
10 - Pacotes e Módulos
Em Python, a funcionalidade da linguagem pode ser estendida através da importação de pacotes e módulos.
Um Módulo-Python é um arquivo contendo definições e declarações de Python, agrupando funções, classes e variáveis, e código executável. Por exemplo, um arquivo chamado exemplo.py contendo funções pode ser importado e suas funções utilizadas em outro Script-Python.
Um Pacote-Python é uma coleção de Módulos-Python sob um diretório comum, permitindo a organização e reutilização de código em uma escala maior. O diretório de um pacote deve conter o arquivo __init__.py, que pode estar vazio ou conter código para inicialização do pacote. Pacotes ajudam na estruturação e modularização do código, facilitando a manutenção e o entendimento.
Tipos de Módulos:
- Módulos Nativos (ou Módulos da Biblioteca Padrão): São módulos que vêm pré-instalados com Python e são mantidos pela comunidade Python. Eles fornecem funcionalidades básicas, como operações matemáticas (math), manipulação de datas (datetime), e acesso ao sistema operacional (os). Esses módulos são otimizados e bem testados, oferecendo uma base sólida para qualquer programa.
- Módulos de Terceiros: Desenvolvidos pela comunidade, esses módulos não são distribuídos com Python, mas podem ser facilmente instalados usando gerenciadores de pacotes como pip. Exemplos populares incluem numpy para operações numéricas avançadas, pandas para manipulação de dados, e requests para fazer requisições HTTP. Esses módulos ampliam significativamente as capacidades do Python, abordando necessidades específicas que não são cobertas pela biblioteca padrão.
- Módulos Programáveis: São módulos que você ou sua equipe criam para atender às necessidades específicas de seus projetos. Eles podem ser simples (como um conjunto de funções para realizar tarefas comuns) ou complexos (como uma biblioteca inteira com classes e métodos interconectados).
Essa capacidade de estender Python com uma vasta gama de módulos facilita a adaptação da linguagem a uma ampla variedade de aplicações, tornando-a uma das linguagens de programação mais flexíveis e populares disponíveis.
10.1 - Módulos programáveis
Produzir módulos programáveis em Python é uma maneira excelente de organizar seu código, tornando-o mais reutilizável, legível e manutenível. Aqui estão os passos básicos para criar seus próprios módulos programáveis em Python:
Planeje Seu Módulo
Antes de começar a codificar, é importante planejar a funcionalidade do módulo.
Decida quais funções, classes e dados ele deve conter.
Pense na interface que seu módulo vai oferecer aos outros códigos que o importarem.
Crie um Arquivo para o Módulo
Um módulo em Python é simplesmente um arquivo com a extensão .py.
Crie um arquivo e nomeie-o de forma que descreva suas funcionalidades.
Por exemplo, se você está criando um módulo para manipular dados geográficos, você poderia chamá-lo de geo_utils.py.
Escreva o Código do Módulo
Dentro do arquivo, escreva as funções, classes e constantes que você planejou.
Cada função ou classe deve ter uma responsabilidade clara.
Use docstrings para documentar o propósito e o uso de cada componente.
Aqui está um exemplo simples de como o módulo pode ser estruturado:
# geo_utils.py
def calculate_distance(point1, point2):
"""Calcula a distância euclidiana entre dois pontos."""
return ((point1[0] - point2[0])**2 + (point1[1] - point2[1])**2) ** 0.5
class Point:
"""Representa um ponto em um espaço bidimensional."""
def __init__(self, x, y):
self.x = x
self.y = y
def move(self, dx, dy):
"""Move o ponto em dx e dy no espaço bidimensional."""
self.x += dx
self.y += dyTeste Seu Módulo
Antes de usar seu módulo em outros programas, é importante testá-lo para garantir que ele funciona como esperado. Você pode escrever testes unitários usando um framework como unittest ou pytest.
Use o Módulo em Outros Projetos
Uma vez que seu módulo esteja testado e funcionando, você pode usá-lo em outros projetos simplesmente importando-o. Supondo que o módulo geo_utils.py esteja no mesmo diretório do seu script, você pode fazer:
import geo_utils
point1 = (1, 2)
point2 = (4, 6)
distance = geo_utils.calculate_distance(point1, point2)
print("A distância é:", distance)
p = geo_utils.Point(2, 3)
p.move(5, -1)
print("Novo ponto:", (p.x, p.y))Distribua Seu Módulo
Se você acha que seu módulo pode ser útil para outros desenvolvedores, considere distribuí-lo através do PyPI, o repositório oficial de pacotes Python. Para isso, você precisará criar um arquivo setup.py e empacotar seu módulo adequadamente.
Mantenha e Atualize Seu Módulo
À medida que seu módulo é usado, você pode descobrir bugs ou áreas para melhorias. Mantenha seu módulo atualizado e considere o feedback dos usuários para futuras versões.
Criar módulos programáveis é uma prática valiosa que não apenas melhora suas habilidades de programação, mas também contribui para a comunidade de código aberto, caso você escolha compartilhar seu trabalho.
10.2 - Pacotes Nativos
Python vem com uma "bateria inclusa", significando que ele tem uma vasta biblioteca padrão que inclui módulos para realizar uma variedade de tarefas sem a necessidade de instalar pacotes adicionais. Aqui estão alguns dos principais pacotes nativos e módulos da Biblioteca Padrão do Python, juntamente com suas funcionalidades básicas:
Esses são apenas alguns dos muitos módulos disponíveis na Biblioteca Padrão do Python, cada um projetado para facilitar tarefas comuns de programação e aumentar a produtividade.
10.2.1 - sys
Fornece acesso a variáveis e funcionalidades específicas do sistema.
O módulo sys é uma parte importante da Biblioteca Padrão do Python e fornece acesso a variáveis e funcionalidades diretamente relacionadas ao interpretador Python.
O módulo sys é extremamente útil para scripts que precisam interagir com o ambiente em que estão rodando ou para manipular o próprio comportamento do interpretador Python.
A capacidade de acessar essas funções e variáveis torna sys um módulo fundamental para programação Python avançada.
Permite manipular a pilha de importação de Python e também acessar parâmetros da linha de comando.
Aqui estão alguns dos principais recursos e funções oferecidos pelo módulo sys:
sys.argv
sys.argv é uma lista em Python, que contém os argumentos da linha de comando passados para um script. argv[0] é o nome do script (depende do sistema operacional e de como o script é chamado). Os argumentos subsequentes são passados pela linha de comando.
sys.exit()
Esta função permite sair do Python de maneira limpa. Você pode fornecer um status de saída opcional, que é passado ao ambiente de chamada.
sys.path
Uma lista de strings que especifica os caminhos de diretório em que o Python procura por módulos importados. Além dos diretórios padrão, esta lista pode ser modificada para incluir caminhos adicionais.
sys.modules
É um dicionário que mapeia nomes de módulos para módulos que já foram carregados. Isso permite que o Python use módulos já carregados sem ter que carregá-los novamente, economizando tempo.
sys.stdin, sys.stdout, sys.stderr
Estas são interfaces de objeto de arquivo para a entrada padrão, saída padrão e erro padrão do script, respectivamente. sys.stdin lê a entrada de dados, sys.stdout é usado para a saída de dados (por exemplo, usando print), e sys.stderr é usado para emitir avisos e mensagens de erro.
sys.version
Uma string que contém a versão do interpretador Python em uso, juntamente com algumas informações adicionais sobre a compilação.
sys.platform
Uma string que indica a plataforma subjacente, como 'linux' ou 'win32'. Útil para fazer ajustes de código específicos para a plataforma.
sys.getsizeof()
Retorna o tamanho de um objeto em bytes. É útil para monitorar o uso de memória.
sys.executable
O caminho para o executável do interpretador Python. Útil para programas que precisam chamar outro script Python.
sys.getrecursionlimit() e sys.setrecursionlimit(limit)
Funções para consultar ou definir o limite máximo de recursão para o interpretador Python. Isso pode ajudar a evitar que um programa caia devido a uma recursão excessiva (ou seja, um "estouro de pilha").
sys.exc_info()
Retorna uma tupla contendo informações sobre a exceção que está sendo tratada. Útil em blocos `except` para obter detalhes sobre o que causou a exceção atual.
10.2.2 - os
Fornece uma maneira portátil de usar funcionalidades dependentes do sistema operacional, como ler ou escrever arquivos, manipular caminhos, e variáveis de ambiente.
O módulo os do Python é uma biblioteca extremamente útil que fornece uma forma portátil de usar funcionalidades que dependem do sistema operacional.
Ele permite que você interaja com o sistema operacional de maneira independente da plataforma, abstraindo as diferenças entre os sistemas operacionais.
Essas funcionalidades tornam o módulo os essencial para scripts que precisam realizar manipulações de arquivos, diretórios ou interagir com o sistema operacional de uma maneira geral. A capacidade de funcionar em diferentes plataformas sem alterar o código é uma grande vantagem, tornando os scripts muito mais portáteis e fáceis de manter.
Aqui estão algumas das principais funcionalidades oferecidas pelo módulo os:
os.name
Retorna o nome do sistema operacional dependente do módulo importado (posix, nt, java, etc.).
import os
print(os.name) # Saída pode ser 'posix', 'nt', 'java', etc.os.environ
Um dicionário que mapeia nomes de variáveis de ambiente para seus valores. Por exemplo, os.environ['HOME'] retornaria o diretório home do usuário no Linux ou no MacOS.
import os
print(os.environ['HOME'])os.chdir(path)
Muda o diretório de trabalho atual para o caminho especificado. É equivalente ao comando de terminal cd.
import os
os.chdir('/home/user')os.getcwd()
Retorna o diretório de trabalho atual como uma string.
import os
print(os.getcwd())os.mkdir(path)
Cria um diretório no caminho especificado. Se o diretório já existir, isso lançará uma exceção.
import os
os.mkdir('/home/user')os.makedirs(path)
Similar a os.mkdir, mas cria todos os diretórios intermediários necessários para alcançar o caminho dado. É útil para criar árvores de diretórios completas de uma só vez.
import os
os.makedirs('/home/user')os.rmdir(path)
Remove o diretório no caminho especificado. O diretório deve estar vazio, caso contrário, uma exceção será levantada.
import os
os.rmdir('/home/user')os.removedirs(path)
Remove diretórios recursivamente. Tenta remover todos os diretórios parentes vazios.
import os
os.removedirs('/home/user')os.remove(path) e os.unlink(path)
Remove (deleta) o arquivo no caminho especificado. os.unlink é um alias para os.remove.
import os
os.remove('/home/user')os.system(command)
Executa o comando (uma string) em um subshell. Isso é útil para executar comandos shell diretamente do Python.
import os
os.system('ls')os.path
Um submódulo dentro do `os` que fornece uma série de funções para manipular nomes de arquivos e caminhos. Por exemplo, `os.path.join` para construir caminhos de arquivos de maneira segura, `os.path.exists` para verificar se um arquivo ou diretório
existe, e `os.path.isfile` para verificar se um determinado caminho é um arquivo.
import os
os.path.join('/home/user', 'file.txt')
os.path.exists('/home/user/file.txt')
os.path.isfile('/home/user/file.txt')os.walk(top)
Gera os nomes dos arquivos em uma árvore de diretórios, caminhando pela árvore de cima para baixo ou de baixo para cima. É útil para encontrar todos os arquivos dentro de um diretório e seus subdiretórios.
import os
for root, dirs, files in os.walk('/home/user'):
print(root, dirs, files)os.stat(path)
Obtém informações de status do arquivo ou diretório no caminho especificado. Isso pode incluir informações como tamanho do arquivo, data de modificação e permissões.
import os
os.stat('/home/user/file.txt')os.execvp(program, arguments)
Executa o programa, substituindo o processo atual com o programa especificado. Diferente de `os.system`, `os.execvp` não retorna ao programa original; o novo programa toma o controle completamente.
import os
os.execvp('ls', [])10.2.3 - math
Oferece acesso a funções matemáticas básicas como seno, cosseno, raiz quadrada, exponencial, entre outras.
O módulo math do Python faz parte da Biblioteca Padrão e fornece acesso a funções matemáticas definidas pela especificação C para operações de ponto flutuante.
Isso inclui funções básicas de aritmética, trigonometria, exponenciação, e muito mais.
O módulo math é essencial para quem precisa realizar cálculos matemáticos mais complexos
Aqui estão algumas das funcionalidades mais notáveis e comuns do módulo math:
Funções Trigonométricas
- math.sin(x): Retorna o seno de x radianos.
- math.cos(x): Retorna o cosseno de x radianos.
- math.tan(x): Retorna a tangente de x radianos.
