
1 - Introdução à Estatística Avançada
1.1 Visão geral do curso
1.2 Revisão de conceitos fundamentais
Bem-vindo ao curso Estatística Avançada com Python da CIEDA!
Este curso foi elaborado para atender a estatísticos, sejam estudantes, graduados, mestres, doutores, e também a outros profissionais que desejem aprofundar seus conhecimentos em estatística e explorar técnicas avançadas de análise de dados, com exemplos usando a linguagem Python.
Nesta seção introdutória, forneceremos uma visão geral do conteúdo abordado no curso, destacando os principais tópicos e conceitos que serão explorados em profundidade ao longo dos próximos capítulos. Em cada um, você encontrará explicações detalhadas dos métodos estatísticos, juntamente com exemplos práticos e estudos de caso do mundo real.
Nosso objetivo é fornecer uma compreensão sólida e abrangente de técnicas estatísticas avançadas, bem como capacitar você a aplicá-las em problemas complexos de análise de dados. Antes de mergulharmos nos tópicos avançados, começaremos com uma revisão abrangente dos conceitos fundamentais da estatística.
Essa revisão tem como objetivo nivelar o conhecimento e relembrar os conceitos essenciais que são a base de toda análise estatística. Discutiremos conceitos-chave, como medidas de tendência central e dispersão, probabilidade, distribuições estatísticas, intervalos de confiança e testes de hipóteses. Além disso, abordaremos técnicas de análise exploratória de dados, como gráficos e visualizações, que desempenham um papel crucial na compreensão e na identificação de padrões nos conjuntos de dados.
Essa revisão nos preparará para os capítulos subsequentes, onde exploraremos em profundidade uma variedade de tópicos avançados da estatística. Você poderá consolidar seus conhecimentos prévios e estabelecer uma base sólida para os conceitos mais complexos que serão abordados, expandindo seu conjunto de ferramentas estatísticas e adquirir habilidades avançadas de análise de dados!
Autores
Roberto Teixeira
Betobyte
Cientista de Dados
CIEDA
cieda.com.br
roberto@cieda.com.br

Carlos Delfino
Arduino
Cientista de Dados
Basicão da Eletrônica
www.carlosdelfino.eti.br
consultoria@carlosdelfino.eti.br

1.1 - Visão geral do curso
1.2 - Revisão de conceitos fundamentais
Na seção de revisão de conceitos fundamentais, vamos relembrar e consolidar os principais conceitos e técnicas fundamentais da estatística que servirão de base sólida para a compreensão dos tópicos avançados abordados ao longo do curso.
Essa revisão é essencial para garantir que os leitores estejam familiarizados com os conceitos básicos necessários para aprofundar sua compreensão da estatística avançada.
- Começaremos relembrando as medidas de tendência central, como a média, a mediana e a moda, bem como as medidas de dispersão, como a variância e o desvio padrão. Discutiremos suas definições, propriedades e interpretações, além de explorar técnicas para calcular essas medidas a partir de dados observados. Além de discutir suas definições e cálculos, vamos explorar exemplos práticos com a linguagem Python, ilustrando sua aplicação em diferentes contextos. Você será capaz de entender como essas medidas resumem características importantes dos dados e como interpretá-las corretamente.
- Em seguida, abordaremos os conceitos fundamentais de probabilidade, que desempenham um papel crucial na estatística, e sua importância. Discutiremos as diferentes interpretações da probabilidade, como a frequentista, a subjetiva e outras abordagens modernas. Exploraremos as principais regras e propriedades da probabilidade, como a regra da adição e a regra da multiplicação, que são essenciais para a formulação e construção de modelos estatísticos sólidos.
- Em seguida, aprofundaremos nosso entendimento sobre distribuições estatísticas. Você será capaz de reconhecer diferentes tipos de distribuições e entender suas características fundamentais, como a forma da curva, os parâmetros relevantes e os momentos. Discutiremos as distribuições discretas, como a distribuição binomial e a distribuição de Poisson, bem como as distribuições contínuas, como a distribuição normal e a distribuição exponencial. Ao invés de nos atermos apenas às definições formais, buscaremos exemplos práticos para ilustrar a aplicação dessas distribuições em problemas do mundo real. Serão abordados conceitos como função de densidade de probabilidade, função de distribuição acumulada, momentos e características das distribuições.
