

2 - Desempenho de Tempo e Memória do Numpy
A biblioteca Numpy é escrita parcialmente em Python, mas a maioria das partes que requerem computação rápida com otimização de uso da memória são escritas em C ou C++.
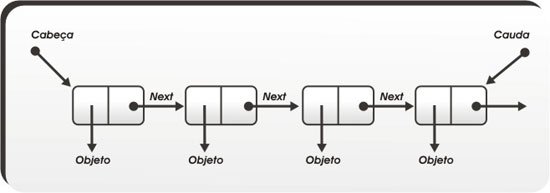
Os vetores e matrizes nativos do Python alocam e armazenam memória aos pedaços, à medida que novos dados são incluidos (no final) ou inseridos (em alguma posição).
Os vetores e matrizes Numpy são armazenadas em um local contínuo na memória (vários kilobytes (Kb), megabytes (Mb) ou mesmo gigabytes (Gb) de memória contínua), diferente das listas nativas do Python (que alocam memória item por item na lista), para que os processos possam acessá-las e manipulá-las com muita eficiência.
Esse comportamento é chamado de localidade de referência (cache locality ou locality of reference), em ciência da computação é um conceito de desempenho de memória, em que o endereço desejado de um ponteiro é calculado a partir do início da memória até a posição do deslocamento (offset) correspondente ao índice desejado.
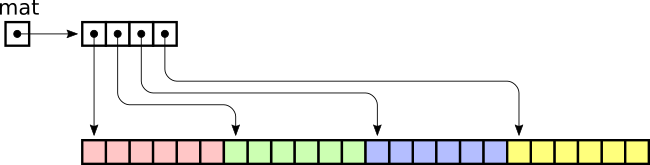
Assim, para acessar um ítem desejado, o endereço é calculado diretamente através do deslocamento do índice desejado, enquanto que com as listas nativas do Python o endereço é calculado da localização do item desejado a partir do índice desejado para encontrar o endereço do valor do item desejado.
Esta é a principal razão pela qual o Numpy é mais rápido que as listas. Também é otimizado para trabalhar com as mais recentes arquiteturas de CPU.
A prova de desempenho consiste em um conjunto de rotinas com decoradores de tempo e memória utilizados com operações de listas.
A seguir os resultados obtidos.
Rotinas de desempenho
Importamos as bibliotecas que utilizaremos.
- numpy: operações de matrizes.
- sys: operações de sistema operacional.
- time: tempo decorrido em segundos.
- memory_profiler: consumo de memória em bytes
import numpy as np
import sys
import time
import memory_profiler
from memory_profiler import profileDeclaramos a função timing_decorator do decorador "@timing_decorator" usado para medir o tempo de execução de funções.
# Decorator para medir o tempo de execução de uma função
def timing_decorator(func_vetor):
def wrapper(*args, **kwargs):
tempo_inicial = time.time()
vetor = func_vetor(*args, **kwargs)
tempo_final = time.time()
tempo_decorrido = tempo_final - tempo_inicial
return (vetor, tempo_inicial, tempo_final, tempo_decorrido)
return wrapperDeclaramos a função exec_func_vetor para ser utilizada para ser usado com o decorador "@timing_decorator" para medir o tempo de execução e com o decorador "@profile" para medir o tempo de execução de uma função, recebendo os argumentos de entrada func_rec_vetor e N, sendo func a função externa de manipulação da lista e N o seu tamanho.
@timing_decorator
@profile
def exec_func_vetor(*args, **kwargs):
try:
func = args[0]
N = args[1]
return func(N)
except Exception as e:
return ([type(e), e.args, e], 0, 0, 0)Declaramos a função imprimir_desempenho para imprimir o resultado final, com o número de itens, o tamanho, o tempo de execução e o resultado com os cinco primeiros e últimos itens da lista.
def imprimir_desempenho(rec_vetor):
(vetor, tempo_inicial, tempo_final, tempo_decorrido) = rec_vetor
tamanho = sys.getsizeof(vetor)
Kb = 1024
Mb = Kb*1024
Gb = Mb*1024
if tamanho >= Gb:
tam = f"{tamanho/Gb:.2f} Gb"
elif tamanho >= Mb:
tam = f"{tamanho/Mb:.2f} Mb"
elif tamanho >= Kb:
tam = f"{tamanho/Kb:.2f} Kb"
else:
tam = f"Tamanho: {tamanho} bytes"
aux_1 = f"{', '.join([str(s) for s in vetor[:3]])}"
aux_2 = f"{', '.join([str(s) for s in vetor[-3:]])}"
print(f"{tempo_decorrido:.4f} s | {len(vetor)} itens | {tam} | [{aux_1}, ..., {aux_2}]")Vamos executar as funções com os diferentes tamanhos de lista.
Exemplo: preencher_vetor_list_laco_append().
A função preencher_vetor_list_laco_append(). carrega a lista nativa usando a iteração de laço for e a função append() da lista.
- Criar a lista nativa vazia
- Percorrer o laço de 1 até N+1 usando a variável i
- Incluir o valor i na última posição usando a função append da lista nativa
def preencher_vetor_list_laco_append(N):
vetor = []
for i in range(1,N+1):
vetor.append(i)
return vetor
vetor_list = exec_func_vetor(preencher_vetor_list_laco_append,300_000)imprimimos os resultados.
imprimir_desempenho(vetor_list)Função que preenche a lista nativa até o valor passado como argumento usando a função range.
def preencher_vetor_list_range(N):
return list(range(1,N+1))
vetor_list = exec_func_vetor(preencher_vetor_list_range,300_000)imprimimos os resultados.
imprimir_desempenho(vetor_list)Vamos comparar com a construção correspondente com o Numpy.
def preencher_vetor_numpy_arange(N):
return np.arange(1,N+1)
vetor_numpy = exec_func_vetor(preencher_vetor_numpy_arange,300_000)imprimimos os resultados.
imprimir_desempenho(vetor_numpy)2.1 - Testes
2.2 - Limitação do Numpy



