

4 - Gráficos elaborados
Os gráficos podem ser trabalhados de modo a ficarem bastante elaborados, com diferentes formatos e cores.
Importamos as bibliotecas necessárias para trabalhar com os gráficos:
import matplotlib as mpl
import matplotlib.pyplot as plt
from matplotlib.ticker import AutoMinorLocator, MultipleLocator, FuncFormatter
from matplotlib.patches import Circle
from matplotlib.patheffects import withStroke
import math
import numpy as np
import pandas as pd
import seaborn as sns
#import plotly
import plotly.express as px
from pywaffle import Waffle
import circlify as cfy4.1 - Diagrama de Gráficos
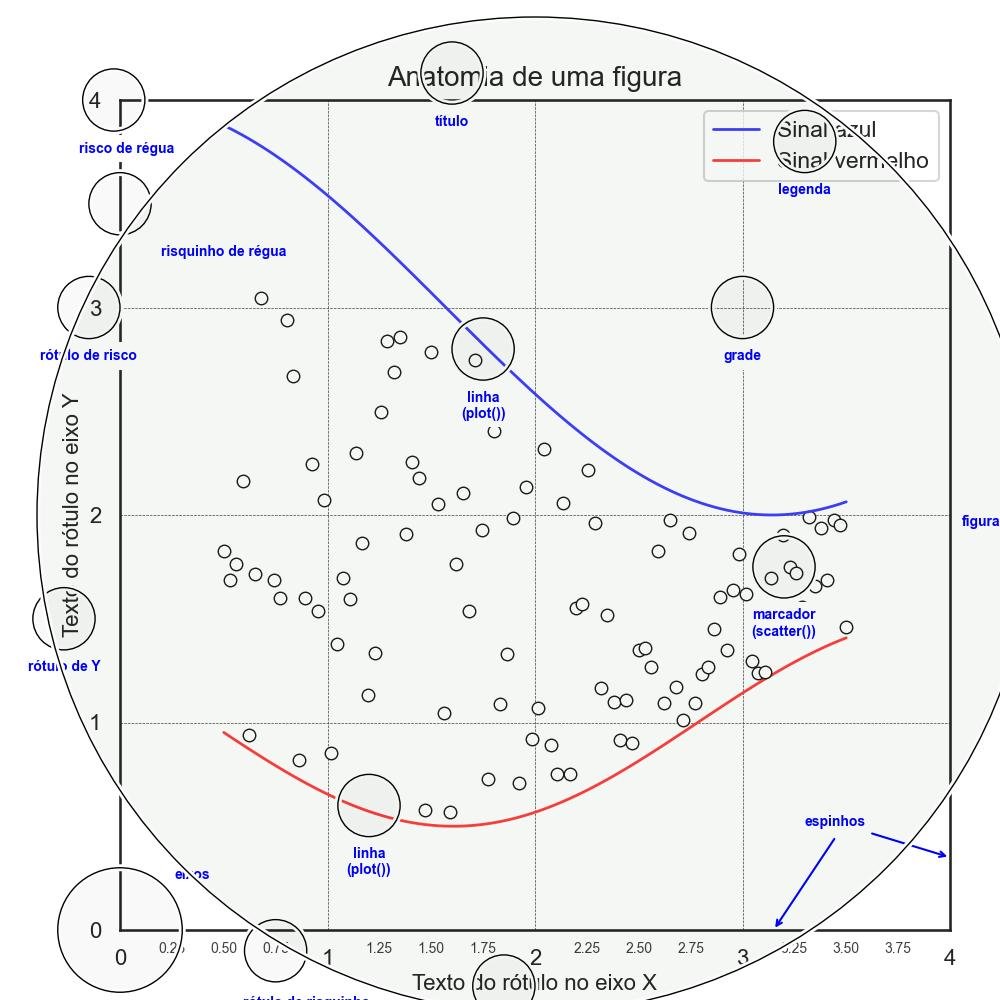
O primeiro gráfico elaborado que apresentamos é o Diagrama de Gráficos.
np.random.seed(19680801)
X = np.linspace(0.5, 3.5, 100)
Y1 = 3+np.cos(X)
Y2 = 1+np.cos(1+X/0.75)/2
Y3 = np.random.uniform(Y1, Y2, len(X))
font = {'size': 10}
plt.rc('font', **font)
plt.subplots_adjust(left=0.3, right=0.9, bottom=0.2, top=0.9)
fig = plt.figure(figsize=(10, 10))
ax = fig.add_subplot(1, 1, 1, aspect=1)
def risquinho(x, pos):
return "%.2f" % x if x % 1.0 else ""
ax.xaxis.set_major_locator(MultipleLocator(1.000))
ax.xaxis.set_minor_locator(AutoMinorLocator(4))
ax.yaxis.set_major_locator(MultipleLocator(1.000))
ax.yaxis.set_minor_locator(AutoMinorLocator(4))
ax.xaxis.set_minor_formatter(FuncFormatter(risquinho))
ax.set_xlim(0, 4)
ax.set_ylim(0, 4)
ax.tick_params(which='major', width=1.0)
ax.tick_params(which='major', length=10)
ax.tick_params(which='minor', width=1.0, labelsize=10)
ax.tick_params(which='minor', length=5, labelsize=10, labelcolor='0.25')
ax.grid(linestyle="--", linewidth=0.5, color='.25', zorder=-10)
ax.plot(X, Y1, label="Sinal azul", c=(0.25, 0.25, 1.00), lw=2, zorder=10)
ax.plot(X, Y2, label="Sinal vermelho", c=(1.00, 0.25, 0.25), lw=2)
ax.plot(X, Y3, marker='o', mfc='w', mec='k', lw=0)
ax.set_title("Anatomia de uma figura", fontsize=20, verticalalignment='bottom')
ax.set_xlabel("Texto do rótulo no eixo X")
ax.set_ylabel("Texto do rótulo no eixo Y")
ax.legend(loc="upper right")
def circle(x, y, radius=0.15, facecolor=(0, 0, 0, .0125), edgecolor='black'):
circle = Circle((x, y), radius,
clip_on=False, zorder=10, linewidth=1,
edgecolor='black', facecolor=facecolor,
path_effects=[withStroke(linewidth=5, foreground='w')])
global ax
ax.add_artist(circle)
def text(x, y, text):
global ax
ax.text(x, y, text, backgroundcolor="white",
ha='center', va='top', weight='bold', color='blue')
circle(0.75, -0.10)
text(0.9, -0.32, "rótulo de risquinho")
circle(-0.03, 4.0)
text(0.03, 3.80, "risco de régua")
circle(0.0, 3.5)
text(0.5, 3.3, "risquinho de régua")
circle(-0.15, 3.0)
text(-0.15, 2.8, "rótulo de risco")
circle(1.85, -0.27)
text(1.85, -0.45, "rótulo de X")
circle(-0.27, 1.5)
text(-0.27, 1.3, "rótulo de Y")
circle(1.6, 4.13)
text(1.60, 3.93, "título")
circle(1.75, 2.8)
text(1.75, 2.6, "linha\n(plot())")
circle(1.2, 0.6)
text(1.2, 0.4, "linha\n(plot())")
circle(3.2, 1.75)
text(3.2, 1.55, "marcador\n(scatter())")
circle(3.0, 3.0)
text(3.0, 2.8 , "grade")
circle(3.3, 3.8, edgecolor=None)
text(3.3, 3.6, "legenda")
circle(0.0, 0.0, 0.3)
text(0.35, 0.3, "eixos")
circle(2, 2, 2.4, facecolor=(0, .2, 0, .02))
text(4.15, 2, "figura")
color = 'blue'
ax.annotate('espinhos', xy=(4.0, 0.35), xycoords='data',
xytext=(3.3, 0.5), textcoords='data',
weight='bold', color=color,
arrowprops=dict(arrowstyle='->',
connectionstyle="arc3",
color=color))
ax.annotate('', xy=(3.15, 0.0), xycoords='data',
xytext=(3.45, 0.45), textcoords='data',
weight='bold', color=color,
arrowprops=dict(arrowstyle='->',
connectionstyle="arc3",
color=color))
ax.text(4.0, -0.4, "Feito com http://matplotlib.org",
fontsize=10, ha="right", color='.5')
plt.show()
4.2 - Preparação dos dados para os gráficos
4.3 - Gráfico de Barras para comparação
Agora que tudo está pronto, vamos traçar um gráfico de barras para comparar com os resultados de outras visualizações posteriormente.