- math.asin(x): Retorna o arco seno de x, em radianos.
- math.acos(x): Retorna o arco cosseno de x, em radianos.
- math.atan(x): Retorna o arco tangente de x, em radianos.
- math.atan2(y, x): Retorna o arco tangente de y/x, levando em consideração os quadrantes do plano cartesiano.
import math
x = math.pi
y = 0.5
print(f"x = {x}")
print(f"y = {y}")
print()
print(f"math.sin(x) = {math.sin(x)}")
print(f"math.cos(x) = {math.cos(x)}")
print(f"math.tan(x) = {math.tan(x)}")
print()
print(f"math.asin(y) = {math.asin(y)}")
print(f"math.acos(y) = {math.acos(y)}")
print(f"math.atan(y) = {math.atan(y)}")Funções Hiperbólicas
- math.sinh(x): Retorna o seno hiperbólico de x.
- math.cosh(x): Retorna o cosseno hiperbólico de x.
- math.tanh(x): Retorna a tangente hiperbólica de x.
- math.asinh(x): Retorna o arco seno hiperbólico de x.
- math.acosh(x): Retorna o arco cosseno hiperbólico de x, para x >= 1.
- math.atanh(x): Retorna o arco tangente hiperbólica de x, para -1 < x < 1.
import math
x = 0.5
y = 2
print(f"x = {x}")
print(f"y = {y}")
print()
print(f"math.sinh(x) = {math.sinh(x)}")
print(f"math.cosh(x) = {math.cosh(x)}")
print(f"math.tanh(x) = {math.tanh(x)}")
print()
print(f"math.asinh(y) = {math.asinh(y)}")
print(f"math.acosh(y) = {math.acosh(y)}")
print(f"math.atanh(x) = {math.atanh(x)}")Funções de Exponenciação e Logaritmo
- math.exp(x): Retorna e^x, onde e é a base dos logaritmos naturais.
- math.log(x[, base]): Retorna o logaritmo de x na base especificada. Se a base não for especificada, retorna o logaritmo natural de x.
- math.log2(x): Retorna o logaritmo de base 2 de x.
- math.log10(x): Retorna o logaritmo de base 10 de x.
- math.pow(x, y): Retorna x^y, equivalente a elevar x à potência de y.
- math.sqrt(x): Retorna a raiz quadrada de x.
import math
x = 2
print(f"x = {x}")
print(f"math.exp({x}) = {math.exp(x)}")
print(f"math.log({x}) = {math.log(x)}")
print(f"math.log2({x}) = {math.log2(x)}")
print(f"math.log10({x}) = {math.log10(x)}")
print()
y = 2
print(f"y = {y}")
print(f"math.pow({x}, {y}) = {math.pow(x, y)}")
print(f"math.sqrt({y}) = {math.sqrt(y)}")Funções de Arredondamento
- math.ceil(x): Arredonda x para o menor inteiro maior ou igual a x.
- math.floor(x): Arredonda x para o maior inteiro menor ou igual a x.
- math.trunc(x): Retorna o valor de x truncado para um inteiro (elimina a parte decimal).
- round(x[, n]): Arredonda x para n casas decimais. Quando n é omitido, arredonda para o inteiro mais próximo.
import math
x = 1.4
print(f"x = {x}")
print(f"math.ceil({x}) = {math.ceil(x)}")
print(f"math.floor({x}) = {math.floor(x)}")
print(f"math.trunc({x}) = {math.trunc(x)}")
print(f"round({x}) = {round(x)}")Constantes
- math.pi: A constante π, útil para cálculos de geometria.
- math.e: A base dos logaritmos naturais.
- math.tau: A constante τ, equivalente a 2π, útil em algumas fórmulas trigonométricas.
- math.inf: Uma constante que representa o infinito positivo.
- math.nan: Uma constante que representa um "Not a Number" (não é um número).
import math
print(f"math.pi = {math.pi}")
print(f"math.e = {math.e}")
print(f"math.tau = {math.tau}")
print(f"math.inf = {math.inf}")
print(f"math.nan = {math.nan}")Outras Funções Úteis
- math.fabs(x): Retorna o valor absoluto de x como um float.
- math.isfinite(x): Verifica se x é finito (nem infinito, nem NaN).
- math.isinf(x): Verifica se x é infinito.
- math.isnan(x): Verifica se x é NaN.
- math.copysign(x, y): Retorna x com o sinal de y.
- math.fmod(x, y): Retorna o resto da divisão de x por y, usando a operação de módulo.
import math
x = 1.4
print(f"x = {x}")
print(f"math.fabs({x}) = {math.fabs(x)}")
print(f"math.isfinite({x}) = {math.isfinite(x)}")
print(f"math.isinf({x}) = {math.isinf(x)}")
print(f"math.isnan({x}) = {math.isnan(x)}")
print()
y = 2
print(f"y = {y}")
print(f"math.copysign({x}, {y}) = {math.copysign(x, y)}")
print(f"math.fmod({x}, {y}) = {math.fmod(x, y)}")10.2.4 - datetime
Permite manipular datas e tempos de maneiras complexas, como aritmética de data e tempo, conversão entre zonas horárias, e formatação.
O módulo datetime do Python é uma parte fundamental da Biblioteca Padrão e oferece classes para manipular datas e horas. Ao contrário de muitas outras linguagens de programação, Python oferece um suporte bastante robusto e intuitivo para essas tarefas através do datetime.
O módulo datetime é extremamente poderoso para todas as necessidades de manipulação de data e hora no Python, desde as mais simples até as mais complexas, como cálculos precisos e manipulação de fusos horários.
Vamos explorar as principais funcionalidades e classes que esse módulo oferece:
Classes Principais
datetime.date
Representa uma data (ano, mês e dia) em calendário Gregoriano. Métodos úteis incluem today() para a data atual, e fromtimestamp(timestamp) para criar uma data a partir de um timestamp UNIX.
datetime.time
Representa um horário independente de qualquer data particular. Inclui hora, minuto, segundo, microssegundo e fuso horário.
datetime.datetime
Combinação das duas classes anteriores, representando tanto a data quanto o horário. Métodos importantes incluem now(), utcnow() para a hora atual no fuso horário UTC, e fromtimestamp(timestamp).
datetime.timedelta
Representa uma diferença entre duas datas ou tempos, permitindo operações de adição e subtração em datas e tempos para calcular datas futuras ou passadas. Pode ser expresso em dias, segundos e microssegundos.
datetime.tzinfo
É uma classe abstrata para lidar com informações de fuso horário. Você pode criar subclasses para implementar métodos que lidam com detalhes específicos de ajuste de fuso horário.
Manipulação de Data e Hora
O datetime permite não apenas a criação de objetos de data e hora, mas também a manipulação desses. Aqui estão algumas operações comuns:
Adicionar ou subtrair dias
Utilizando datetime.timedelta, você pode adicionar ou subtrair uma quantidade específica de dias, segundos ou microssegundos de um objeto datetime.
from datetime import datetime, timedelta
now = datetime.now()
one_week_later = now + timedelta(weeks=1)Diferença entre datas: Você pode subtrair um objeto datetime de outro para obter um timedelta que representa a diferença entre eles.
date1 = datetime(2024, 5, 1)
date2 = datetime(2024, 5, 13)
difference = date2 - date1Formatar e parsear datas: strftime() e strptime() são métodos para formatar objetos datetime como strings e parsear strings para objetos datetime, respectivamente.
now = datetime.now()
formatted_date = now.strftime('%Y-%m-%d %H:%M:%S')
parsed_date = datetime.strptime('2024-05-13', '%Y-%m-%d')Exemplos Práticos
Obtendo a data atual
from datetime import datetime
today = datetime.today()
print(today)Manipulando fusos horários
from datetime import datetime
from pytz import timezone
fmt = '%Y-%m-%d %H:%M:%S %Z%z'
eastern = timezone('US/Eastern')
loc_dt = eastern.localize(datetime(2024, 5, 13, 12, 34, 56))
print(loc_dt.strftime(fmt))Calculando a idade
from datetime import datetime
birth_date = datetime(1990, 5, 13)
today = datetime.today()
age = today.year - birth_date.year - ((today.month, today.day) < (birth_date.month, birth_date.day))
print(age)Comparando datas
from datetime import datetime
date1 = datetime(2024, 5, 1)
date2 = datetime(2024, 5, 13)
print(date1 < date2)10.2.5 - collections
Contém tipos de dados alternativos como Counter, deque, OrderedDict, e namedtuple.
O módulo collections do Python é parte da Biblioteca Padrão e oferece alternativas especializadas aos contêineres de dados built-in como dicionários, listas, conjuntos e tuplas. Vamos explorar as classes mais notáveis fornecidas por esse módulo:
Estas classes do módulo collections são altamente otimizadas para performance e usabilidade, provendo alternativas mais flexíveis aos tipos de dados padrões. Elas são extremamente úteis em várias situações, como quando se necessita de um controle mais fino sobre a memória, a ordem dos elementos, ou comportamentos personalizados de coleções de dados.
Counter
Counter é uma subclasse de dict que é usada para contar objetos hashable. Ele é útil para casos em que você precisa contar a ocorrência de elementos em um iterável.
from collections import Counter
counts = Counter(['a', 'b', 'c', 'a', 'b', 'b'])
print(counts) # Output: Counter({'b': 3, 'a': 2, 'c': 1})deque
deque (pronuncia-se "deck") é uma lista otimizada para inserções e exclusões rápidas de ambas as extremidades. É excelente para filas e implementações de pilhas.
from collections import deque
d = deque([1, 2, 3])
d.appendleft(0) # Adiciona 0 no início
d.append(4) # Adiciona 4 no final
print(d) # Output: deque([0, 1, 2, 3, 4])OrderedDict
OrderedDict é uma subclasse de dict que lembra a ordem em que as chaves foram inseridas pela primeira vez. Isso é útil quando a ordem das chaves é importante para considerar.
from collections import OrderedDict
ordered = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
ordered['d'] = 4
print(list(ordered.keys())) # Output: ['a', 'b', 'c', 'd']defaultdict
defaultdict é uma subclasse de dict que fornece um valor default para a chave que ainda não está no dicionário.
from collections import defaultdict
dd = defaultdict(int) # int() retorna 0
dd['key'] += 1
print(dd['key']) # Output: 1namedtuple
namedtuple gera subclasses de tuplas com campos nomeados. É útil para criar tuplas auto-documentadas com pouco esforço.
from collections import namedtuple
Point = namedtuple('Point', ['x', 'y'])
p = Point(11, y=22)
print(p.x, p.y) # Output: 11 22ChainMap
ChainMap é uma classe que agrupa múltiplos dicionários em uma única visão. As buscas consultam os dicionários subjacentes na ordem em que são especificados até que uma chave seja encontrada.
from collections import ChainMap
defaults = {'theme': 'Default', 'language': 'eng'}
config = {'theme': 'Dark'}
combined = ChainMap(config, defaults)
print(combined['theme']) # Output: 'Dark'
print(combined['language']) # Output: 'eng'UserDict, UserList, UserString
Essas são classes wrapper em torno dos tipos de dados dicionário, lista e string que facilitam a criação de subclasses desses tipos.
10.2.6 - json
Permite codificar e decodificar dados em JSON, um formato comum para armazenamento de dados e comunicação em aplicações web.
O módulo json é uma parte essencial da Biblioteca Padrão do Python e fornece uma maneira fácil de codificar e decodificar dados em JSON (JavaScript Object Notation). JSON é um formato leve para troca de dados que é fácil para humanos lerem e escreverem, e fácil para máquinas parsearem e gerarem. Este formato é amplamente usado em APIs na web e configurações de dados devido à sua simplicidade e eficiência.
Principais Funcionalidades
json.dump(obj, file, ...)
Serializa obj como um formato JSON formatado, escrevendo-o em um objeto arquivo. Existem vários argumentos opcionais para controlar como os dados são formatados, como skipkeys, ensure_ascii, check_circular, allow_nan, cls, indent, separators, e default.
import json
data = {"name": "John", "age": 30, "city": "New York"}
with open('data.json', 'w') as f:
json.dump(data, f, indent=4)json.dumps(obj, ...)
Serializa obj para uma string JSON formatada com os mesmos argumentos opcionais que json.dump().
import json
data = {"name": "John", "age": 30, "city": "New York"}
json_texto = json.dumps(data, indent=4)
print(json_texto)json.load(file)
Deserializa um objeto arquivo, que deve conter uma string JSON, retornando o objeto de dados Python correspondente.
import json
with open('data.json', 'r') as f:
data = json.load(f)
print(data)json.loads(s)
Deserializa s (uma instância de str, bytes ou bytearray contendo um documento JSON) para um objeto Python.
import json
json_string = '{"name": "John", "age": 30, "city": "New York"}'
data = json.loads(json_string)
print(data)json.JSONEncoder
Classe base para serializar e decodificar dados em JSON.
json.JSONDecoder
Classe base para decodificar dados em JSON.
json.JSONEncoder.default(obj)
Classe base para decodificar dados em JSON.
json.JSONEncoder.encode(obj)
Classe base para serializar dados em JSON.
json.JSONDecoder.decode(s)
Classe base para decodificar dados em JSON.