- Avançando na revisão, exploraremos os conceitos de intervalos de confiança adequados para as amostras e testes de hipóteses, de forma criteriosa, que são fundamentais para realização de inferências estatísticas, com atenção às decisões práticas que podem ser tomadas com base nos resultados obtidos. Em vez de focar apenas nas fórmulas e procedimentos, enfatizaremos a interpretação prática dessas técnicas estatísticas. Exploraremos o conceito de estimativa pontual e estimativa por intervalo, bem como as etapas para construir um intervalo de confiança para uma determinada população. Em relação aos testes de hipóteses, discutiremos a formulação de hipóteses nulas e alternativas, a escolha do nível de significância e a interpretação dos resultados.
- Por fim, abordaremos técnicas de análise exploratória de dados, que são essenciais para entender e descrever os conjuntos de dados antes de aplicarmos técnicas mais avançadas. Exploraremos gráficos e visualizações, como histogramas, gráficos de dispersão e boxplots, que nos ajudam a identificar padrões, tendências e anomalias nos dados. Ao invés de apresentar uma lista de gráficos e visualizações, nos concentraremos na interpretação dos padrões e nas conclusões que podem ser extraídas. Você aprenderá a identificar tendências, discrepâncias e insights ocultos nos dados, capacitando-o a explorar plenamente o potencial informativo de suas análises estatísticas.
Ao concluir esta seção, os leitores terão revisado e consolidado conceitos-chave fundamentais da estatística, fornecendo uma base sólida para a compreensão dos tópicos avançados que serão abordados no restante do curso.
É importante ter um entendimento claro desses conceitos fundamentais, pois eles serão referência ao longo de toda a obra.
Ao invés de nos atermos apenas às definições formais, buscaremos exemplos práticos para ilustrar a aplicação dessas distribuições em problemas do mundo real.
Esquema da revisão:
Medidas:
Probabilidades:
Distribuições:
Testes:
Intervalos de confiança:
1.2.1 - Medidas de tendência central
1.2.2 - Medidas de dispersão
1.2.3 - Probabilidade
1.2.4 - Distribuições estatísticas
Aprofundaremos nosso entendimento sobre as distribuições estatísticas, um tema central na estatística avançada em que você será capaz de reconhecer diferentes tipos de distribuições, e entender suas características fundamentais, como a forma da curva, os parâmetros relevantes e os momentos.
As distribuições estatísticas descrevem o comportamento de variáveis aleatórias e fornecem informações valiosas sobre a probabilidade de diferentes resultados em um conjunto de dados.
- Distribuições Discretas: são aplicadas a variáveis aleatórias discretas, ou seja, variáveis que assumem apenas um conjunto enumerável de valores.
- Distribuição Binomial: modela eventos binários, como o sucesso ou fracasso em uma série de experimentos independentes. Veremos como calcular a probabilidade de obter um número específico de sucessos em um número fixo de tentativas e como utilizar essa distribuição em situações práticas, como estimar a probabilidade de sucesso em testes de produtos ou em pesquisas de opinião.
- Distribuição de Poisson: amplamente utilizada para modelar a ocorrência de eventos raros em um intervalo de tempo ou espaço fixo. Exploraremos exemplos práticos dessa distribuição, como:
- Cálculo da probabilidade de ocorrer um número específico de eventos em um determinado período de tempo.
- A quantidade de chamadas recebidas em um call center.
- O número de acidentes de trânsito em uma determinada área.
- Distribuições Contínuas: são aplicadas a variáveis aleatórias contínuas, ou seja, variáveis que podem assumir qualquer valor dentro de um intervalo contínuo.
- Distribuição Normal: também conhecida como distribuição de Gauss, é uma das distribuições mais importantes e amplamente utilizadas na estatística. Discutiremos as propriedades fundamentais dessa distribuição, como a:
- Forma da curva em formato de sino
- Simetria em torno da média
- Desvio padrão como medida de dispersão inclusive explorando exemplos como a modelagem de dados de altura, peso ou tempo de reação em experimentos científicos.
- Distribuição exponencial: descreve o tempo entre eventos sucessivos em um processo de Poisson. Essa distribuição é frequentemente aplicada em problemas de tempo de vida ou de espera, como a estimativa do tempo médio de vida de um equipamento eletrônico ou a análise do tempo médio de espera em uma fila de atendimento.