sns.set_style('darkgrid')
g = sns.barplot(data=df,x='País',y='Emissão',ci=False,palette='viridis_r')
g.set_xticklabels(df['País'],rotation = 55,fontdict = {'fontsize':10})
plt.show()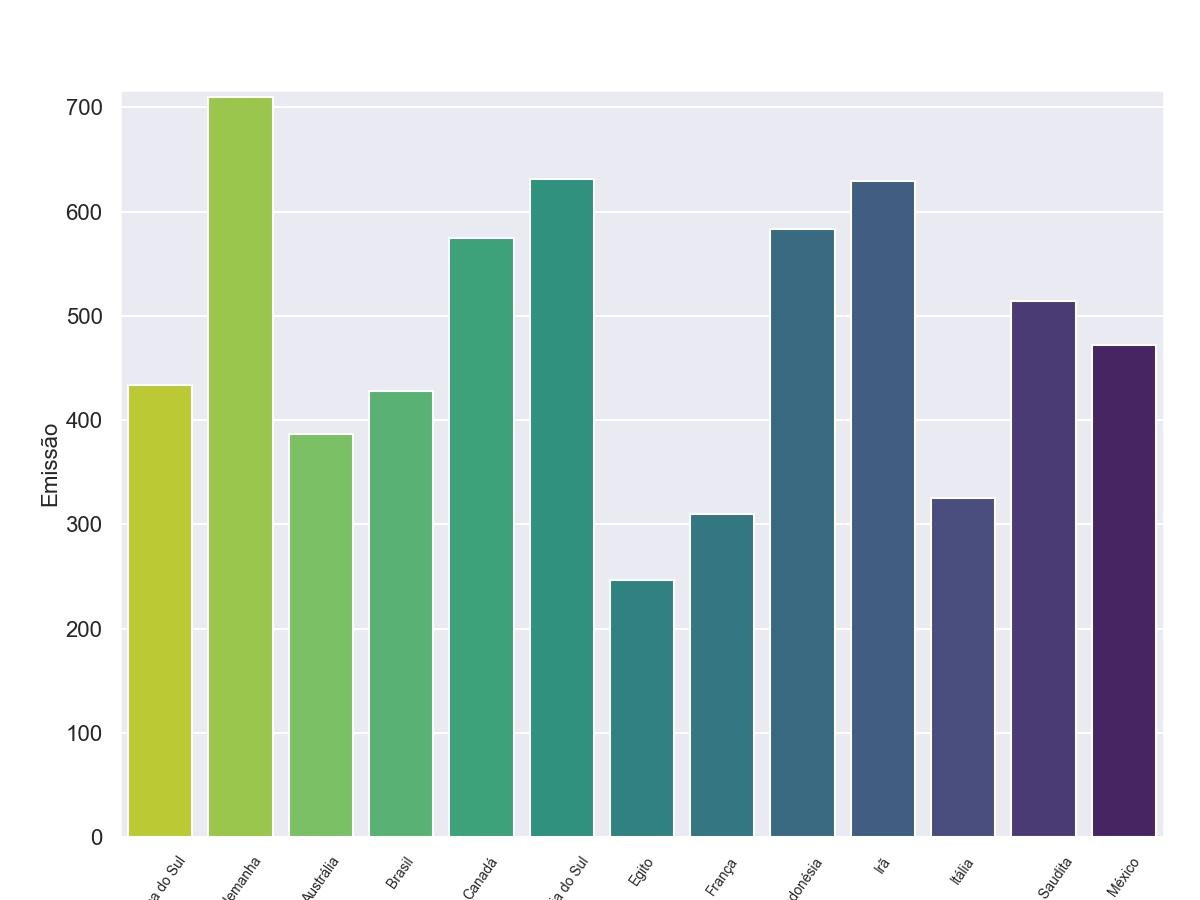
4.4 - Gráfico de Barras Circulares
O conceito do gráfico de barras circulares, também conhecido como gráfico de pista de corrida, é expressar as barras ao redor do centro de um círculo. Cada barra começa no mesmo grau e se move na mesma direção. Aquele que pode completar o loop tem o valor mais alto.
Essa é uma boa ideia para chamar a atenção dos leitores. A propósito, as barras que param no meio do círculo são difíceis de ler. Tenha em atenção que o comprimento de cada barra não é igual. Os próximos ao centro terão um comprimento menor do que os distantes do centro.