Considerações e Dicas
- Extensibilidade: Você pode personalizar como objetos complexos são codificados e decodificados usando os parâmetros cls (para subclasses JSONEncoder e JSONDecoder) e default (para definir uma função de fallback para tipos que o JSONEncoder padrão não sabe serializar).
- Compatibilidade com Tipos de Dados: O módulo json nativamente suporta a serialização de listas, dicionários, strings, inteiros, números de ponto flutuante, e valores booleanos e None. Para outros tipos, é necessário fornecer uma função ou classe para personalizar a serialização.
- Manuseio de Erros: O módulo json lança JSONDecodeError se o JSON não estiver correto ou TypeError se o objeto não for serializável.
- Performance: Enquanto json é adequado para a maioria das aplicações, se a performance for uma grande preocupação (especialmente em grandes volumes de dados), você pode considerar usar bibliotecas como ujson ou orjson que oferecem melhorias de performance significativas.
O módulo json é uma ferramenta versátil e poderosa no Python, facilitando a integração com sistemas que utilizam JSON para troca de dados.
É uma parte vital da caixa de ferramentas de qualquer programador que trabalha com APIs da Web ou configurações de dados em projetos modernos de software.
10.2.7 - http
Contém módulos como http.client para clientes HTTP e http.server para criar servidores web básicos.
O módulo http é uma parte da Biblioteca Padrão do Python que fornece uma série de classes e funções para manipular requisições e respostas HTTP.
O módulo http é estruturado em submódulos que oferecem funcionalidades específicas.
Vamos explorar os principais submódulos e suas funcionalidades:
http.client
Este submódulo fornece uma interface de cliente HTTP de baixo nível.
É útil para interagir diretamente com servidores web ao enviar requisições HTTP e receber respostas.
Principais Funções e Classes:
- HTTPConnection: Uma classe que representa uma conexão HTTP a um servidor web. Você pode usar esta classe para enviar requisições e receber respostas.
- HTTPResponse: Uma classe que encapsula a resposta de uma requisição HTTP. Fornece métodos para ler a resposta do servidor.
- Métodos como request(), getresponse(), e close(): Usados para enviar uma requisição, obter a resposta e fechar a conexão, respectivamente.
Exemplos
import http.client
conn = http.client.HTTPConnection('www.example.com')
conn.request("GET", "/")
response = conn.getresponse()
print(response.status, response.reason)
data = response.read()
conn.close()http.server
Este submódulo contém classes base para escrever servidores HTTP.
Ele pode ser usado para criar um servidor web simples ou para mockar um servidor durante testes de desenvolvimento.
Principais Classes:
- HTTPServer: Uma classe de servidor HTTP básica.
- BaseHTTPRequestHandler: Uma classe base para manipular requisições HTTP recebidas pelo servidor. Pode ser estendida para tratar diferentes tipos de requisições HTTP como GET e POST.
from http.server import HTTPServer, BaseHTTPRequestHandler
class SimpleHTTPRequestHandler(BaseHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.end_headers()
self.wfile.write(b'Hello, world!')
server_address = ('', 8000)
httpd = HTTPServer(server_address, SimpleHTTPRequestHandler)
httpd.serve_forever()http.cookies
Este submódulo fornece utilitários para manipular cookies HTTP.
Cookies são pequenos pedaços de dados armazenados no navegador do usuário que o servidor web pode usar para manter o estado da sessão entre as requisições.
Principais Funções e Classes:
- SimpleCookie: Uma classe que pode analisar e serializar cookies de acordo com o padrão RFC 6265.
from http.cookies import SimpleCookie
cookie = SimpleCookie()
cookie['name'] = 'John'
cookie['name']['domain'] = 'www.example.com'
cookie['name']['path'] = '/'
print(cookie.output())http.cookiejar
Este submódulo fornece uma maneira de manipular cookies em requisições HTTP feitas usando módulos como urllib.
Ele pode ser usado para armazenar e recuperar cookies entre diferentes requisições HTTP.
Principais Funções e Classes:
- CookieJar: Uma classe que armazena cookies e suas políticas de segurança.
import http.cookiejar, urllib.request
cj = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
response = opener.open('http://www.example.com')Conclusão
O módulo http é fundamental para a programação de rede em Python, oferecendo ferramentas tanto para desenvolver clientes como servidores HTTP.
Ele permite interações detalhadas com o protocolo HTTP e é extensível o suficiente para lidar com casos de uso complexos e específicos, como manipulação de cookies e autenticação HTTP.
10.2.8 - argparse
Utilizado para escrever interfaces de linha de comando amigáveis ao usuário. Ele permite a criação de comandos e argumentos de maneira organizada.
O módulo argparse é uma ferramenta poderosa na Biblioteca Padrão do Python para criar interfaces de linha de comando (CLI). Ele facilita a escrita de programas amigáveis ao usuário que podem processar argumentos da linha de comando. Isso é útil para scripts que precisam de mais flexibilidade na entrada de dados do que simplesmente ler de stdin ou usar parâmetros fixos.
Principais Funcionalidades
argparse permite que você lide com argumentos da linha de comando de maneira estruturada e fácil de entender.
A seguir estão os conceitos chave e funcionalidades do módulo.
Parser
O objeto ArgumentParser é o ponto central do módulo argparse.
Você cria uma instância dessa classe e usa métodos para adicionar informações sobre os argumentos que seu programa aceita.
Criando um ArgumentParser
O método ArgumentParser() é usado para criar um objeto ArgumentParser.
Você pode passar um nome para o objeto, e você pode configurar algumas opções do objeto.
- name: O nome do objeto.
- usage: Uma string de ajuda para o usuário. Você pode usar o método format_usage() para formatar a string de ajuda.
- epilog: Uma string de ajuda para o usuário. Você pode usar o método format_epilog() para formatar a string de ajuda.
- description: Uma string de ajuda para o usuário. Você pode usar o método format_description() para formatar a string de ajuda.
- version: Uma string de ajuda para o usuário. Você pode usar o método format_version() para formatar a string de ajuda.
- formatter_class: Um formatter de ajuda para o usuário. Você pode usar o método get_formatter_class() para obter o formatter padrão.
- prog: O nome do programa. Você pode usar o método format_prog() para formatar o nome do programa.
- add_usage: Se o argumento de linha de comando deve ter ajuda. O valor padrão é True.
- add_version: Se o argumento de linha de comando deve ter ajuda. O valor padrão é True.
- add_description: Se o argumento de linha de comando deve ter ajuda. O valor padrão é True.
- add_epilog: Se o argumento de linha de comando deve ter ajuda. O valor padrão é True.
- add_argument_group: Se o argumento de linha de comando deve ter ajuda. O valor padrão é True.
- add_mutually_exclusive_group: Se o argumento de linha de comando deve ter ajuda. O valor padrão é True.
- add_argument: Se o argumento de linha de comando deve ter ajuda. O valor padrão é True.
- add_option: Se o argumento de linha de comando deve ter ajuda. O valor padrão é True.
- add_help: Se o argumento de linha de comando deve ter ajuda. O valor padrão é True.
Adicionando Argumentos
O método add_argument() é usado para especificar qual informação um programa espera. Você pode definir vários detalhes sobre cada argumento, como:
- name ou flags: Nomes como -f, --foo.
- action: A ação básica a ser tomada quando este argumento é encontrado. Algumas ações são store, store_true, store_false, append, e assim por diante.
- nargs: O número de argumentos da linha de comando que deve ser consumido.
- const: Um valor constante necessário para algumas ações e nargs.
- default: O valor padrão do argumento.
- type: O tipo para o qual o argumento deve ser convertido.
- choices: Um contêiner de valores permitidos.
- required: Se o argumento de linha de comando é opcional ou obrigatório.
- help: Uma breve descrição do que o argumento faz.
Parseando Argumentos
Após configurar seu ArgumentParser, você usa o método parse_args() para converter os argumentos da linha de comando nos tipos apropriados e tomar as ações apropriadas.
Ele retorna um objeto com atributos simples para acessar os argumentos parseados.
Tratamento de Erros
argparse automaticamente gera mensagens de erro quando o usuário fornece argumentos inválidos e também gera automaticamente mensagens de ajuda quando solicitado (usualmente via -h ou --help).
Exemplo
Aqui está um exemplo simples que ilustra como criar um script de linha de comando com argparse:
import argparse
# Cria o parser
parser = argparse.ArgumentParser(description="Process some integers.")
# Adiciona um argumento
parser.add_argument('integers', metavar='N', type=int, nargs='+',
help='an integer for the accumulator')
# Adiciona outro argumento com um valor default e tipo específico
parser.add_argument('--sum', dest='accumulate', action='store_const',
const=sum, default=max,
help='sum the integers (default: find the max)')
# Faz o parse dos argumentos
args = parser.parse_args()
# Usa os argumentos
result = args.accumulate(args.integers)
print(result)Neste exemplo, o script aceita uma lista de inteiros e uma opção --sum. Se --sum é especificado, o script soma os inteiros; se não, retorna o máximo.
Conclusão
O módulo argparse é extremamente útil para scripts que precisam processar argumentos da linha de comando de maneira robusta e fácil de entender.
Ele substituiu o módulo mais antigo optparse e oferece maior flexibilidade.
Usando argparse, você pode facilmente transformar um simples script em uma poderosa ferramenta de linha de comando, com pouco esforço adicional.
10.2.9 - logging
Oferece um sistema de logging flexível e configurável, com a capacidade de escrever logs em arquivos, enviar para servidores remotos, ou processar de diferentes maneiras.
O módulo logging é uma ferramenta versátil da Biblioteca Padrão do Python para rastreamento de eventos, mensagens de erro e informações de diagnóstico em suas aplicações. Ele fornece uma maneira configurável de tratar loggings de uma maneira modular e escalável. O módulo logging é uma melhoria significativa em relação à função básica print, pois oferece funcionalidades como diferentes níveis de severidade, saída de logs para múltiplos destinos, e muito mais.
Principais Componentes do Módulo logging:
- Loggers: Um "logger" é um objeto principal do módulo logging. Você cria uma instância de Logger para quase todas as tarefas de logging. Cada logger pode ter seu próprio nome, o que é útil para rastrear de onde vem uma mensagem específica de log.
- Handlers: Handlers enviam o log para o destino configurado. Diferentes handlers podem ser configurados para enviar logs para diferentes saídas, como arquivos de texto, stdout, stderr, etc. Exemplos de handlers incluem StreamHandler (para logging na console) e FileHandler (para escrever em um arquivo).
- Formatters: Os formatters especificam o layout final das mensagens de log. Você pode incluir informações como timestamp, nome do arquivo de onde o log foi gerado, nome do logger, nível de severidade da mensagem, etc.
- Levels: Os níveis de logging indicam a gravidade de um evento. Os níveis padrão incluem DEBUG, INFO, WARNING, ERROR e CRITICAL. Eles ajudam a separar os eventos menores dos mais significativos.
Configuração Básica
Para começar a usar o módulo logging, uma configuração simples pode ser realizada com logging.basicConfig(), que configura o nível de log, o formato e outros parâmetros básicos.
import logging
# Configuração básica do logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# Criando log de diferentes níveis
logging.debug('This is a debug message')
logging.info('This is an info message')
logging.warning('This is a warning message')
logging.error('This is an error message')
logging.critical('This is a critical message')Exemplo com Handlers e Formatters
Para um controle mais refinado, você pode configurar loggers, handlers e formatters explicitamente.
import logging
# Criar um logger
logger = logging.getLogger('example_logger')
logger.setLevel(logging.DEBUG)
# Criar um handler para escrever arquivos
file_handler = logging.FileHandler('example.log')
file_handler.setLevel(logging.ERROR)
# Criar um formatter
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
file_handler.setFormatter(formatter)
# Adicionar o handler ao logger
logger.addHandler(file_handler)
# Logs de exemplo
logger.debug('Isto não aparecerá no arquivo')
logger.error('Isto é uma mensagem de erro')Uso Avançado
O módulo logging pode ser configurado completamente por meio de um arquivo de configuração ou um dicionário, permitindo a separação da configuração de log da lógica da aplicação. Isso é útil em aplicações maiores, onde diferentes módulos ou componentes podem necessitar de diferentes configurações de logging.
import logging
import yaml
# Carregar o arquivo de configuração
with open('logging.yaml', 'r') as f:
config = yaml.safe_load(f)
# Configuração do logging
logging.config.dictConfig(config)
# Logs de exemplo
logging.debug('Isto não aparecerá no arquivo')
logging.error('Isto é uma mensagem de erro')Conclusão
O módulo logging é extremamente útil para qualquer aplicação de software. Ele permite monitorar o que acontece durante a execução do programa, o que é crucial para depuração e manutenção. Por ser tão flexível e poderoso, o logging é adequado para uso tanto em scripts pequenos quanto em sistemas grandes e complexos.