Ao invés de nos atermos apenas às definições formais, buscaremos enfatizar a aplicação prática dessas distribuições em problemas do mundo real.
Você será capaz de reconhecer diferentes tipos de distribuições, entender suas características fundamentais e utilizar essas ferramentas para analisar e interpretar dados.
Compreender as distribuições estatísticas é essencial para o desenvolvimento de modelos estatísticos robustos e para tomar decisões informadas com base na incerteza presente nos dados observados.
- Função de densidade de probabilidade (PDF - Probability Density Function): função matemática que descreve a distribuição de probabilidade de uma variável aleatória contínua, fornecendo a probabilidade de um valor específico ocorrer dentro de um intervalo contínuo. É representada graficamente por uma curva, em que a área sob a curva em um intervalo corresponde à probabilidade de ocorrência nesse intervalo. A integral da função de densidade de probabilidade em um intervalo específico fornece a probabilidade de a variável aleatória assumir valores dentro desse intervalo.
- Função de distribuição acumulada (CDF - Cumulative Density Function): função importante associada a uma variável aleatória, sendo definida como a probabilidade de que a variável aleatória seja menor ou igual a um determinado valor. É contínua e crescente, variando de 0 a 1 à medida que o valor da variável aleatória aumenta, fornecendo uma visão mais abrangente da distribuição de probabilidade e permitindo calcularmos a probabilidade acumulada até um certo valor.
- Momentos de uma distribuição (DM - Distribution Moments): medidas estatísticas utilizadas para descrever as características de uma distribuição de probabilidade, calculando-se medidas como a média, a variância, o desvio padrão e a simetria de uma distribuição. O momento de uma distribuição é uma medida estatística que descreve a forma e a localização da distribuição. O momento de ordem n de uma variável aleatória é calculado a partir dos valores da variável aleatória elevados à potência n, ponderados pela sua probabilidade de ocorrência.
As características de uma distribuição são propriedades importantes que ajudam a entender seu comportamento. Algumas das características comuns de uma distribuição incluem:
- Forma da curva: descreve o padrão de variação dos valores da variável aleatória, como uma curva em formato de sino na distribuição normal.
- Simetria: indica se a distribuição é simétrica em torno de um ponto central, como a distribuição normal.
- Centralidade: é representada pela média ou mediana da distribuição, fornecendo uma medida de tendência central.
- Dispersão: refere-se à variação dos valores em relação à medida central, comumente medida pela variância ou desvio padrão.
Ao compreender e explorar esses conceitos, podemos analisar e interpretar melhor as distribuições estatísticas e aplicá-las em problemas do mundo real.
Essas medidas estatísticas nos permitem resumir e quantificar as características das distribuições, o que é essencial para a análise estatística e a tomada de decisões informadas.
1.2.4.1 - Distribuições discretas
As distribuições discretas são um tipo de distribuição estatística em que a variável aleatória assume apenas valores discretos, geralmente inteiros. Isso significa que a distribuição descreve a probabilidade de ocorrência de valores específicos da variável aleatória.
Existem várias distribuições discretas comumente usadas na análise estatística. Algumas das distribuições discretas mais importantes incluem:
- Distribuição de Bernoulli: A distribuição de Bernoulli modela um único experimento com dois resultados possíveis, geralmente rotulados como sucesso (evento de interesse) e falha. Ela é caracterizada por um parâmetro p, que representa a probabilidade de sucesso. A função de probabilidade de uma distribuição de Bernoulli é dada por: $P(X = x)$ = $p^x(1-p)^{(1-x)}$, onde $x = 0$ ou $x = 1$.
- Distribuição Binomial: A distribuição binomial modela o número de sucessos em uma sequência de experimentos independentes de Bernoulli, cada um com a mesma probabilidade de sucesso p. Ela é caracterizada por dois parâmetros: o número de experimentos n e a probabilidade de sucesso p. A função de probabilidade de uma distribuição binomial é dada por: $P(X = k)$ = $C(n, k)$ $p^k(1-p)^{(n-k)}$, onde $X$ é o número de sucessos, $k$ é um valor entre 0 e n, e $C(n, k)$ é o coeficiente binomial.
