao]
fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(16,4))
fig.suptitle('Duração: {} minutos'.format(duracao))
fig.tight_layout(pad=3.0)
fig.subplots_adjust(left=0.1, top=0.7, right=0.9, bottom=0.1, wspace=0.2, hspace=0.5)
df_aux['Pulso'].plot(ax=axes[0], title='Pulso')
df_aux['Pulsomax'].plot(ax=axes[1], title='Pulso máximo')
df_aux['Calorias'].plot(ax=axes[2], title='Calorias')
plt.show()