10.2.10 - unittest
Suporta desenvolvimento dirigido por testes com um framework de testes incluído para ajudar a escrever e rodar testes de código.
O módulo unittest é uma parte fundamental da Biblioteca Padrão do Python, oferecendo um framework de testes unitários que ajuda você a escrever e executar testes de forma sistemática. unittest foi inspirado por JUnit, um framework de testes para Java, e suporta automação de testes, compartilhamento de setup e código de desmontagem, agregação de testes em coleções e independência dos testes do código que testa.
Principais Funcionalidades
O módulo unittest fornece várias ferramentas e conceitos essenciais para escrever e executar testes:
- TestCase: A classe base TestCase é onde você define as condições individuais que o restante do seu código deve satisfazer. Um único TestCase pode incluir uma série de testes diferentes para verificar se diferentes aspectos de sua funcionalidade estão funcionando conforme esperado.
- Fixtures: unittest permite a definição de fixtures que podem ser usadas para criar um ambiente de teste desejado. Isso inclui métodos como setUp() para preparar o ambiente antes de cada teste e tearDown() para limpezas após cada teste.
- TestRunner: Um componente que coordena a execução dos testes e fornece o feedback para o usuário. O runner padrão é unittest.TextTestRunner, que reporta os resultados em texto plano.
- TestSuite: TestSuite é uma coleção de TestCases ou outras TestSuites. Isso é útil para agregar testes que devem ser executados juntos.
- Assertions: O módulo oferece uma série de métodos de asserção para verificar que determinadas condições são verdadeiras durante o teste. Isso inclui métodos como assertEqual(), assertTrue(), assertFalse(), assertRaises(), e muitos outros.
Exemplo Básico de Uso
Aqui está um exemplo simples de como usar unittest para escrever e executar um teste:
import unittest
class TestStringMethods(unittest.TestCase):
def setUp(self):
# Configurações iniciais para cada teste (opcional)
pass
def test_upper(self):
self.assertEqual('foo'.upper(), 'FOO')
def test_isupper(self):
self.assertTrue('FOO'.isupper())
self.assertFalse('Foo'.isupper())
def test_split(self):
s = 'hello world'
self.assertEqual(s.split(), ['hello', 'world'])
# Verifica se split falha quando o separador não é uma string
with self.assertRaises(TypeError):
s.split(2)
def tearDown(self):
# Limpezas após cada teste (opcional)
pass
if __name__ == '__main__':
unittest.main()Executando os Testes
Os testes podem ser executados diretamente pelo interpretador Python executando o arquivo de script.
O método unittest.main() fornece uma interface de linha de comando para o script de teste.
Você pode passar argumentos adicionais para alterar o comportamento do teste, como -v para verbose.
Considerações Adicionais
- Independência dos Testes: Cada teste deve ser independente dos outros. Isso significa que um teste não deve depender dos resultados ou do estado de outro teste.
- Cobertura de Testes: É importante tentar cobrir uma gama variada de casos, incluindo condições normais, condições de erro e casos de fronteira.
- Testes Parametrizados: Embora o unittest padrão não suporte testes parametrizados diretamente como algumas bibliotecas de terceiros (como pytest), você pode alcançar funcionalidade semelhante através de certas técnicas e extensões.
O módulo unittest é uma ferramenta extremamente poderosa e flexível para qualquer desenvolvedor Python que busca garantir que seu código permaneça correto e estável ao longo de mudanças e refatorações.
10.2.11 - random
Fornece ferramentas para gerar números pseudo-aleatórios, escolher elementos aleatórios de uma lista, ou embaralhar uma sequência.
O módulo random é uma parte integrante da Biblioteca Padrão do Python, oferecendo uma série de funções que permitem gerar números pseudoaleatórios. Esses números são úteis em vários contextos, como simulações, jogos, testes aleatórios, amostragem estatística, entre outros.
Principais Funcionalidades
O módulo random oferece diversas maneiras de gerar números aleatórios e escolher aleatoriamente elementos de uma lista.
Vamos explorar algumas das funcionalidades mais úteis deste módulo:
Geração de Números Aleatórios
- random.random(): Retorna um número de ponto flutuante entre 0.0 e 1.0.
- random.uniform(a, b): Retorna um número de ponto flutuante dentro do intervalo especificado [a, b].
Escolha e Amostragem
- random.choice(seq): Retorna um elemento aleatório de uma sequência não vazia, como uma lista.
- random.choices(seq, weights=None, k=1): Retorna uma lista com k elementos da população, podendo ser ponderada se weights for especificado.
- random.sample(population, k): Retorna uma lista de elementos únicos escolhidos da população. Útil para amostragens sem reposição.
Geração de Números Inteiros
- random.randint(a, b): Retorna um número inteiro N tal que a <= N <= b.
- random.randrange(stop) ou random.randrange(start, stop[, step]): Retorna um elemento aleatoriamente selecionado do range criado pelos argumentos start, stop e step.
Permutações
- random.shuffle(x[, random]): Embaralha a sequência x no lugar. Você pode especificar uma função de randomização customizada através do argumento random.
- random.sample(population, k): Retorna uma nova lista contendo k elementos da população, garantindo que os elementos são escolhidos sem reposição.
Exemplos de Uso
Aqui estão alguns exemplos de como você pode usar o módulo random:
import randomGeração de número flutuante aleatório entre 0 e 1:
num = random.random()
print(num)Escolha aleatória de um elemento:
items = ['apple', 'banana', 'cherry']
choice = random.choice(items)
print(choice)Gerar um inteiro dentro de um intervalo:
integer = random.randint(1, 100)
print(integer)Embaralhar uma lista
deck = ['ace', 'king', 'queen', 'jack']
random.shuffle(deck)
print(deck)Amostragem sem reposição
sample = random.sample(range(1, 100), 3)
print(sample)Considerações sobre Segurança
É importante notar que o módulo random não é seguro para uso em contextos de criptografia, pois os números gerados são pseudoaleatórios (o que significa que podem ser reproduzidos se a semente for conhecida).
Para necessidades de segurança ou criptografia, você deve usar o módulo secrets, que fornece funções para gerar números aleatórios seguros para gerenciar senhas, tokens de autenticação e outras tarefas de segurança.
Conclusão
O módulo random é uma ferramenta versátil e fácil de usar para todas as suas necessidades de geração de números pseudoaleatórios em Python. Seja para escolher aleatoriamente um item de uma lista, embaralhar dados, ou gerar amostras estatísticas, random oferece uma rica biblioteca de funções para ajudá-lo a realizar essas tarefas eficientemente.
10.2.12 - sqlite3
Implementa uma interface SQL para trabalhar com bancos de dados SQLite, permitindo a manipulação de dados sem a necessidade de um servidor de banco de dados separado.
O módulo sqlite3 é uma parte integrante da Biblioteca Padrão do Python e fornece uma interface leve de banco de dados SQL que é embutida dentro do próprio Python. Não é necessário um servidor de banco de dados separado; o banco de dados SQLite é acessado diretamente através de arquivos no sistema de arquivos local. Isso torna sqlite3 ideal para aplicações pequenas a médias, prototipagem e desenvolvimento de aplicativos que precisam de um banco de dados SQL sem a sobrecarga de operar um servidor de banco de dados completo.
Principais Funcionalidades
O módulo sqlite3 permite interagir com bancos de dados SQLite de forma eficiente e com recursos completos. Aqui estão algumas das principais funcionalidades:
- Conexão com o Banco de Dados: Para começar a trabalhar com um banco de dados SQLite, você primeiro precisa criar uma conexão. Isso é feito instanciando um objeto Connection através da função sqlite3.connect(), que abre um arquivo de banco de dados SQLite existente ou cria um novo.
- Criação de Cursor: Um objeto Cursor é usado para executar comandos SQL sobre um banco de dados aberto. Ele é essencial para realizar consultas e outras operações SQL.
- Executando Comandos SQL: O cursor permite executar comandos SQL, como CREATE, INSERT, UPDATE, DELETE, e SELECT.
- Gerenciamento de Transações: SQLite suporta transações SQL, que são gerenciadas automaticamente através do controle de contexto do Python (with statement) ou manualmente usando métodos como commit() e rollback().
- Trabalho com Dados: Você pode inserir dados, atualizar dados e recuperar resultados de consultas. O módulo sqlite3 suporta o mapeamento direto de tipos de dados Python para tipos SQL e vice-versa.
Exemplo Básico de Uso
Vamos percorrer um exemplo simples demonstrando a criação de uma tabela, inserção de dados e a consulta destes dados.
import sqlite3
# Conectar ao banco de dados SQLite
conn = sqlite3.connect('example.db')
# Criar um cursor
cur = conn.cursor()
# Criar uma tabela
cur.execute('''CREATE TABLE stocks
(date text, trans text, symbol text, qty real, price real)''')
# Inserir uma linha de dados
cur.execute("INSERT INTO stocks VALUES ('2020-01-05','BUY','RHAT',100,35.14)")
# Salvar (commit) as alterações
conn.commit()
# Realizar uma consulta
cur.execute('SELECT * FROM stocks WHERE symbol=?', ('RHAT',))
print(cur.fetchone())
# Fechar a conexão
conn.close()Considerações sobre Segurança
É importante usar a parametrização das consultas, como no exemplo acima com symbol=?, para evitar vulnerabilidades de injeção SQL.
O módulo sqlite3 suporta essa funcionalidade de maneira nativa, facilitando a escrita de código seguro.
Conclusão
O módulo sqlite3 é uma escolha excelente para projetos Python que precisam de um sistema de gerenciamento de banco de dados SQL embutido sem a necessidade de uma configuração de servidor complexa.
Ele é extremamente útil para testes, aplicações desktop, e pequenos a médios web apps onde um servidor de banco de dados completo seria um exagero.
10.2.13 - re
Oferece operações de expressões regulares para criação de padrões e análise de strings, útil para validação, correspondência, ou substituição de texto.
O módulo re é uma parte crucial da Biblioteca Padrão do Python que fornece suporte para trabalhar com expressões regulares. Expressões regulares são ferramentas poderosas para manipulação de strings, permitindo que você busque padrões complexos de caracteres em texto, uma capacidade essencial para qualquer tipo de processamento de texto ou análise de dados que envolva manipulação de strings.
Principais Funcionalidades
O módulo re permite compilar expressões regulares, buscar correspondências, substituir substrings e dividir strings com base em padrões definidos. Aqui estão algumas das principais funcionalidades e métodos oferecidos pelo módulo re:
Compilação de Expressões Regulares
- re.compile(pattern): Compila uma expressão regular em um objeto de expressão regular, que pode ser usado para busca de correspondências. Isso é útil para melhorar o desempenho quando a mesma expressão é usada várias vezes.
Busca de Correspondências
- re.match(pattern, string): Determina se o início da string corresponde ao padrão.
- re.search(pattern, string): Busca o padrão em qualquer parte da string, retornando apenas a primeira ocorrência.
- re.findall(pattern, string): Encontra todas as correspondências não-sobrepostas do padrão na string, retornando-as como uma lista de strings.
- re.finditer(pattern, string): Semelhante a findall, mas retorna um iterador produzindo objetos Match em vez de uma lista.
Substituição de Strings
- re.sub(pattern, repl, string, count=0): Substitui as ocorrências do padrão na string por repl. O parâmetro count limita o número de substituições e, se omitido, todas as ocorrências serão substituídas.
Divisão de Strings
- re.split(pattern, string, maxsplit=0): Divide a string pelas ocorrências do padrão. maxsplit controla o número máximo de divisões.