Funções utilizadas para o gráfico de barras circulares:
def laco_barra_circular(df, ax, pal):
for i in range(len(df)):
ax.barh(
i, list(df['Emissão'])[i]*2*np.pi/max_val,
label=list(df['País'])[i], color=pal[i])
def atribuir_ax(df):
ax.set_theta_zero_location('N')
ax.set_theta_direction(1)
ax.set_rlabel_position(0)
ax.set_thetagrids([], labels=[])
ax.set_rgrids(range(df_len), labels= df['País'])
Traçar um gráfico de barras circulares com o DataFrame
Definindo cores:
plt.gcf().set_size_inches(12, 12)
sns.set_style('darkgrid')
# atribuir o valor máximo
max_val = max(df['Emissão'])*1.01
ax = plt.subplot(projection='polar')
# atribuir a subplotagem
atribuir_ax(df)
# atribuir a projeção polar
ax = plt.subplot(projection='polar')
# laço com as linhas do dataframe
laco_barra_circular(df, ax, pal_vi)
# preparar a legenda
plt.legend(bbox_to_anchor=(1, 1), loc=2)
# mostrar o gráfico
plt.show()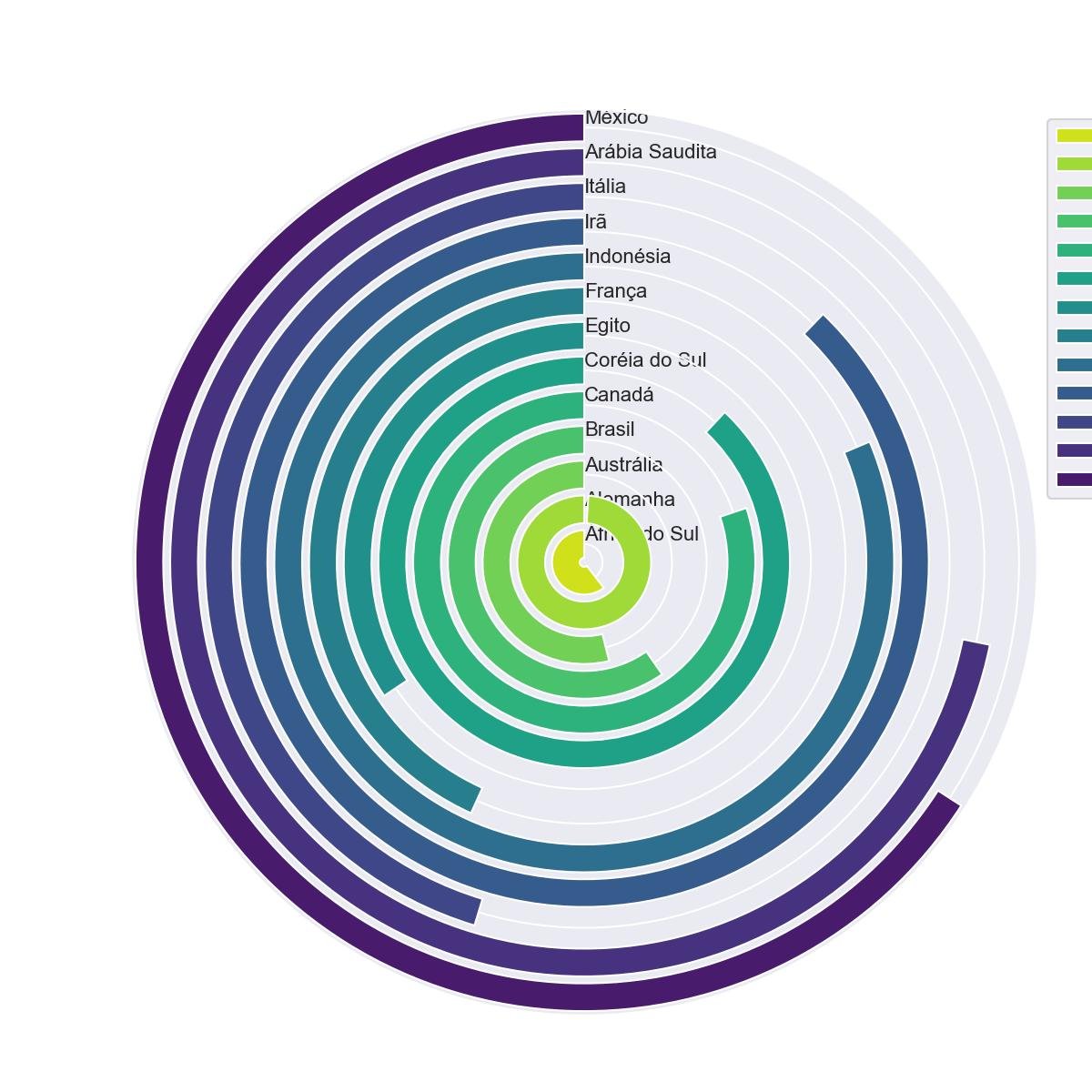
4.4.1 - Barras circulares classificadas
Trace o gráfico de barras circulares com o dataframe classificado.
plt.gcf().set_size_inches(12, 12)
sns.set_style('darkgrid')
# atribuir o valor máximo
max_val = max(df_s['Emissão'])*1.01
ax = plt.subplot(projection='polar')
# laço com as linhas do dataframe
laco_barra_circular(df_s, ax, pal_plas)
# atribuir a subplotagem
atribuir_ax(df_s)
# atribuir a projeção polar
ax = plt.subplot(projection='polar')
# preparar a legenda
plt.legend(bbox_to_anchor=(1, 1), loc=2)
# mostrar o gráfico
plt.show()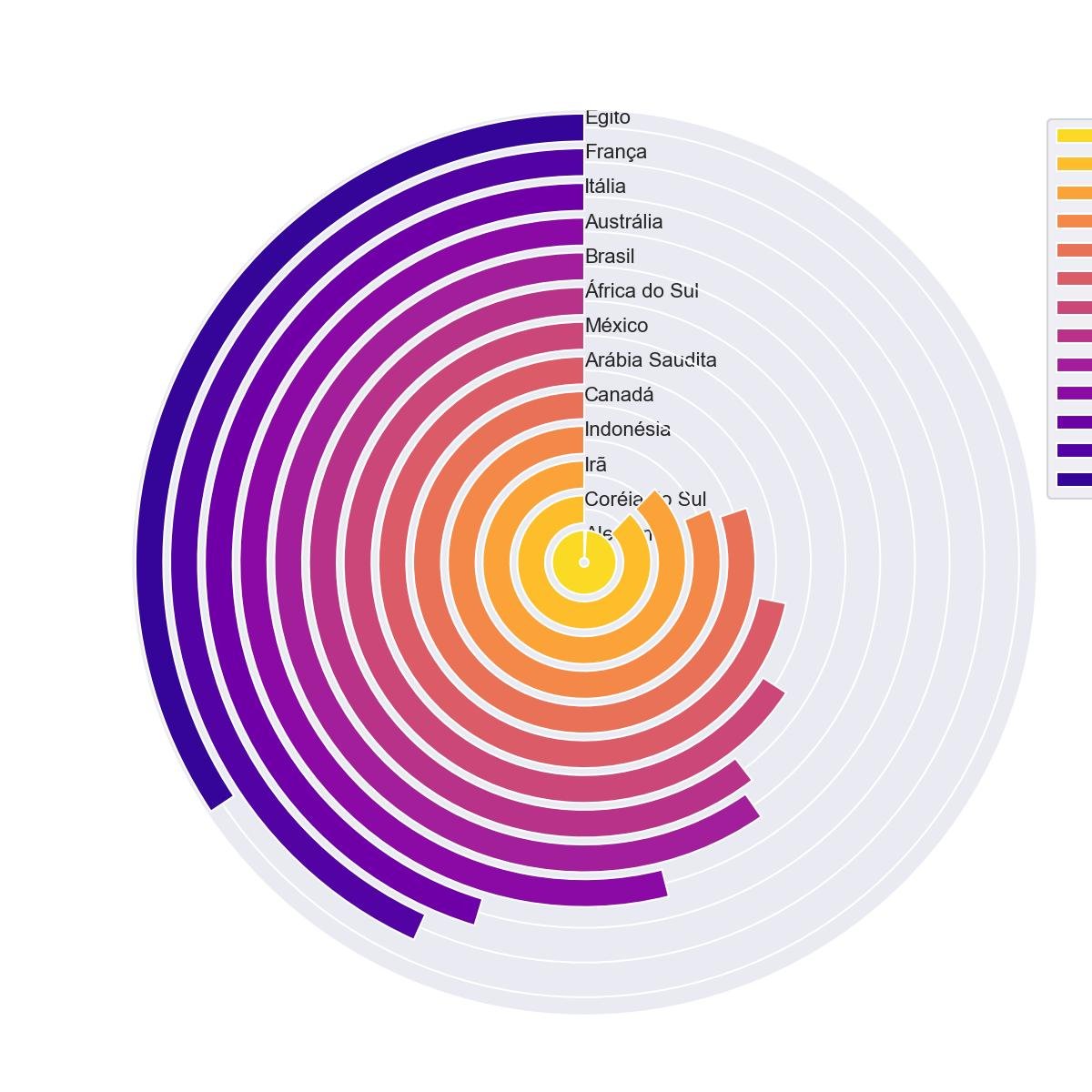
4.5 - Gráfico de Barras Radiais
O conceito de um Gráfico de Barras Radiais é variar a direção das barras.