- Distribuição de Poisson: A distribuição de Poisson modela a ocorrência de eventos raros em um intervalo de tempo ou espaço fixo. Ela é caracterizada por um parâmetro λ, que representa a taxa média de ocorrência dos eventos. A função de probabilidade de uma distribuição de Poisson é dada por: $P(X = k)$ = $\frac{e^{-λ}λ^k}{k!}$, onde $X$ é o número de ocorrências do evento, $k$ é um valor inteiro não negativo, e $e$ é a base do logaritmo natural.
- Distribuição Geométrica: A distribuição geométrica modela o número de tentativas até o primeiro sucesso em uma sequência de experimentos independentes de Bernoulli, cada um com a mesma probabilidade de sucesso p. Ela é caracterizada por um parâmetro p, que representa a probabilidade de sucesso. A função de probabilidade de uma distribuição geométrica é dada por: $P(X = k) = (1-p)^{(k-1)}.p$, onde $X$ é o número de tentativas até o primeiro sucesso e $k$ é um valor inteiro positivo.
Essas são apenas algumas das distribuições discretas mais comuns. Cada distribuição tem suas próprias características e aplicações específicas. Para calcular probabilidades e realizar análises estatísticas usando distribuições discretas, você pode usar bibliotecas estatísticas como o NumPy ou o SciPy em Python, que fornecem funções para trabalhar com essas distribuições e realizar cálculos relevantes.
1.2.4.2 - Distribuição binomial
A distribuição binomial é um tipo de distribuição discreta que modela o número de sucessos em uma sequência de experimentos independentes, cada um com dois resultados possíveis (geralmente rotulados como sucesso e falha). Essa distribuição é amplamente utilizada para analisar eventos binários, como o lançamento de uma moeda, o sucesso ou falha de um produto, entre outros.
A distribuição binomial é caracterizada por dois parâmetros: o número de experimentos n e a probabilidade de sucesso em cada experimento p. O número de experimentos n define o tamanho da sequência de experimentos independentes, enquanto a probabilidade de sucesso p representa a chance de um único experimento resultar em sucesso.
A função de probabilidade da distribuição binomial é dada por: $P(X = k)$ = $C(n,k)$ $p^k (1-p)^{(n-k)}$, onde $X$ é o número de sucessos, $k$ é um valor entre 0 e n, $C(n,k)$ é o coeficiente binomial, dado por $C(n,k) = \frac{n!}{k!(n-k)!}$, e $p^k(1-p)^{n-k}$ é a probabilidade de exatamente $k$ sucessos em $n$ experimentos.
Além da função de probabilidade, a distribuição binomial também possui outras características importantes, como a média e a variância.
A média da distribuição binomial é dada por: $μ = n p$, onde $n$ é o número de experimentos e $p$ é a probabilidade de sucesso, e a variância é dada por: $σ^2 = n p (1-p)$.
Essas fórmulas fornecem uma estimativa do valor médio esperado e da dispersão dos resultados em uma distribuição binomial.
Para calcular probabilidades, realizar análises estatísticas ou gerar amostras aleatórias seguindo uma distribuição binomial, você pode usar bibliotecas estatísticas em Python, como o NumPy ou o SciPy. Essas bibliotecas oferecem funções específicas para trabalhar com a distribuição binomial, como a função binom.pmf() para calcular a função de probabilidade, a função binom.mean() para obter a média e a função binom.rvs() para gerar amostras aleatórias.
1.2.4.3 - Distribuição de Poisson
A distribuição de Poisson é uma distribuição de probabilidade discreta que modela o número de eventos que ocorrem em um intervalo de tempo ou em uma região espacial fixa, quando esses eventos ocorrem de forma independente e a uma taxa média conhecida.
Essa distribuição é amplamente utilizada em estatística para descrever a ocorrência de eventos raros, como chamadas telefônicas em um call center, acidentes de trânsito em uma determinada área ou falhas em um sistema. Ela foi nomeada em homenagem a Siméon-Denis Poisson, um matemático francês que a introduziu no início do século XIX.
Os principais pontos da distribuição de Poisson são os seguintes:
- Parâmetro lambda (λ): É a taxa média de ocorrência dos eventos em um intervalo fixo. Representa o número médio de eventos que se espera ocorrer em uma unidade de tempo ou espaço. Por exemplo, se você sabe que ocorrem, em média, 5 acidentes de trânsito por dia em uma determinada área, λ seria igual a 5.