Exemplos de Uso
Aqui estão alguns exemplos práticos de como usar o módulo re:
Compilando uma expressão regular:
pattern = re.compile(r'\d+') # dígitosEncontrando todos os números em uma string:
result = pattern.findall('hello 12 hi 89')
print(result) # Output: ['12', '89']Buscando uma correspondência:
if pattern.search('hello 123'):
print("Há um número na string.")
else:
print("Nenhuma correspondência encontrada.")Substituindo palavras
replaced = re.sub(r'\bword\b', 'replacement', 'word in a word')
print(replaced) # Output: replacement in a wordDividindo uma string em cada ponto que não é uma palavra:
split_result = re.split(r'\W+', 'Words, words, words.')
print(split_result) # Output: ['Words', 'words', 'words', '']Considerações de Desempenho e Segurança
- Desempenho: Compilar a expressão regular uma vez usando re.compile() e reutilizá-la é mais eficiente, especialmente quando a mesma expressão é aplicada várias vezes.
- Segurança: Tenha cuidado ao usar re com entrada proveniente do usuário para evitar ataques de negação de serviço (DoS) em potencial, especialmente com expressões que podem levar a correspondências catastróficas de backtracking.
Conclusão
O módulo re é extremamente poderoso para tarefas que envolvem busca e manipulação de strings em Python, oferecendo uma interface rica e versátil para expressões regulares.
Seja para validação de dados, parsing, ou transformações complexas de texto, re é uma ferramenta essencial no arsenal de qualquer programador Python.
10.2.14 - subprocess
Permite a execução de novos aplicativos e processos, conecta-os a seus pipelines de entrada/saída/erro, e obtém seus códigos de retorno.
O módulo subprocess é uma ferramenta poderosa da Biblioteca Padrão do Python que permite criar novos processos, conectar-se aos seus pipes de entrada/saída/erro e obter seus códigos de retorno. Este módulo é destinado a substituir vários outros módulos e funções mais antigos, como os.system, os.spawn*, os.popen*, popen2.* e commands.*. É a maneira recomendada de invocar comandos do shell.
Principais Funcionalidades
O módulo subprocess oferece várias funcionalidades para a execução e gestão de processos externos. Aqui estão algumas das principais funcionalidades e métodos:
subprocess.run()
Este é o método recomendado para executar comandos. Ele executa o comando descrito por seus argumentos, espera que o comando seja concluído e então retorna um objeto CompletedProcess contendo informações como o código de retorno, saída padrão e erro padrão.
subprocess.Popen()
A classe Popen é o coração do módulo subprocess. Ela gera um novo processo, conecta-se a seus pipes, e retorna um objeto que permite controlar o processo e interagir com ele. Os principais métodos incluem:
- communicate(): interage com o processo, enviando dados para stdin e lendo de stdout e stderr, até a finalização do processo.
- wait(): espera pelo término do processo.
- poll(): verifica se o processo terminou.
Pipes e Redirecionamento
O subprocess permite redirecionar os pipes padrão de um processo (stdin, stdout e stderr). Por exemplo, você pode capturar a saída de um comando, redirecionar erros para um arquivo, ou ler a entrada de um arquivo.
subprocess.call() e subprocess.check_call()
Estes métodos são maneiras mais antigas de executar comandos. call() simplesmente executa o comando e retorna o código de retorno. check_call() também executa o comando, mas lança uma exceção CalledProcessError se o comando falha.
Exemplo Básico de Uso
Aqui estão alguns exemplos de como usar o módulo subprocess para executar comandos:
import subprocess
# Usando subprocess.run() para executar um comando e capturar a saída
completed = subprocess.run(['ls', '-l'], text=True, capture_output=True)
print('Return code:', completed.returncode)
print('Have {} bytes in stdout:\n{}'.format(len(completed.stdout), completed.stdout))
# Executando um comando e capturando erros
try:
subprocess.check_call(['false']) # Este comando falha intencionalmente
except subprocess.CalledProcessError as e:
print('Erro:', e)
# Usando Popen para mais controle
process = subprocess.Popen(['sleep', '1'], stdout=subprocess.PIPE, stderr=subprocess.PIPE)
stdout, stderr = process.communicate()
print('Process finished with code', process.returncode)
print('Have {} bytes in stdout:\n{}'.format(len(stdout), stdout))
print('Have {} bytes in stderr:\n{}'.format(len(stderr), stderr))Considerações de Segurança
Ao usar o subprocess, é crucial ser cuidadoso com a entrada proveniente de fontes externas. Usar subprocess.run() ou Popen com shell=True pode ser perigoso se os argumentos forem construídos a partir de entradas externas devido ao risco de injeção de shell. Sempre prefira passar os argumentos do comando como uma lista em vez de uma única string e evite shell=True quando possível.
Conclusão
O módulo subprocess é extremamente útil para executar e gerenciar processos externos em aplicações Python. Ele oferece uma interface rica e flexível que pode lidar com quase todas as situações onde você precisa interagir com comandos e processos do sistema operacional.
10.3 - Pacotes de Terceiros
Quando trabalhamos com desenvolvimento em Python, uma das grandes vantagens é a vasta biblioteca de pacotes disponíveis que podem ser facilmente instalados e gerenciados com o pip, o gerenciador de pacotes do Python.
Esses pacotes oferecem funcionalidades adicionais que vão desde a manipulação de dados e visualização até o desenvolvimento web e machine learning, expandindo enormemente o escopo do que pode ser feito com relativa facilidade utilizando Python.
Muitos desses pacotes de terceiros são construídos sobre bibliotecas altamente otimizadas escritas em linguagens de programação como C, o que lhes confere um desempenho excepcional.
Por exemplo, pacotes populares como NumPy e Pandas utilizam componentes em C para manipulação de dados numéricos e arrays, o que acelera significativamente as operações de computação intensiva que são comuns em ciência de dados e análise numérica.
A capacidade de combinar a simplicidade e facilidade de uso do Python com o desempenho das linguagens compiladas como C é uma das razões pelas quais Python é tão popular em campos que exigem intensa manipulação de dados e cálculos matemáticos.
Além disso, essa integração entre Python e código em C se estende além dos pacotes voltados para dados.
Bibliotecas de processamento de imagens como OpenCV, bibliotecas de gráficos como Matplotlib e frameworks de aprendizado de máquina como TensorFlow também utilizam extensões em C para melhorar o desempenho.
Essa arquitetura híbrida permite aos desenvolvedores aproveitar tanto a alta produtividade e legibilidade do Python quanto a eficiência e velocidade do C, tornando possível o desenvolvimento de aplicações poderosas e eficientes com relativa facilidade.
Algumas das bibliotecas mais populares e úteis do ecossistema Python, disponíveis através do gerenciador de pacotes pip.
- NumPy
- Pandas
- Matplotlib
- Seaborn
- Plotly
- Scikit-learn
- Scipy
- TensorFlow
- OpenCV
- PyTorch
- PySpark
- DJango
- Flask
Cada uma dessas bibliotecas serve a propósitos específicos e é fundamental em diversas áreas da ciência de dados, visualização de dados, matemática e muito mais.
10.3.1 - NumPy
Descrição: NumPy é uma biblioteca fundamental para computação científica em Python. Ela oferece suporte para grandes arrays e matrizes multidimensionais, juntamente com uma vasta coleção de funções matemáticas de alto nível para operar nessas estruturas de dados.
Usos Comuns: NumPy é extensivamente usado em tarefas que requerem operações matemáticas intensivas e manipulação de dados numéricos, como transformações lineares, cálculos estatísticos, e processamento de imagens.
NumPy é uma das bibliotecas mais fundamentais para computação numérica em Python. Sua capacidade de trabalhar eficientemente com arrays multidimensionais, juntamente com uma coleção abrangente de funções matemáticas, faz dela uma ferramenta indispensável para cientistas de dados, engenheiros e qualquer pessoa que precise realizar operações matemáticas complexas de forma eficiente.
Funcionalidades Principais
- Arrays Multidimensionais: NumPy introduz um poderoso objeto de array N-dimensional chamado ndarray. Esses arrays são mais eficientes do que as listas Python padrão, especialmente quando você está trabalhando com grandes volumes de dados, devido ao armazenamento de dados contíguo na memória e operações vetorizadas que são aplicadas diretamente em C.
- Operações Matemáticas e Estatísticas: NumPy oferece uma vasta gama de funções matemáticas para operações com arrays que incluem operações aritméticas básicas (adição, subtração, multiplicação, etc.), operações complexas (trigonometria, exponencial e logaritmo), e estatísticas (média, mediana, desvio padrão, etc.). Essas operações são altamente otimizadas e podem ser realizadas diretamente sobre arrays NumPy sem a necessidade de loops explícitos em Python.
- Álgebra Linear: NumPy possui suporte embutido para operações de álgebra linear, como multiplicação de matrizes, decomposições, determinantes e outras funcionalidades encontradas em submódulos como numpy.linalg.
- Integração com outras bibliotecas: NumPy é extremamente integrável com outras bibliotecas de análise de dados em Python, servindo como a espinha dorsal para outras bibliotecas como Pandas, SciPy, Matplotlib, scikit-learn, e mais. Isso permite que dados possam ser facilmente transferidos entre diferentes bibliotecas e frameworks de dados sem a necessidade de conversão.
Exemplo de Uso Básico
Aqui está um exemplo simples demonstrando como criar arrays NumPy e realizar algumas operações básicas:
import numpy as np
# Criando um array NumPy
a = np.array([1, 2, 3, 4, 5])
# Operações matemáticas simples
print("Array original:", a)
print("Adicionando 5:", a + 5)
print("Multiplicando por 2:", a * 2)
# Funções matemáticas
print("Exponencial:", np.exp(a))
print("Seno:", np.sin(a))
# Estatísticas
print("Média:", np.mean(a))
print("Máximo:", np.max(a))
# Álgebra linear
b = np.array([[1, 2], [3, 4]])
c = np.array([[2, 0], [1, 2]])
print("Produto de matrizes:\n", np.dot(b, c))Desempenho
A eficiência do NumPy vem de sua implementação em C e Fortran, o que permite que operações intensivas sejam executadas em dados armazenados em arrays NumPy muito mais rápido do que seria possível com as listas Python padrão. Além disso, a vetorização permite que operações sejam aplicadas diretamente a arrays inteiros, evitando o custo de loops e outras estruturas de controle Python.
Conclusão
NumPy é uma ferramenta essencial para programação científica com Python.
Seja para análise de dados, engenharia ou qualquer campo que necessite de computação numérica, NumPy oferece uma plataforma robusta e flexível que integra perfeitamente com o ecossistema mais amplo de ciência de dados em Python.
10.3.2 - Pandas
Descrição: Pandas é uma biblioteca de manipulação e análise de dados que oferece estruturas de dados e operações para manipular tabelas numéricas e séries temporais. É particularmente útil para manipulação e limpeza de dados.
Usos Comuns: Muito usado em data science e finanças para análise de dados, incluindo manipulação de séries temporais, dados econômicos, e muito mais.
Pandas é uma biblioteca de código aberto, poderosa e flexível para análise e manipulação de dados em Python. Projetada para trabalhar com estruturas de dados "relacionais" ou "rotuladas" de forma intuitiva, Pandas é uma ferramenta indispensável em ciência de dados, oferecendo funcionalidades robustas para manipulação de dados estruturados de maneira eficiente e eficaz.
Funcionalidades Principais
Pandas introduz duas novas estruturas de dados para Python: DataFrame e Series, ambas construídas sobre o NumPy, tornando-as rápidas e eficientes.
- DataFrame: Uma estrutura de dados tabular bidimensional com rótulos nas linhas e colunas. Semelhante a uma planilha, uma tabela SQL, ou um dicionário de objetos Series. É a principal estrutura de dados do Pandas e é diretamente inspirada pela estrutura de dados data.frame do R.
- Series: Uma estrutura de dados unidimensional capaz de armazenar qualquer tipo de dados com rótulos ou índice de eixo. Cada coluna em um DataFrame é uma Series.
Manipulação de Dados:
- Leitura e Escrita de Dados: Pandas suporta o carregamento de dados de uma variedade de formatos de arquivos incluindo CSV, Excel, SQL databases, JSON e HDF5, tornando a importação e exportação de dados uma tarefa simples e direta.
- Limpeza de Dados: Oferece várias maneiras de lidar com dados faltantes, remover duplicatas, e transformar dados com base em condições específicas.
- Transformação de Dados: Inclui operações como agrupamentos (groupby), pivotamento (pivot_table), e a construção de tabelas cruzadas (crosstab).
- Fusão e Junção de Dados: Permite combinar diferentes conjuntos de dados de maneira eficiente usando operações de junção e concatenação ao estilo de bancos de dados.
Análise de Dados:
- Estatísticas Descritivas: Pandas proporciona funções para calcular médias, medianas, modas, variações, correlações, quantis e outras estatísticas descritivas.
- Manipulação de Séries Temporais: Suporta datas e intervalos de datas de maneira nativa, permitindo a análise de séries temporais de forma eficaz.