4.5.1 - Gráfico de Barras Radial começando do centro
Em vez de ter a mesma direção, cada barra começa no centro de um círculo e se move em uma direção diferente até a borda do círculo.
Por favor, considere que as barras não localizadas adjacentes umas às outras podem ser difíceis de comparar. As etiquetas estão em ângulos diferentes ao longo das barras radiais; isso pode causar transtornos aos usuários.
Traçar um gráfico de barras radial com o DataFrame
# obter a paleta de cores
pal_vi = get_color('viridis_r', df_len)
# criar o gráfico
plt.figure(figsize=(12,12))
ax = plt.subplot(111, polar=True)
plt.axis()
# atribuir os valores mínimo e máximo
lowerLimit = 0
max_v = df['Emissão'].max()
# atribuir a altura e a largura
alturas = df['Emissão']
largura = 2*np.pi / len(df.index)
# atribuir o índice e o ângulo
indices = list(range(1, len(df.index)+1))
angulos = [element for element in indices]
for i in range(df_len):
angulos[i] = angulos[i] * largura
bars = ax.bar(
x=angulos, height=alturas, width=largura, bottom=lowerLimit,
linewidth=1, edgecolor="white", color=pal_vi)
labelPadding = 15
for bar, angulo, altura, rotulo in zip(bars,angulos, alturas, df['País']):
rotacao = np.rad2deg(angulo)
alinhamento = ""
# se o ângulo estiver entre 90 e 270 graus, a alinhamento é à direita
if angulo >= np.pi/2 and angulo < 3*np.pi/2:
alinhamento = "right"
rotacao = rotacao + 180
else:
alinhamento = "left"
ax.text(
x=angulo,
y=lowerLimit + bar.get_height() + labelPadding,
s=rotulo,
ha=alinhamento,
va='center',
rotation=rotacao,
rotation_mode="anchor"
)
ax.set_thetagrids([], labels=[])
plt.show()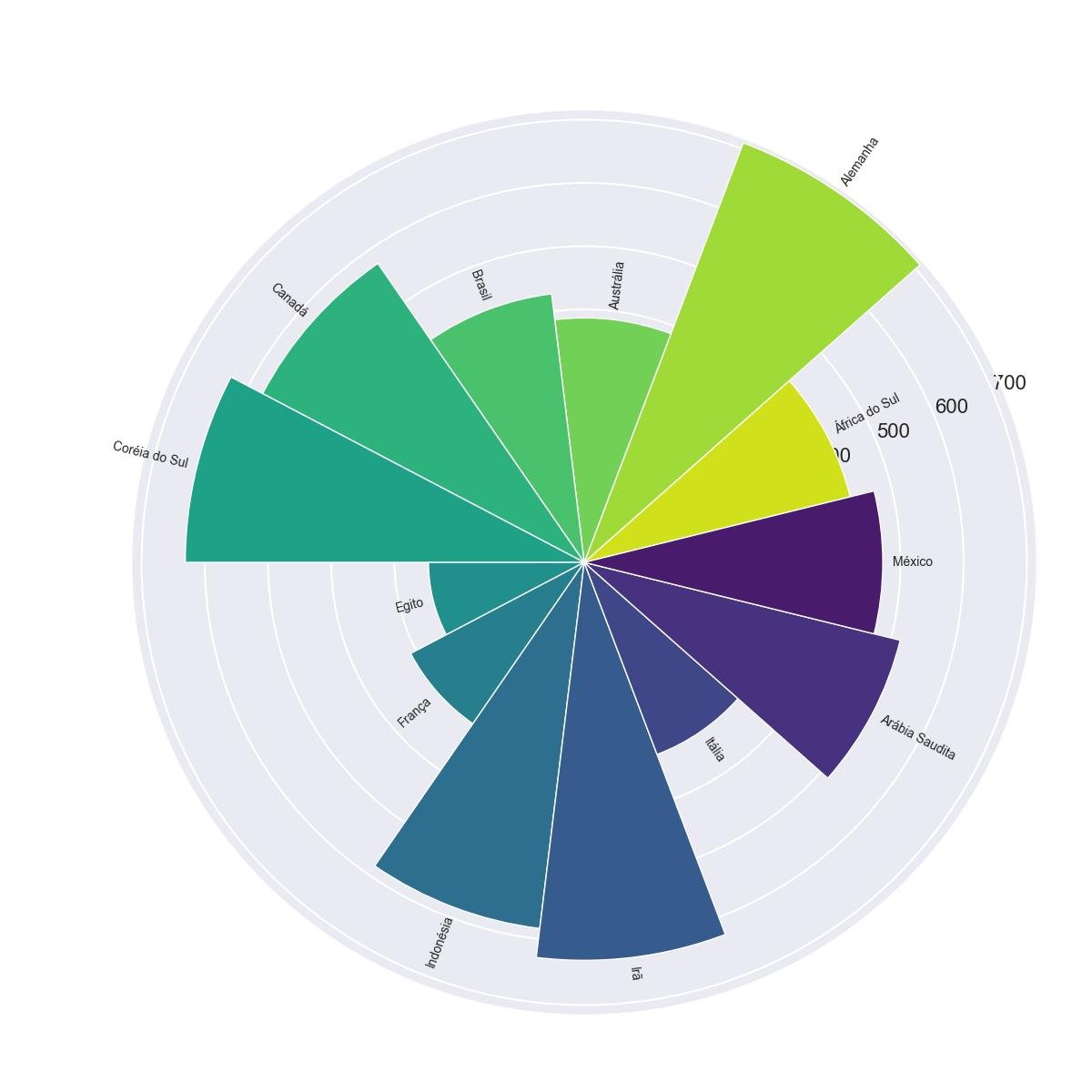