- Variável aleatória (X): Representa o número de eventos que ocorrem nesse intervalo de tempo ou espaço. Pode assumir valores inteiros não negativos (0, 1, 2, 3, ...) e segue uma distribuição de Poisson.
A função de probabilidade da distribuição de Poisson é dada por: $P(X = k) = \frac{(e^{-λ} . λ^k)}{k!}$, onde $e$ é a base do logaritmo natural (aproximadamente 2,71828), $λ$ é o parâmetro de taxa média de ocorrência, $k$ é o número de eventos que queremos calcular a probabilidade. Essa fórmula permite calcular a probabilidade de ocorrer exatamente $k$ eventos em um intervalo específico, dado um valor $λ$. Além disso, a distribuição de Poisson também possui algumas propriedades interessantes, como a independência dos intervalos não sobrepostos e a soma de variáveis aleatórias de Poisson com a mesma taxa média resultando em outra variável de Poisson com uma taxa média igual à soma das taxas médias individuais.
A distribuição de Poisson é frequentemente utilizada como uma aproximação para modelos mais complexos quando as condições necessárias para sua aplicação são atendidas. É uma ferramenta valiosa em áreas como a teoria das filas, processos estocásticos e análise de dados discretos.
1.2.4.4 - Distribuições contínuas
As distribuições contínuas são um tipo de distribuição de probabilidade em que as variáveis aleatórias podem assumir valores em um intervalo contínuo, ao contrário das distribuições discretas, onde as variáveis aleatórias assumem valores específicos. Nas distribuições contínuas, a função de probabilidade é descrita pela função de densidade de probabilidade (PDF, do inglês Probability Density Function).
A função de densidade de probabilidade descreve a probabilidade relativa de que a variável aleatória assuma um determinado valor dentro de um intervalo contínuo. A área sob a curva da PDF em um intervalo específico representa a probabilidade de a variável aleatória cair dentro desse intervalo.
Existem várias distribuições contínuas importantes, cada uma com suas características distintas. Vou detalhar algumas das distribuições contínuas mais comuns:
- Distribuição Uniforme: nesta distribuição, todos os valores dentro de um intervalo têm a mesma probabilidade de ocorrência. A PDF é uma função constante dentro do intervalo e zero fora dele.
- Distribuição Normal (ou Gaussiana): a distribuição normal é uma das mais importantes e amplamente utilizadas. É caracterizada por sua forma de sino simétrica em torno de um valor médio. A PDF é descrita pela equação da curva gaussiana, que depende do valor médio (μ) e do desvio padrão (σ). A maioria dos fenômenos naturais segue uma distribuição normal.
- Distribuição Exponencial: é frequentemente usada para modelar o tempo entre eventos em um processo de decaimento. A distribuição exponencial é caracterizada por ter uma taxa de ocorrência constante ao longo do tempo. A PDF é decrescente exponencialmente.
- Distribuição de Weibull: é uma distribuição flexível que pode modelar uma variedade de padrões de falha. É frequentemente usada para analisar a confiabilidade e tempo de vida de produtos e sistemas. A PDF de Weibull pode ter formas variáveis, incluindo exponencial, normal e crescente.
- Distribuição de Cauchy: é uma distribuição com caudas longas e pesadas. É conhecida por não ter média ou variância definidas. A PDF de Cauchy possui um pico no centro, mas suas caudas se estendem indefinidamente.
Essas são apenas algumas das distribuições contínuas mais comuns. Existem muitas outras, como a distribuição log-normal, a distribuição gamma, a distribuição beta, entre outras. Cada distribuição tem propriedades específicas e é útil para modelar diferentes tipos de fenômenos em várias áreas da ciência, estatística e engenharia.
1.2.4.5 - Distribuição normal
A distribuição normal, também conhecida como distribuição gaussiana, é uma das distribuições de probabilidade mais importantes e amplamente utilizadas na estatística e em diversas áreas do conhecimento. Ela descreve muitos fenômenos naturais e aleatórios, além de ser a base para muitas técnicas estatísticas e modelos matemáticos.
Características da distribuição normal:
- Forma de sino simétrica: a distribuição normal tem uma forma de sino simétrica em torno de um valor médio.