Exemplo de Uso Básico
Aqui está um exemplo simples que demonstra algumas das operações básicas que você pode realizar com Pandas:
import pandas as pd
# Criando um DataFrame a partir de um dicionário de listas
data = {
'Name': ['John', 'Anna', 'Peter', 'Linda'],
'Age': [28, 22, 34, 42],
'City': ['New York', 'Paris', 'Berlin', 'London']
}
df = pd.DataFrame(data)
# Mostrando as primeiras linhas do DataFrame
print(df.head())
# Selecionando uma coluna específica
print(df['Age'])
# Filtrando dados
print(df[df['Age'] > 30])
# Adicionando uma nova coluna
df['Senior'] = df['Age'] > 35
print(df)Desempenho
Pandas é altamente otimizado para performance, com partes críticas do código escritas em Cython ou C. No entanto, para conjuntos de dados extremamente grandes (na ordem de milhões de linhas), ainda pode enfrentar problemas de desempenho e eficiência de memória. Para esses casos, ferramentas como Dask ou Vaex podem ser consideradas para trabalhar de forma eficiente com grandes volumes de dados.
Conclusão
Pandas é uma das bibliotecas mais essenciais em Python para análise de dados, proporcionando poderosas ferramentas para manipulação e visualização de dados complexos. Com sua ampla variedade de funcionalidades e fácil integração com outras bibliotecas de análise de dados como NumPy e SciPy, Pandas é uma ferramenta indispensável para qualquer cientista de dados ou analista que trabalhe com dados em Python.
10.3.3 - Matplotlib
Descrição: Matplotlib é uma biblioteca de plotagem para a linguagem de programação Python e sua extensão numérica matemática NumPy. Ela fornece uma API orientada a objetos para incorporar gráficos em aplicações usando toolkits GUI genéricos, como Tkinter, wxPython, Qt ou GTK.
Usos Comuns: É amplamente utilizada para fazer gráficos e visualizações de dados de todos os tipos, com suporte para uma grande variedade de gráficos estáticos, animados e interativos.
Matplotlib é uma biblioteca de plotagem para Python que oferece uma variedade de ferramentas para produzir figuras estáticas, animadas e interativas em uma ampla gama de formatos. É uma das bibliotecas de visualização de dados mais populares e amplamente utilizadas na comunidade Python, essencial para quem precisa criar visualizações científicas, engenharia ou qualquer tipo de gráficos de dados.
Funcionalidades Principais
versatilidade na plotagem
Matplotlib é extremamente versátil, permitindo a criação de uma ampla variedade de gráficos, incluindo:
- Gráficos de linhas e gráficos de barras para análise de tendências.
- Histogramas para análise de distribuições.
- Gráficos de dispersão para observar relações e agrupamentos.
- Gráficos de pizza para mostrar proporções de categorias.
- Gráficos de erro e caixas de bigode para estatísticas.
- Mapas de calor e gráficos de contorno para visualizações de dados bidimensionais.
- Gráficos de superfície 2D e 3D para visualizações de dados tridimensionais.
Personalização Completa
Quase todos os elementos de uma figura podem ser personalizados no Matplotlib, incluindo tamanhos de figuras, cores, tipos de fonte, layouts de gráficos, e muito mais. Isso permite que o usuário adapte as visualizações para se ajustarem perfeitamente às necessidades de sua apresentação ou relatório.
Integração com NumPy
Matplotlib é construído sobre o NumPy, o que significa que ele funciona bem com arrays NumPy. Esta integração facilita o manuseio e a transformação de dados durante o processo de plotagem.
Interface Orientada a Objetos e Pyplot
Matplotlib oferece duas interfaces:
- Orientada a objetos: É a interface recomendada para criação de gráficos complexos e mais personalizados. Ela oferece controle explícito sobre figuras, eixos e widgets.
- Pyplot: Modelada em comandos MATLAB, a interface pyplot é mais simples e boa para scripts e interações rápidas. É particularmente útil para usuários que estão familiarizados com o MATLAB.
Exemplo de Uso Básico
Aqui está um exemplo básico que ilustra como criar um gráfico simples com Matplotlib:
import matplotlib.pyplot as plt
import numpy as np
# Dados para plotagem
x = np.linspace(0, 10, 100)
y = np.sin(x)
# Criando uma figura e um eixo
fig, ax = plt.subplots()
# Plotando os dados
ax.plot(x, y, label='Seno de x')
# Adicionando título e legendas
ax.set_title('Gráfico Simples com Matplotlib')
ax.set_xlabel('x')
ax.set_ylabel('sin(x)')
ax.legend()
# Mostrando o gráfico
plt.show()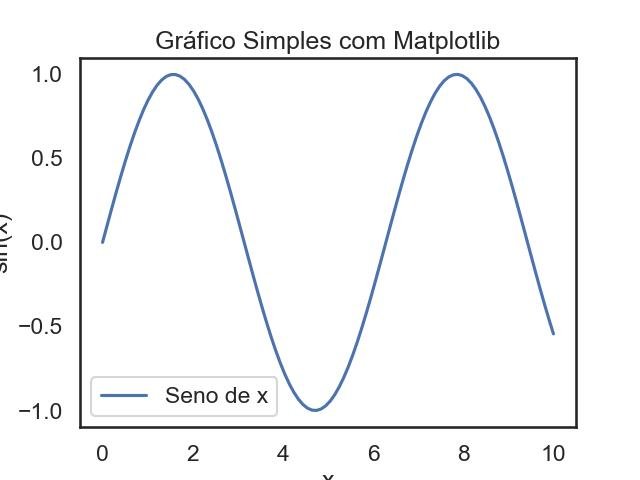
Gráficos Avançados e Personalização
Matplotlib permite ir além dos gráficos básicos para criar visualizações complexas e altamente personalizadas, como gráficos 3D, gráficos em rede e animações. Além disso, o Matplotlib pode ser usado em conjunto com bibliotecas como seaborn para estilos de plotagem estatísticos e pandas para manipulação de dados, melhorando ainda mais as capacidades de visualização.
Conclusão
Matplotlib é uma ferramenta extremamente poderosa para visualização de dados em Python. Seu design robusto e flexível torna possível para cientistas, engenheiros e analistas de dados visualizar complexas relações nos dados de forma clara e compreensível. Mesmo com a existência de bibliotecas de plotagem mais novas e talvez mais atraentes visualmente, Matplotlib continua sendo uma peça fundamental do kit de ferramentas de visualização de dados devido à sua estabilidade e capacidade de ser altamente personalizável.
10.3.4 - Seaborn
Descrição: Seaborn é uma biblioteca de visualização de dados baseada em Matplotlib que oferece uma interface de alto nível para desenhar gráficos estatísticos atrativos e informativos.
Usos Comuns: Frequentemente usado para visualizações de dados mais avançadas, especialmente gráficos que envolvem relações entre múltiplas variáveis.
Seaborn é uma biblioteca de visualização de dados em Python que fornece uma interface de alto nível para a criação de gráficos estatísticos atraentes. Seaborn é construída sobre o Matplotlib e integra-se bem com as estruturas de dados do Pandas. É particularmente adequada para visualizações que envolvem a exploração e apresentação de dados complexos de forma intuitiva e informativa.
Funcionalidades Principais
Fácil de Usar
Seaborn simplifica a criação de muitos tipos de gráficos com uma API simples e concisa. A biblioteca cuida de muitos detalhes de implementação, permitindo aos usuários criar visualizações complexas com comandos relativamente simples.
Estilos e Temas
A biblioteca fornece uma série de estilos e temas predefinidos que podem ser facilmente aplicados aos gráficos, garantindo que eles sejam tanto esteticamente agradáveis quanto fáceis de entender. Além disso, permite ajustes finos para personalização completa dos gráficos.
Tipos de Gráficos
Seaborn é especialmente forte em gráficos que revelam relações entre múltiplas variáveis, incluindo:
- Gráficos de dispersão (scatter plots)
- Gráficos de linha (line plots)
- Histogramas e gráficos de densidade
- Gráficos de caixa (box plots) e violin plots
- Mapas de calor (heatmaps)
- Gráficos de correlação
- Gráficos de pares (pair plots) e matrizes de correlação
- Gráficos de barras e gráficos de contagem (count plots)
- Facetamento
Seaborn suporta o facetamento, que permite explorar padrões em múltiplos subconjuntos dos dados criando uma matriz de gráficos baseados nas mesmas variáveis.
Isso é feito facilmente com FacetGrid ou pairplot.
Exemplo de Uso Básico
Aqui está um exemplo simples demonstrando como criar um gráfico de dispersão com histogramas marginais usando Seaborn:
import seaborn as sns
import matplotlib.pyplot as plt
# Carregar um dataset de exemplo
tips = sns.load_dataset("tips")
# Criar um gráfico de dispersão com histogramas marginais
sns.jointplot(x="total_bill", y="tip", data=tips, kind="scatter")
# Mostrar o gráfico
plt.show()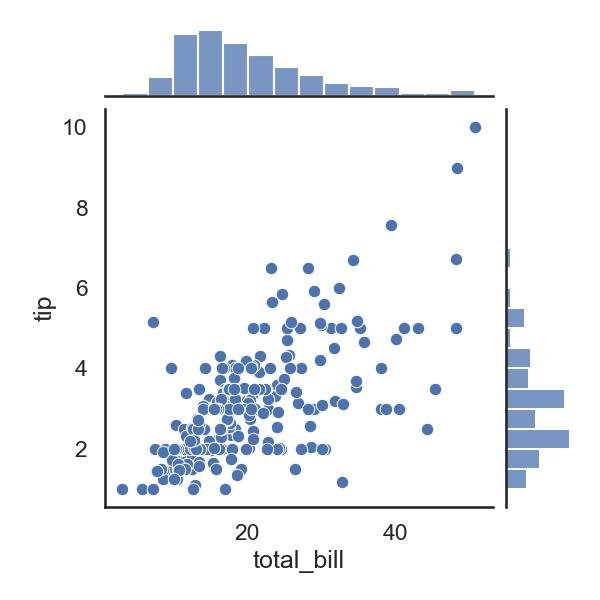
Visualizações Avançadas
Seaborn facilita a criação de visualizações complexas que seriam relativamente complicadas de implementar usando apenas Matplotlib.
Por exemplo, criar uma matriz de gráficos que mostra as relações entre várias variáveis ou visualizar a distribuição de dados multidimensionais.
Integração com Pandas
A integração do Seaborn com o Pandas torna mais fácil trabalhar diretamente com DataFrames, simplificando a manipulação de dados e a plotagem. Isso permite que você passe diretamente objetos do Pandas para funções de plotagem do Seaborn, que podem utilizar nomes de colunas do DataFrame para mapear variáveis para eixos, cores ou facetas.
Conclusão
Seaborn é uma ferramenta poderosa e essencial para a visualização estatística em Python, permitindo aos analistas criar rapidamente uma variedade de gráficos informativos e atraentes.
Com sua sintaxe simplificada e poderosa capacidade de visualização, Seaborn ajuda a transformar dados brutos em insights compreensíveis, com menos código e maior eficácia visual.
10.3.5 - SciPy
Descrição: SciPy é uma biblioteca que usa NumPy para fazer matemática científica e técnica. Ela inclui módulos para otimização, álgebra linear, integração numérica, interpolação, FFT, processamento de sinal, e muito mais.
Usos Comuns: É essencial para tarefas científicas e técnicas que requerem cálculos numéricos precisos e complexos, como modelagem e simulação, otimização de problemas, e análise de dados experimentais.
SciPy é uma biblioteca central no ecossistema de computação científica em Python, oferecendo uma vasta coleção de algoritmos matemáticos e funções de engenharia. É construída sobre o NumPy, o que significa que se integra bem com essa biblioteca para oferecer uma eficiente manipulação de arrays e matrizes. O SciPy é fundamental para tarefas que envolvem otimização, álgebra linear, integração, interpolação, transformadas especiais, processamento de sinais, e muito mais.
Principais Funcionalidades
Otimização
scipy.optimize: Fornece algoritmos para otimização de funções, incluindo minimização de escalares ou multivariáveis, ajuste de curvas e busca de raízes. Essas ferramentas são úteis em várias aplicações científicas e de engenharia onde a maximização ou minimização de funções é crucial.
AÁlgebra Linear
scipy.linalg: Oferece todas as funcionalidades de álgebra linear que estão além das fornecidas pelo NumPy. Isso inclui decomposições de matrizes, solvers de sistemas lineares, e outras operações matriciais avançadas. Este submódulo é mais abrangente e otimizado do que o equivalente do NumPy.