4.5.2 - Gráfico de Barras Radiais com dataframe classificado
plt.figure(figsize=(12,12))
ax = plt.subplot(111, polar=True)
plt.axis()
# atribuir os valores mínimo e máximo
lowerLimit = 0
max_v = df_s['Emissão'].max()
# atribuir a altura e a largura
alturas = df_s['Emissão']
largura = 2*np.pi / len(df_s.index)
# atribuir o índice e o ângulo
indices = list(range(1, len(df_s.index)+1))
angulos = [element for element in indices]
for i in range(df_len):
angulos[i] = angulos[i] * largura
barras = ax.bar(
x = angulos,
height = alturas,
width = largura,
bottom = lowerLimit,
linewidth = 1,
edgecolor = "white",
color = pal_plas)
labelPadding = 15
z = zip(barras,angulos, alturas, df_s['País'])
for bar, angulo, altura, rotulo in z:
rotacao = np.rad2deg(angulo)
alinhamento = ""
# se o ângulo estiver entre 90 e 270 graus, a alinhamento é à direita
if angulo >= np.pi/2 and angulo < 3*np.pi/2:
alinhamento = "right"
rotacao = rotacao + 180
else:
alinhamento = "left"
ax.text(
x=angulo,
y=lowerLimit + bar.get_height() + labelPadding,
s=rotulo,
ha=alinhamento,
va='center',
rotation=rotacao,
rotation_mode="anchor")
ax.set_thetagrids([], labels=[])
plt.show()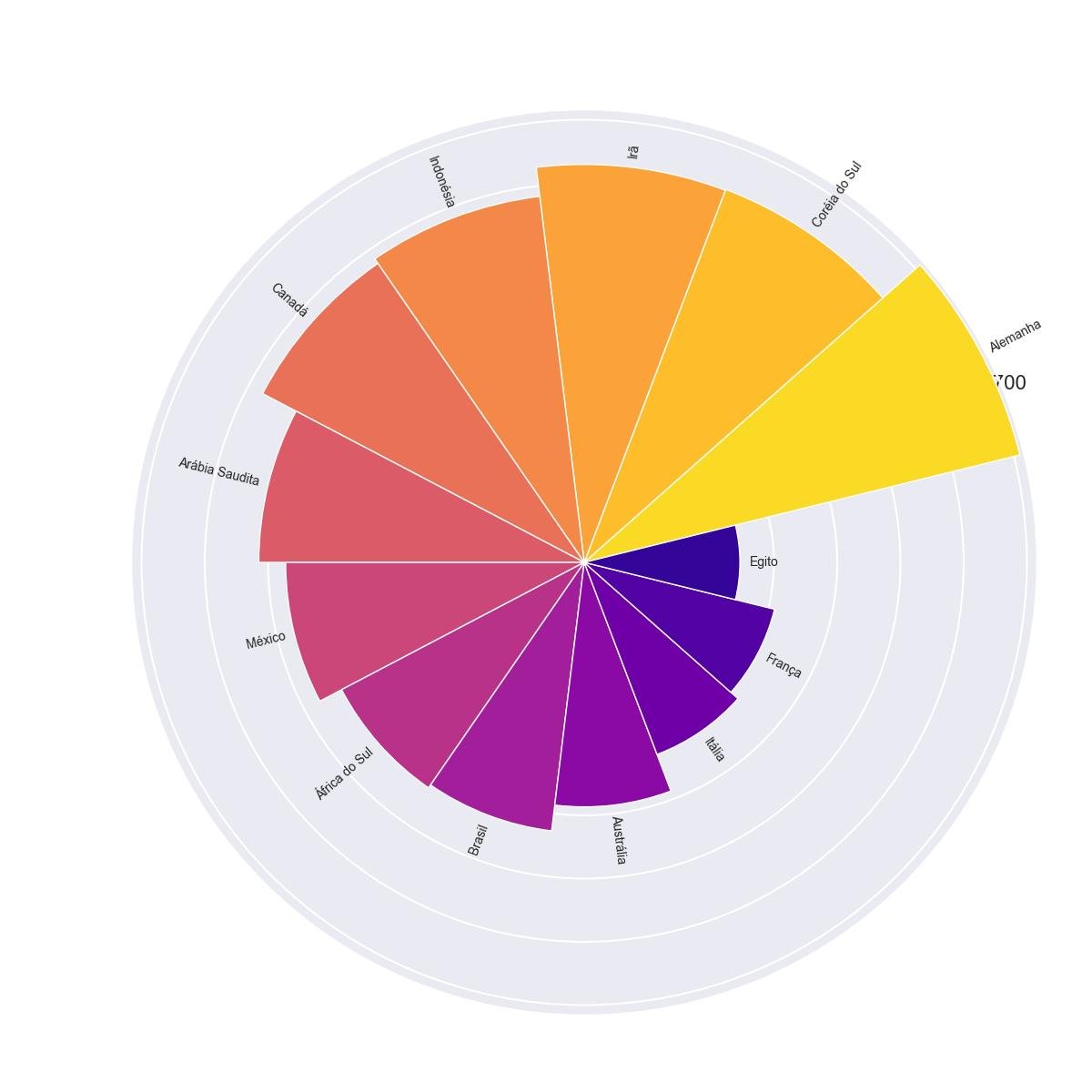
4.6 - Mapa de Árvore (Treemap)
Um Mapa de Árvore (Treemap) ajuda a exibir dados hierárquicos usando áreas de retângulos.
Mesmo que nossos dados não tenham hierarquia, ainda podemos aplicar um mapa de árvore mostrando apenas um nível de hierarquia.
Plotando um mapa de árvore, geralmente, os dados são classificados em ordem decrescente do valor máximo.
Com muitos retângulos, lembre-se de que os pequenos podem ser difíceis de ler ou distinguir dos outros.