- Média e mediana iguais: a média, mediana e moda estão todas localizadas no mesmo ponto, no centro da distribuição.
- Curva contínua: a PDF (Probability Density Function) da distribuição normal é uma curva contínua, sem saltos ou descontinuidades.
- Parâmetros: a distribuição normal é completamente definida por dois parâmetros: a média (μ) e o desvio padrão (σ). A média especifica a localização central da distribuição, enquanto o desvio padrão controla a dispersão dos dados em torno da média.
A função de densidade de probabilidade (PDF) da distribuição normal é dada pela conhecida equação da curva gaussiana: $f(x) = \frac{1}{σ\sqrt{2π}} . e^{\frac{-(x - μ)^2}{2σ^2}}$, onde $f(x)$ é a densidade de probabilidade de obter um valor x na distribuição, $μ$ é a média da distribuição, $σ$ é o desvio padrão da distribuição, $π$ é a constante matemática pi (aproximadamente igual a 3.14159) e $e$ é o número neperiano.
Essa equação permite calcular a probabilidade de que uma variável aleatória siga uma distribuição normal em um determinado ponto x da curva.
A distribuição normal é caracterizada por algumas propriedades úteis, como:
- Simetria: a distribuição é simétrica em torno da média, o que significa que a mesma proporção de valores está à esquerda e à direita da média.
- Regra Empírica: aproximadamente 68% dos dados estão dentro de um desvio padrão da média, 95% estão dentro de dois desvios padrão e 99,7% estão dentro de três desvios padrão.
- Transformações lineares: a soma de várias variáveis aleatórias independentes normalmente distribuídas também segue uma distribuição normal. Além disso, uma combinação linear de variáveis aleatórias normalmente distribuídas também é normal.
- Teorema Central do Limite: a soma de um grande número de variáveis aleatórias independentes, independentemente de suas distribuições originais, tende a seguir uma distribuição normal.
A distribuição normal é amplamente utilizada em análise estatística, inferência, modelagem de dados e em várias áreas da pesquisa científica. Ela desempenha um papel fundamental em testes de hipóteses, intervalos de confiança, regressão linear, análise de dados multivariados, entre outros.
1.2.4.6 - Distribuição exponencial
A distribuição exponencial é uma distribuição contínua de probabilidade que é amplamente utilizada para modelar o tempo entre eventos sucessivos de um processo de Poisson. Ela é frequentemente aplicada em áreas como teoria das filas, análise de confiabilidade, tempo de vida de produtos e sistemas, entre outras.
Principais características da distribuição exponencial:
- Tempo entre eventos: a distribuição exponencial é usada para modelar o tempo entre eventos sucessivos que ocorrem em uma taxa média constante.
- Decaimento exponencial: a função de densidade de probabilidade (PDF) da distribuição exponencial apresenta um decaimento exponencial. Ela é caracterizada por ser positiva e decrescente.
- Parâmetro lambda (λ): a distribuição exponencial é definida por um único parâmetro, λ (lambda), que representa a taxa média de ocorrência dos eventos. O inverso de lambda (1/λ) é o valor esperado do tempo entre eventos.
- Probabilidade constante: ao contrário de outras distribuições, como a distribuição normal, a distribuição exponencial não possui memória. Isso significa que a probabilidade de um evento ocorrer em um determinado intervalo de tempo é a mesma, independentemente de quanto tempo já se passou.
A função de densidade de probabilidade (PDF) da distribuição exponencial é dada por: $f(x) = λ e^{-λ x}$, onde $f(x)$ é a densidade de probabilidade de obter um valor $x$ na distribuição, $λ$ é o parâmetro de taxa média de ocorrência dos eventos e $e$ é o número neperiano.
Essa função fornece a probabilidade de que uma variável aleatória siga uma distribuição exponencial e tenha um valor específico x.
Algumas propriedades importantes da distribuição exponencial são:
- Falta de memória: a distribuição exponencial é caracterizada por não possuir memória. Isso significa que a probabilidade de um evento ocorrer em um determinado intervalo de tempo é a mesma, independentemente de quanto tempo já se passou.
- Tempo médio de vida: o tempo médio entre eventos consecutivos em uma distribuição exponencial é igual a 1/λ. Isso significa que a expectativa de tempo até o próximo evento é o inverso da taxa média de ocorrência dos eventos.