Processamento de Sinais
scipy.signal: Suporta processamento de sinais, incluindo filtragem de sinais, construção de filtros, análise de frequência, e muito mais. É essencial para engenheiros e cientistas que trabalham com sistemas de comunicação, processamento de áudio, e outras aplicações relacionadas a sinais.
Cálculo Numérico
scipy.integrate: Fornece várias técnicas de integração, tanto de funções definidas por equações quanto de dados experimentais. Inclui integração numérica e solução de equações diferenciais.
scipy.interpolate: Oferece uma ampla variedade de métodos de interpolação, que são extremamente úteis para preencher dados faltantes ou fazer estimativas baseadas em conjuntos de dados existentes.
Estatísticas
scipy.stats: Contém uma grande coleção de distribuições de probabilidade e uma biblioteca de funções estatísticas, que inclui descrições estatísticas, testes estatísticos e correlações. É uma ferramenta valiosa para análise estatística em pesquisas e ciências experimentais.
Transformadas Especiais
scipy.special: Fornece funções matemáticas especiais, como funções Bessel, funções elípticas, gama e beta, etc. Essas são comumente usadas em soluções analíticas de problemas em física e engenharia.
Exemplo de Uso Básico
Aqui está um exemplo simples que demonstra como resolver um sistema de equações lineares usando SciPy:
from scipy.linalg import solve
import numpy as np
# Definindo a matriz dos coeficientes e o vetor de constantes
a = np.array([[3, 1], [1, 2]])
b = np.array([9, 8])
# Resolvendo o sistema de equações lineares
x = solve(a, b)
print("Solução do sistema:", x)Integração e Expansibilidade
SciPy é uma das bibliotecas mais importantes para qualquer pessoa que trabalha com matemática, ciência ou engenharia no Python.
Ela é projetada para trabalhar eficientemente com as estruturas de dados NumPy e integrar-se perfeitamente com todas as outras bibliotecas científicas e de análise de dados em Python, como Matplotlib para visualização, Pandas para manipulação de dados, e bibliotecas de aprendizado de máquina como scikit-learn.
Conclusão
SciPy é uma biblioteca extensiva que serve como a pedra angular para uma ampla gama de aplicações científicas e técnicas em Python.
Seu conjunto abrangente de módulos e funcionalidades permite a execução eficiente de tarefas que vão desde simples cálculos matemáticos até análises complexas e modelagem avançada, tornando-a indispensável para profissionais e pesquisadores nas áreas de ciência e engenharia.
10.3.6 - Scikit-Learn
Descrição: Scikit-Learn é uma biblioteca simples e eficiente para mineração de dados e análise de dados, acessível a todos e reutilizável em vários contextos.
Usos Comuns: Amplamente utilizada em machine learning para classificação, regressão, clustering e redução de dimensionalidade, incluindo utilitários para pré-processamento de dados, validação cruzada e muito mais.
scikit-learn é uma das bibliotecas mais populares e poderosas para aprendizado de máquina (machine learning) em Python.
Ela oferece uma vasta gama de ferramentas eficientes e fáceis de usar para mineração de dados e análise de dados, incluindo algoritmos de classificação, regressão, clustering e redução de dimensionalidade.
Scikit-learn é construído sobre NumPy, SciPy e Matplotlib, garantindo uma integração perfeita com o ecossistema científico de Python.
Principais Funcionalidades
Algoritmos de Classificação
K-Nearest Neighbors (KNN): Simples e eficaz, usado para classificação baseada na proximidade dos dados.
Support Vector Machines (SVM): Algoritmo poderoso para problemas de classificação e regressão, particularmente eficaz em espaços de alta dimensão.
Decision Trees e Random Forests: Úteis para classificação e regressão com a capacidade de modelar relações não lineares.
Algoritmos de Regressão
Linear Regression: Modelo básico para prever valores contínuos.
Ridge e Lasso Regression: Versões aprimoradas da regressão linear que incluem regularização para evitar overfitting.
Polynomial Regression: Extensão da regressão linear para incluir termos polinomiais.
Algoritmos de Clustering
K-Means: Método popular para agrupar pontos de dados em K clusters.
Hierarchical Clustering: Algoritmo que constrói uma hierarquia de clusters.
DBSCAN: Algoritmo de clustering baseado em densidade, robusto a ruído e capaz de encontrar clusters de forma arbitrária.
Redução de Dimensionalidade
Principal Component Analysis (PCA): Técnica estatística que transforma variáveis correlacionadas em um conjunto menor de variáveis não correlacionadas.
Linear Discriminant Analysis (LDA): Método supervisionado de redução de dimensionalidade.
t-Distributed Stochastic Neighbor Embedding (t-SNE): Técnica para visualização de dados de alta dimensão em um espaço de menor dimensão.
Pré-processamento de Dados
StandardScaler e MinMaxScaler: Ferramentas para normalizar e padronizar dados.
OneHotEncoder: Para transformar variáveis categóricas em uma representação numérica.
Imputer: Para preencher valores faltantes em conjuntos de dados.
Validação Cruzada e Seleção de Modelos
Cross-Validation: Métodos como K-Fold e Stratified K-Fold para avaliar a robustez de um modelo.
GridSearchCV e RandomizedSearchCV: Ferramentas para otimizar hiperparâmetros de modelos de forma eficiente.
Exemplo de Uso Básico
Aqui está um exemplo simples que demonstra como usar scikit-learn para treinar e avaliar um modelo de classificação usando o dataset de íris:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# Carregar o dataset
iris = load_iris()
X, y = iris.data, iris.target
# Dividir os dados em conjuntos de treino e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Normalizar os dados
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Treinar um modelo SVM
model = SVC(kernel='linear')
model.fit(X_train, y_train)
# Fazer previsões
y_pred = model.predict(X_test)
# Avaliar a precisão do modelo
acuracia = accuracy_score(y_test, y_pred)
print(f'Acuracia: {acuracia:.2f}')Integração com Outras Bibliotecas
Scikit-learn se integra facilmente com outras bibliotecas do ecossistema Python. Por exemplo, Pandas pode ser usado para manipulação de dados, Matplotlib e Seaborn para visualização, e NumPy para operações numéricas. Esta integração permite um fluxo de trabalho eficiente e simplificado para projetos de aprendizado de máquina.
Conclusão
Scikit-learn é uma biblioteca essencial para qualquer pessoa interessada em aprendizado de máquina e análise de dados. Sua facilidade de uso, combinada com uma vasta gama de algoritmos e ferramentas, a torna uma escolha ideal para tarefas que variam desde projetos acadêmicos e prototipagem até aplicações industriais e pesquisa avançada. A comunidade ativa e a excelente documentação fazem do scikit-learn uma ferramenta indispensável no kit de ferramentas de qualquer cientista de dados ou engenheiro de machine learning.
10.3.7 - TensorFlow
- Descrição: TensorFlow, desenvolvido pelo Google, e PyTorch, desenvolvido pelo Facebook, são frameworks que permitem a construção de redes neurais para deep learning. Ambos fornecem extensas funcionalidades para a criação, treinamento e validação de modelos de aprendizado profundo com suporte a execução em CPUs e GPUs.
- Usos Comuns: Usados para uma variedade de aplicações em deep learning, incluindo visão computacional, processamento de linguagem natural e pesquisa em inteligência artificial.
TensorFlow é uma biblioteca de código aberto para computação numérica e aprendizado de máquina desenvolvida pelo Google.
Ela fornece uma ampla gama de ferramentas e bibliotecas para construir e treinar modelos de aprendizado de máquina e redes neurais profundas.
TensorFlow é amplamente utilizado para pesquisa e produção em várias aplicações, incluindo visão computacional, processamento de linguagem natural, reconhecimento de fala e muito mais.
Principais Funcionalidades
Computação em Grafo
- Grafos Computacionais: TensorFlow utiliza um modelo baseado em grafos para representar a computação. Os nós do grafo representam operações matemáticas, enquanto as arestas representam os dados (tensores) que são passados entre essas operações.
- Eager Execution: Permite a execução imediata de operações, sem a necessidade de construir um grafo computacional, facilitando a depuração e a construção de modelos iterativamente.
Tensores
- Tensores: São a estrutura de dados fundamental em TensorFlow. Um tensor é uma matriz multidimensional que pode ser usada para representar dados em diferentes dimensões (escalar, vetor, matriz, etc.).
Keras API
- Keras: TensorFlow incorpora o Keras, uma API de alto nível para construir e treinar modelos de aprendizado de máquina. Keras simplifica a criação de modelos de redes neurais com uma interface fácil de usar e flexível.
import tensorflow as tf
from tensorflow.keras import layers
model = tf.keras.Sequential([
layers.Dense(64, activation='relu', input_shape=(784,)),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['acuracia'])Treinamento e Avaliação
- Treinamento de Modelos: TensorFlow fornece várias funções para treinar modelos, ajustar hiperparâmetros, e validar modelos. model.fit() é usado para treinar o modelo em dados de treinamento.
- Callback Functions: Permitem personalizar e controlar o processo de treinamento (como salvar checkpoints do modelo, ajustar a taxa de aprendizado dinamicamente, etc.).
Distribuição e Desempenho
- Execução Distribuída: TensorFlow suporta a execução distribuída de modelos em várias GPUs, TPUs e servidores, permitindo o treinamento eficiente de grandes modelos de aprendizado profundo em grande escala.
- XLA (Accelerated Linear Algebra): Um compilador específico do TensorFlow que otimiza as operações computacionais para melhorar o desempenho.
Modelos Pré-Treinados e Transfer Learning
- Modelos Pré-Treinados: TensorFlow Hub oferece uma coleção de modelos pré-treinados que podem ser facilmente utilizados para transfer learning, permitindo treinar novos modelos com dados limitados.
- Transfer Learning: Permite adaptar modelos existentes a novos problemas, economizando tempo e recursos de computação.
Exemplos de Uso
Aqui está um exemplo simples de construção, compilação e treinamento de um modelo de classificação de imagens usando a API Keras em TensorFlow:
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
# Carregar e preparar o dataset CIFAR-10
(x_train, y_train), (x_test, y_test) = datasets.cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# Construir o modelo
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10)
])
# Compilar o modelo
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['acuracia'])
# Treinar o modelo
model.fit(x_train, y_train, epochs=10,
validation_data=(x_test, y_test))
# Avaliar o modelo
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print(f'\nTest acuracia: {test_acc}')Integração com Outras Ferramentas
TensorFlow se integra bem com outras ferramentas do ecossistema de aprendizado de máquina, como:
- TensorBoard: Ferramenta de visualização para monitorar experimentos, visualizando gráficos computacionais, métricas de desempenho, e outras estatísticas.
- TFX (TensorFlow Extended): Uma plataforma end-to-end para a produção de modelos de aprendizado de máquina.
- TensorFlow Lite: Ferramenta para a inferência em dispositivos móveis e embarcados.
- TensorFlow.js: Biblioteca para executar modelos TensorFlow em JavaScript, permitindo o uso de modelos em navegadores da web.
Conclusão
TensorFlow é uma ferramenta robusta e versátil para desenvolvimento e implementação de modelos de aprendizado de máquina. Sua ampla gama de funcionalidades, juntamente com sua capacidade de escalar e integrar-se a outras ferramentas, o torna uma escolha ideal tanto para pesquisa quanto para produção em larga escala.
Seja para prototipagem rápida ou para construir modelos complexos de deep learning, TensorFlow oferece a flexibilidade e o poder necessários para enfrentar desafios modernos de aprendizado de máquina.
10.3.8 - PyTorch
- Descrição: O PyTorch, desenvolvido pelo Facebook, é um frameworks que permite a construção de redes neurais para deep learning, fornecendo extensas funcionalidades para a criação, treinamento e validação de modelos de aprendizado profundo com suporte a execução em CPUs e GPUs.
- Usos Comuns: Usados para uma variedade de aplicações em deep learning, incluindo visão computacional, processamento de linguagem natural e pesquisa em inteligência artificial.
PyTorch é uma biblioteca de aprendizado de máquina de código aberto desenvolvida principalmente pelo Facebook's AI Research lab (FAIR). É amplamente utilizada por pesquisadores e engenheiros devido à sua facilidade de uso, flexibilidade e capacidades robustas para construir e treinar redes neurais. PyTorch é conhecido por sua abordagem dinâmica de computação em grafos e forte suporte para treinamento em GPUs, tornando-o ideal para aplicações de deep learning e pesquisa.