No exemplo a seguir é apresentado um Mapa de Árvore com Plotly.
fig = px.treemap(
df,
path = [px.Constant('País'), 'País'],
values = df['Emissão'],
color = df['Emissão'],
color_continuous_scale = 'Spectral_r',
color_continuous_midpoint = np.average(df['Emissão']))
fig.update_layout(margin = dict(t=50, l=25, r=25, b=25))
fig.show()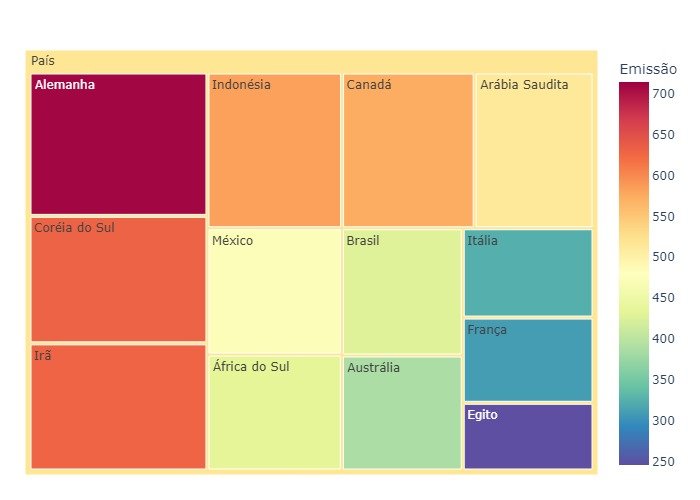
4.6.1 - Combinando pequenos quadrados com um gráfico Waffle
Além do nome chique, o gráfico de waffle é uma boa ideia para criar um infográfico. Consiste em muitos quadrados menores combinados em um grande retângulo, fazendo com que o resultado pareça um waffle.
Normalmente, os quadrados são organizados em um layout de 10 por 10 para mostrar a proporção ou o progresso. A propósito, o número de quadrados pode ser alterado para se adequar aos dados.
Trace um gráfico de waffle exibindo as emissões de CO2 de cada país
fig = plt.figure(
FigureClass = Waffle,
rows = 20,
columns = 50,
values = list(df_s['Emissão']),
colors = pal_spec,
labels = [i+' '+format(j, ',') for i,j in zip(df_s['País'], df_s['Emissão'])],
figsize = (15,6),
legend = {
'loc' : 'upper right',
'bbox_to_anchor' : (1.26, 1)
})
plt.tight_layout()
plt.show()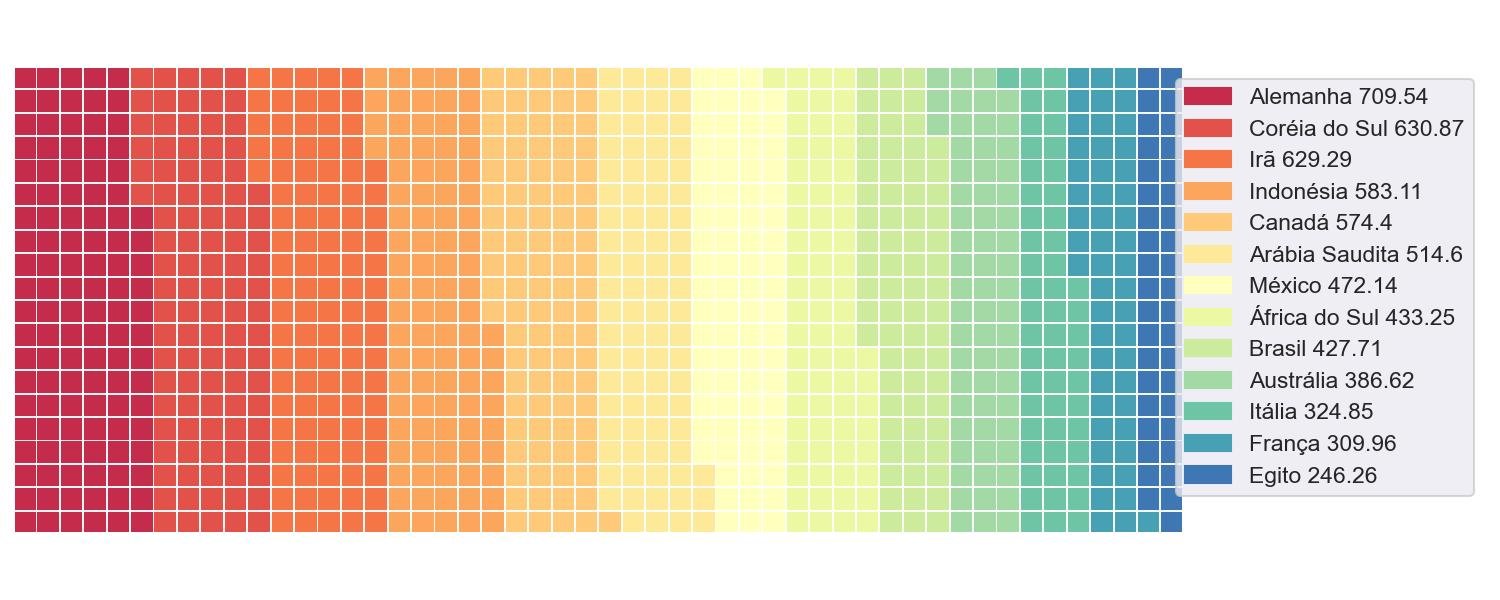
4.7 - Gráfico de pizza
Um gráfico de pizza é outro gráfico típico na visualização de dados. É basicamente um gráfico estatístico circular dividido em fatias para mostrar a proporção numérica. O gráfico de pizza comum pode ser convertido em interativo para que o resultado possa ser reproduzido ou filtrado. Podemos usar o Plotly para criar um gráfico de pizza interativo.
Assim como no gráfico de barras interativo, deve haver uma instrução explicando como usar a função caso os leitores sejam usuários finais.
Traçar um gráfico de pizza interativo
fig = px.pie(
df_s, values='Emissão', names='País',
color ='País', color_discrete_sequence=pal_vi)
fig.update_traces(textposition='inside',textinfo='percent+label',sort=False)
fig.update_layout(width=1000,height=550)
fig.show()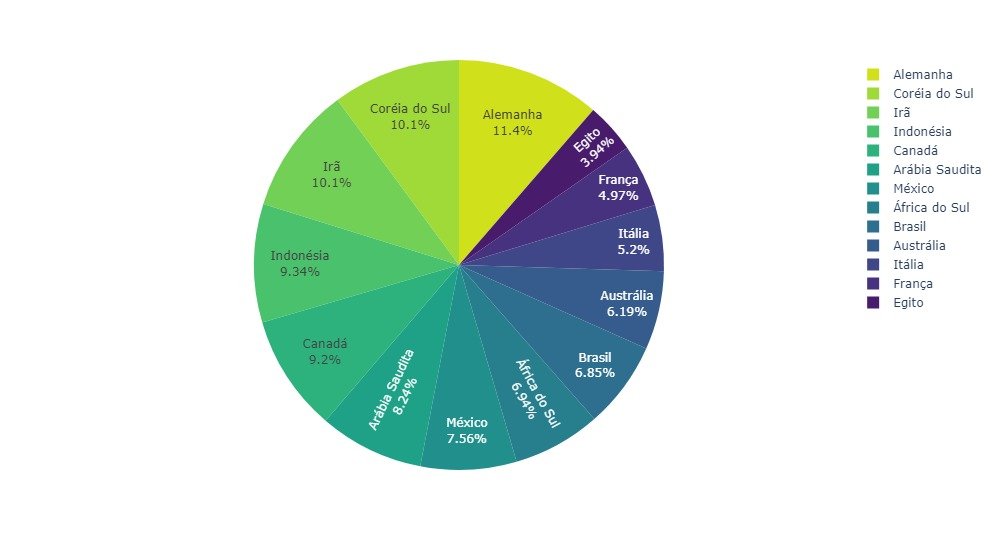
4.8 - Gráfico de radar
Um gráfico de radar é um método gráfico de exibição de dados multivariados. Em comparação, os gráficos de barras são usados principalmente com dados categóricos. Para aplicar o gráfico de radar com dados categóricos, podemos considerar cada categoria como uma variável nos dados multivariados. O valor de cada categoria será plotado a partir do centro.
Com muitas categorias, os usuários podem achar difícil comparar os dados que não estão localizados próximos uns dos outros. Isso pode ser resolvido aplicando o gráfico de radar com dados classificados. Assim, os usuários podem determinar quais valores são maiores ou menores que os demais.
Trace um gráfico de radar com o DataFrame.
fig = px.line_polar(df,r='Emissão',theta='País',line_close=True)
fig.update_traces(fill='toself',line=dict(color=pal_spec[5]))
fig.show()
4.8.1 - Trace um gráfico de radar com o DataFrame classificado.
fig = px.line_polar(df_s,r='Emissão',theta='País',line_close=True)
fig.update_traces(fill='toself',line=dict(color=pal_spec[-5]))
fig.show()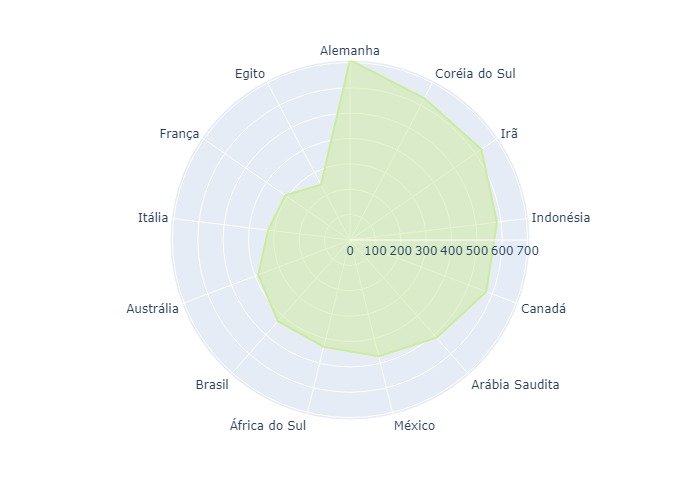
4.9 - Gráfico de bolhas
Teoricamente, um gráfico de bolhas é um gráfico de dispersão com diferentes tamanhos do ponto de dados.
Este é um gráfico ideal para exibir dados tridimensionais, valor X, valor Y e tamanho dos dados.
Uma coisa boa sobre a aplicação de um gráfico de bolhas com dados categóricos sem valores X e Y é que podemos localizar as bolhas da maneira que queremos.
Por exemplo, o código abaixo mostra como plotar as bolhas verticalmente.
Crie uma lista de valores X, valores Y e rótulos. Em seguida, adicione-os como colunas ao dataframe.
Se você deseja plotar as bolhas na direção horizontal, alterne os valores entre as colunas X e Y.
Os argumentos da função px.scatter são: df, x, y, color, color_discrete_sequence, size, text, size_max.
- O argumento df é o dataframe.
- O argumento x e y são os valores das colunas X e Y, respectivamente.
- O argumento color é a coluna que contém os valores categóricos de cores.
- O argumento color_discrete_sequence é a lista de cores que você deseja usar.
- O argumento size é a coluna que contém os valores numéricos de tamanho.
- O argumento text é a coluna que contém os rótulos.
- O argumento size_max é o tamanho máximo da bolha.
# X-axis e Y-axis das colunas
df_s['X'] = [1] * len(df_s)
list_y = list(range(0,len(df_s)))
list_y.reverse()
df_s['Y'] = list_y
# Rótulos das colunas
z = zip(df_s['País'], df_s['Emissão'])
df_s['labels'] = ['<b>{}:</b> {}'.format(i,j) for i,j in z]
df_s
fig = px.scatter(
df_s,
x='X',
y='Y',
color='País',
color_discrete_sequence=pal_vi,
size='Emissão',
text='labels',
size_max=30)
fig.update_layout(
width=500,
height=1100,
margin=dict(t=0, l=0, r=0, b=0),
showlegend=False
)
fig.update_traces(textposition='middle right')
fig.update_xaxes(showgrid=False, zeroline=False, visible=False)
fig.update_yaxes(showgrid=False, zeroline=False, visible=False)
fig.update_layout({
'plot_bgcolor' : 'white',
'paper_bgcolor': 'white'
})
fig.show()
4.9.1 - Bolhas em formato circular
Para ir mais longe, podemos exibir as bolhas em diferentes formas.
Vamos tentar plotá-los em uma direção circular.
Para fazer isso, precisamos calcular as coordenadas X e Y. Comece dividindo 360 graus pelo número de linhas. Em seguida, converta os graus com as funções Cosseno e Seno para obter as coordenadas X e Y, respectivamente.