Principais Funcionalidades
Tensores
- Tensors: São a unidade básica de dados em PyTorch, similar a arrays do NumPy, mas com suporte adicional para operações em GPUs. Tensores podem ser facilmente convertidos de e para arrays NumPy.
import torch
# Criação de um tensor
x = torch.tensor([[1, 2, 3], [4, 5, 6]])
# Impressão do tensor
print(x)Autograd (Diferenciação Automática)
- Autograd: Permite a diferenciação automática de todas as operações em tensores, facilitando a construção e treinamento de redes neurais. Cada operação com tensores é rastreada para construir um gráfico computacional dinâmico, permitindo calcular gradientes automaticamente.
# Criação de um tensor com requires_grad=True para calcular gradientes
x = torch.tensor([[2.0, 3.0]], requires_grad=True)
y = x + 2
z = y * y * 3
# Calculando o gradiente
z.backward(torch.tensor([[1.0, 1.0]]))
print(x.grad)nn.Module e nn.Functional
nn.Module: A classe base para todas as redes neurais em PyTorch. Definir modelos de rede como subclasses de nn.Module permite aproveitar recursos como registro de parâmetros, métodos de forward e backward.
nn.Functional: Oferece operações funcionais para a construção de redes neurais, como funções de ativação, convoluções, pooling, etc.
import torch.nn as nn
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(784, 128)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return xOptimização
- torch.optim: Oferece vários otimizadores como SGD, Adam, RMSprop, que são usados para ajustar os pesos dos modelos de redes neurais durante o treinamento.
model = SimpleNN()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# Criação de dados de treinamento
inputs = torch.randn(100, 784)
targets = torch.randint(0, 10, (100,))
# Criação de DataLoader
trainloader = torch.utils.data.DataLoader(
torch.utils.data.TensorDataset(inputs, targets), batch_size=10, shuffle=True
)
# Criação da função de perda
criterion = nn.CrossEntropyLoss()
# Criação do loop de treinamento
epochs = 10
# Loop de treinamento
for epoch in range(epochs):
optimizer.zero_grad() # Zerar gradientes
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward() # Backpropagation
optimizer.step() # Atualização dos pesos
print(f"Epoch {epoch+1}/{epochs}, Loss: {loss.item():.4f}")
# Avaliação do modelo
with torch.no_grad():
outputs = model(inputs)
_, predicao = torch.max(outputs.data, 1)
acuracia = (predicao == targets).sum().item() / targets.size(0)
print(f"Acuracia: {acuracia:.4f}")Salvando e Carregando o modelo
- torch.save(): Salva o estado do modelo em um arquivo binaário.
- torch.load(): Carrega o estado do modelo de um arquivo binaário.
# Salvando o modelo
torch.save(model.state_dict(), "model.pth")
# Carregando o modelo
model = SimpleNN()
model.load_state_dict(torch.load("model.pth"))
# Avaliação do modelo carregado
with torch.no_grad():
outputs = model(inputs)
_, predicao = torch.max(outputs.data, 1)
acuracia = (predicao == targets).sum().item() / targets.size(0)
print(f"Acuracia: {acuracia:.4f}")Treinamento em GPU
- torch.cuda: Permite o uso de GPUs para acelerar o treinamento de modelos. Tensores e modelos podem ser movidos para a GPU usando .to('cuda') ou .cuda().
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = SimpleNN().to(device)
inputs = inputs.to(device)Exemplo de Uso
Aqui está um exemplo simples de construção e treinamento de um modelo de rede neural em PyTorch para classificação:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
# Definindo transformações para os dados de entrada
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
# Carregando dataset MNIST
trainset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
# Definindo uma rede neural simples
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(28*28, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = x.view(-1, 28*28)
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# Inicializando o modelo, critério de perda e otimizador
model = SimpleNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# Treinando o modelo
for epoch in range(5):
for inputs, targets in trainloader:
# Zerar os gradientes
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
loss = criterion(outputs, targets)
# Backward pass
loss.backward()
# Atualizar os parâmetros
optimizer.step()
print(f'Epoch {epoch+1}, Loss: {loss.item()}')Integração com Outras Ferramentas
PyTorch se integra bem com outras ferramentas do ecossistema de aprendizado de máquina e deep learning, como:
- TorchVision: Uma biblioteca para visão computacional que fornece conjuntos de dados, modelos pré-treinados e transformações comuns.
- TensorBoard: Para visualização de gráficos computacionais e métricas de treinamento.
- ONNX (Open Neural Network Exchange): Permite exportar modelos PyTorch para serem usados em outras plataformas compatíveis com ONNX.
Conclusão
PyTorch é uma biblioteca poderosa e flexível que oferece todas as ferramentas necessárias para pesquisa e desenvolvimento em aprendizado de máquina e deep learning.
Sua abordagem dinâmica e intuitiva para construção de grafos computacionais, juntamente com um forte suporte para GPUs, facilita a construção, treinamento e experimentação de modelos complexos.
Se você está trabalhando em pesquisa avançada ou desenvolvendo aplicações industriais de aprendizado de máquina, PyTorch é uma escolha excelente que combina facilidade de uso com performance robusta.
10.3.9 - Flask
Descrição: Flask é um micro-framework para aplicações web em Python baseado na biblioteca Werkzeug e Jinja2. Django é um framework de alto nível que promove design rápido para desenvolvimento web e é pragmático.
Usos Comuns: Flask é adequado para aplicações web menores e mais controladas, enquanto Django é ideal
Flask é um microframework web escrito em Python, conhecido por sua simplicidade, flexibilidade e extensibilidade. Ele é projetado para facilitar a criação de aplicações web robustas e escaláveis, desde simples sites estáticos até APIs RESTful complexas. Flask é minimalista, o que significa que ele fornece apenas os componentes essenciais para criar uma aplicação web, permitindo que os desenvolvedores escolham e configurem suas próprias bibliotecas e ferramentas adicionais conforme necessário.
Principais Funcionalidades
Roteamento
Roteamento de URLs: Flask utiliza um sistema de roteamento baseado em decorators para mapear URLs para funções Python. Isso permite uma configuração simples e clara das rotas da aplicação.
from flask import Flask
app = Flask(__name__)
@app.route('/')
def home():
return "Hello, World!"
if __name__ == '__main__':
app.run(debug=True)Templates
Renderização de Templates: Flask suporta a renderização de templates HTML usando o mecanismo Jinja2. Isso permite a criação de páginas dinâmicas que podem incluir variáveis e lógica de controle diretamente nos arquivos HTML.
from flask import render_template
@app.route('/hello/<name>')
def hello(name):
return render_template('hello.html', name=name)Template (hello.html):
<!doctype html>
<html>
<head><title>Hello</title></head>
<body>
<h1>Hello, {{ name }}!</h1>
</body>
</html>Formulários e Validação
Manipulação de Formulários: Flask-WTF é uma extensão que integra o WTForms com Flask para facilitar a criação e validação de formulários.
from flask_wtf import FlaskForm
from wtforms import StringField, SubmitField
from wtforms.validators import DataRequired
class MyForm(FlaskForm):
name = StringField('Name', validators=[DataRequired()])
submit = SubmitField('Submit')Solicitações e Respostas
Manipulação de Solicitações: Flask fornece objetos de requisição e resposta para lidar com dados enviados pelos clientes, incluindo parâmetros de URL, formulários, arquivos e cookies.
from flask import request
@app.route('/submit', methods=['POST'])
def submit():
name = request.form.get('name')
return f"Submitted name: {name}"APIs RESTful
Criação de APIs: Flask é amplamente utilizado para criar APIs RESTful. Com a ajuda de extensões como Flask-RESTful, é possível construir APIs seguindo as melhores práticas de REST.
from flask_restful import Api, Resource
app = Flask(__name__)
api = Api(app)
class HelloWorld(Resource):
def get(self):
return {'hello': 'world'}
api.add_resource(HelloWorld, '/')
if __name__ == '__main__':
app.run(debug=True)Autenticação e Autorização
Autenticação de Usuários: Flask-Login é uma extensão que gerencia sessões de usuário, permitindo o login e logout, além de proteger rotas específicas.
from flask_login import LoginManager, UserMixin, login_user, login_required, logout_user
login_manager = LoginManager()
login_manager.init_app(app)
class User(UserMixin):
# Modelo de usuário (geralmente integrado com uma base de dados)
@login_manager.user_loader
def load_user(user_id):
# Função para carregar um usuário
return User.get(user_id)Exemplo de Aplicação Completa
Aqui está um exemplo de uma aplicação Flask simples que inclui rotas, templates e manipulação de formulários:
from flask import Flask, render_template, request, redirect, url_for
from flask_wtf import FlaskForm
from wtforms import StringField, SubmitField
from wtforms.validators import DataRequired
app = Flask(__name__)
app.config['SECRET_KEY'] = 'mysecretkey'
class NameForm(FlaskForm):
name = StringField('What is your name?', validators=[DataRequired()])
submit = SubmitField('Submit')
@app.route('/', methods=['GET', 'POST'])
def index():
form = NameForm()
if form.validate_on_submit():
return redirect(url_for('hello', name=form.name.data))
return render_template('index.html', form=form)
@app.route('/hello/<name>')
def hello(name):
return render_template('hello.html', name=name)
if __name__ == '__main__':
app.run(debug=True)Template (index.html):
<!doctype html>
<html>
<head><title>Index</title></head>
<body>
<form method="post">
{{ form.hidden_tag() }}
{{ form.name.label }} {{ form.name(size=20) }}
{{ form.submit() }}
</form>
</body>
</html>Template (hello.html):
<!doctype html>
<html>
<head><title>Hello</title></head>
<body>
<h1>Hello, {{ name }}!</h1>
</body>
</html>Extensibilidade
Flask é projetado para ser extensível e modular. Existem muitas extensões disponíveis que adicionam funcionalidades adicionais, como integração com bancos de dados (Flask-SQLAlchemy), autenticação de usuários (Flask-Login), migração de banco de dados (Flask-Migrate), e muito mais.
Conclusão
Flask é um microframework web poderoso e flexível que permite aos desenvolvedores criar rapidamente aplicações web robustas. Sua simplicidade e extensibilidade o tornam uma excelente escolha para projetos pequenos a médios, bem como para a criação de APIs RESTful. Com uma comunidade ativa e uma vasta coleção de extensões, Flask continua a ser uma das principais escolhas para desenvolvimento web em Python.
10.3.10 - Django
Descrição: Flask é um micro-framework para aplicações web em Python baseado na biblioteca Werkzeug e Jinja2. Django é um framework de alto nível que promove design rápido para desenvolvimento web e é pragmático.
Usos Comuns: Flask é adequado para aplicações web menores e mais controladas, enquanto Django é ideal
10.3.11 - PIP
O PIP é um gerenciador de pacotes de m[odulos do Python.
Observação: se você tiver o Python versão 3.4 ou posterior, o PIP será incluído por padrão.
O que é um Pacote?
Um pacote contém todos os arquivos necessários para um módulo.
Módulos são bibliotecas de código Python que você pode incluir em seu projeto.
Verifique se o PIP está instalado
Navegue pela linha de comando até o local do diretório de scripts do Python e digite o seguinte:
Exemplo: verifique a versão do PIP.
pip --versionInstalação do PIP
Se você não tiver o PIP instalado, poderá baixá-lo e instalá-lo nesta página: https://pypi.org/project/pip/
Instalação de pacotes
Para baixar um pacote usamos o prompt de comandos do sistema operacional e comandamos ao PIP baixar o pacote desejado.
Navegue pela linha de comando até o local do diretório de scripts do Python e digite o seguinte.
Exemplo: Baixando e instalando o pacote chamado "camelcase".
pip install camelcaseAgora você baixou e instalou seu primeiro pacote!
Utilização de um pacotes
Uma vez que o pacote ser baixado e instalado, estará pronto para uso.
Exemplo: importação e uso do módulo "camelcase".
import camelcase
c = camelcase.CamelCase()
txt = "hello world"
print(c.hump(txt))Pesquisa de pacotes
Encontre mais pacotes em https://pypi.org/ .
Remoção de Pacotes
Use o comando uninstall para remover um pacote.
Exemplo: desinstalação do pacote "camelcase":
pip uninstall camelcaseO Gerenciador de Pacotes PIP solicitará que você confirme se deseja remover o pacote "camelcase".
Uninstalling camelcase-02.1:
Would remove:
c:\users\Your Name\appdata\local\programs\python\python36-32\lib\site-packages\camecase-0.2-py3.6.egg-info
c:\users\Your Name\appdata\local\programs\python\python36-32\lib\site-packages\camecase\*
Proceed (y/n)?Pressione "y" e o pacote será removido.
Listar pacotes
Use o listcomando para listar todos os pacotes instalados em seu sistema:
Exemplo listar os pacotes instalados.
pip listPackage Version
-----------------------
camelcase 0.2
mysql-connector 2.1.6
pip 18.1
pymongo 3.6.1
setuptools 39.0.1