# X-axis e Y-axis em circulo das colunas
segmento = 2 * math.pi / df_len
senos=[]
cosenos=[]
degree = [i for i in list(range(df_len))]
for i in range(0,df_len):
angulo = degree[i] * segmento
senos.append(math.sin(angulo))
cosenos.append(math.cos(angulo))
df_s['X_coor'] = cosenos;
df_s['Y_coor'] = senos;
# Rótulos das colunas
z = zip(df_s['País'], df_s['Emissão'])
df_s['labels'] = ['<b>'+i+'<br>'+format(j, ",") for i,j in z]
fig = px.scatter(
df_s,
x='X_coor',
y='Y_coor',
color='País',
color_discrete_sequence=pal_vi,
size='Emissão',
text='labels',
size_max=40
)
fig.update_layout(
width=800,
height=800,
margin=dict(t=0, l=0, r=0, b=0),
showlegend=False
)
fig.update_traces(textposition='bottom right')
fig.update_xaxes(showgrid=False, zeroline=False, visible=False)
fig.update_yaxes(showgrid=False, zeroline=False, visible=False)
fig.update_layout({
'plot_bgcolor' : 'white',
'paper_bgcolor': 'white'
})
fig.show()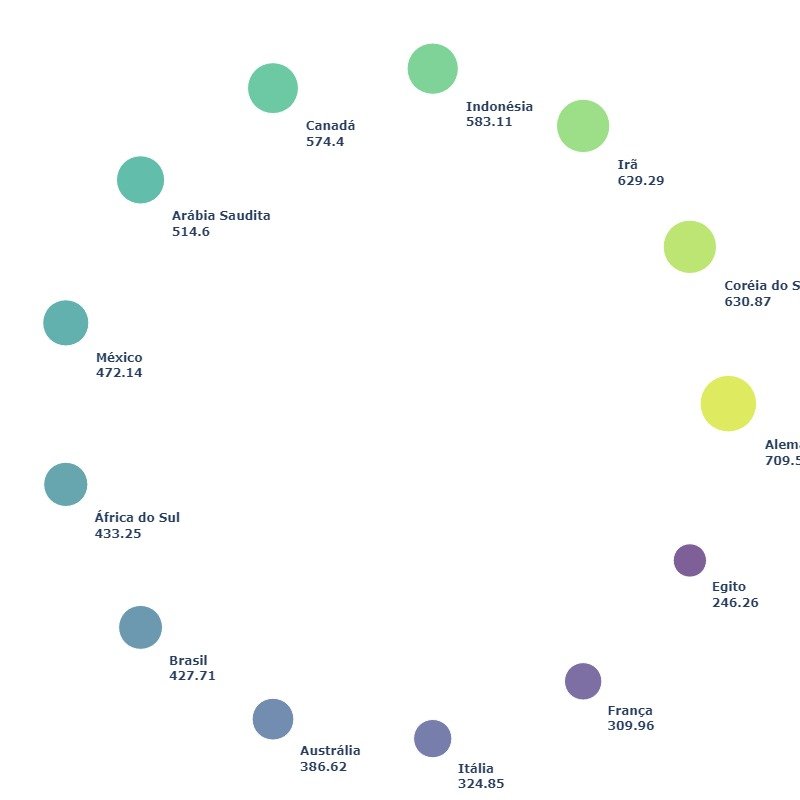
4.9.2 - Empacotamento circular
Por fim, vamos agrupar as bolhas sem área de sobreposição. A embalagem circular é uma boa ideia para traçar as bolhas enquanto economiza espaço. Precisamos calcular a posição e o tamanho de cada bolha. Felizmente, existe uma biblioteca chamada circlify que facilita o cálculo.
Uma desvantagem do empacotamento circular é que é difícil descobrir a diferença entre bolhas que têm tamanhos próximos. Isso pode ser resolvido rotulando cada bolha com seu valor.
# computar posições de círculos:
circulos = cfy.circlify(
df_s['Emissão'].tolist(),
show_enclosure=False,
target_enclosure=cfy.Circle(x=0, y=0)
)
circulos.reverse()
fig, ax = plt.subplots(figsize=(14, 14), facecolor='white')
ax.axis('off')
lim = max(max(abs(circle.x)+circle.r, abs(circle.y)+circle.r,) for circle in circulos)
plt.xlim(-lim, lim)
plt.ylim(-lim, lim)
# imprimir círculos
for circle, label, emi, color in zip(circulos, df_s['País'], df_s['Emissão'], pal_vi):
x, y, r = circle
ax.add_patch(plt.Circle((x, y), r, alpha=0.9, color = color))
plt.annotate(label +'\n'+ format(emi, ","), (x,y), size=15, va='center', ha='center')
plt.xticks([])
plt.yticks([])
plt.show()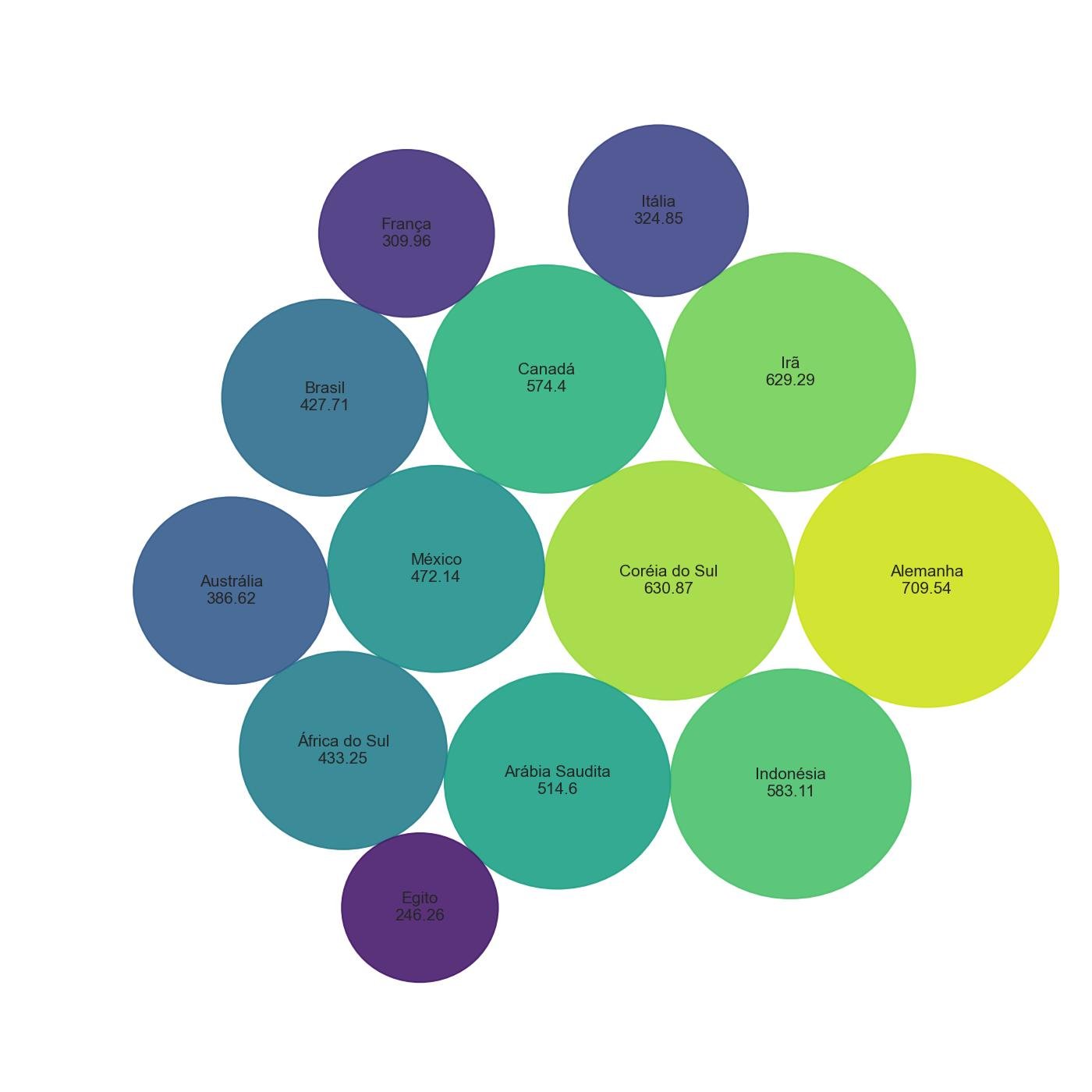
As bolhas estão empacotadas e não há sobreposição. No entanto, é difícil distinguir as bolhas com tamanhos próximos. Podemos resolver isso rotulando cada bolha com seu valor.