- Soma de variáveis exponenciais: a soma de várias variáveis aleatórias independentes com distribuição exponencial também segue uma distribuição exponencial. A taxa média da soma é a soma das taxas médias das variáveis individuais.
A distribuição exponencial é amplamente utilizada em modelagem e análise de dados quando se lida com eventos raros e aleatórios que ocorrem em uma taxa média constante. Ela fornece uma representação matemática útil para esses cenários e possui várias propriedades convenientes para análise estatística.
1.2.4.7 - Funções, métodos e técnicas de distribuição estatística
Vamos detalhar sobre funções, métodos e técnicas de distribuição estatística que são comumente utilizados na análise e modelagem de dados.
- Funções de distribuição acumulada (CDF): descreve a probabilidade de uma variável aleatória ser menor ou igual a um determinado valor. Ela é denotada como F(x) e é definida para todas as distribuições estatísticas. A partir da CDF, é possível calcular probabilidades, quantis e realizar testes de hipóteses.
- Funções de densidade de probabilidade (PDF): descreve a probabilidade de uma variável aleatória assumir um determinado valor. Ela é usada em distribuições contínuas, como a distribuição normal e a distribuição exponencial, e é denotada como f(x). A área sob a curva da PDF em um intervalo específico representa a probabilidade de a variável aleatória cair dentro desse intervalo.
- Funções de sobrevivência: complementar à CDF, e descreve a probabilidade de uma variável aleatória ser maior do que um determinado valor. Ela é denotada como S(x) e é usada principalmente em análise de confiabilidade e tempo de vida, como na distribuição exponencial.
- Funções de quantil: usadas para determinar os valores correspondentes a um determinado percentil ou probabilidade em uma distribuição estatística. Por exemplo, o quantil de 0,5 (ou mediana) divide a distribuição ao meio, com 50% dos valores abaixo e 50% acima desse ponto.
- Métodos de ajuste de distribuição: são utilizados para encontrar a distribuição estatística que melhor se ajusta a um conjunto de dados observados. Esses métodos permitem determinar os parâmetros ótimos da distribuição que melhor descrevem os dados. Alguns métodos comuns incluem o método dos momentos, o método da máxima verossimilhança e o método dos quantis.
- Testes de aderência: usados para avaliar se uma distribuição estatística específica se ajusta bem aos dados observados. Esses testes comparam as características dos dados observados com as características esperadas da distribuição. Alguns testes comuns são o teste de Kolmogorov-Smirnov, o teste qui-quadrado e o teste de Anderson-Darling.
- Técnicas de amostragem: envolvem a seleção de uma amostra representativa de uma população maior. Diferentes métodos de amostragem, como amostragem aleatória simples, amostragem estratificada, amostragem sistemática, entre outros, são usados para garantir que a amostra seja representativa e que os resultados obtidos possam ser generalizados para a população.
Essas são apenas algumas das principais funções, métodos e técnicas de distribuição estatística. Cada uma delas desempenha um papel importante na análise, descrição e modelagem de dados. A escolha da técnica adequada depende do tipo de dados, do objetivo da análise e do contexto específico da aplicação.
1.2.4.8 - Função de densidade de probabilidade (PDF)
A função de densidade de probabilidade (PDF - Probability Density Function), também conhecida como função de probabilidade, é uma função que descreve a distribuição de probabilidade de uma variável aleatória contínua. Ela é usada para determinar a probabilidade de uma variável aleatória assumir valores em um intervalo específico.
A PDF é denotada por f(x), onde "x" é a variável aleatória, satisfazendo as seguintes propriedades:
- A PDF é sempre não negativa: f(x) >= 0 para todos os valores de x.
- A área total sob a curva da PDF é igual a 1: ∫f(x)dx = 1, onde a integral é tomada em todos os possíveis valores da variável aleatória.
- A PDF fornece informações sobre a forma e a distribuição dos valores possíveis de uma variável aleatória contínua. A partir dessa função, podemos derivar várias estatísticas descritivas, como média, mediana, variância, desvio padrão, entre outras.
É importante observar que a PDF é específica para cada distribuição estatística. Diferentes distribuições têm formas de PDF distintas, como a distribuição normal, a distribuição exponencial, a distribuição de Poisson, entre outras. Cada uma dessas distribuições tem uma PDF própria que descreve a forma como os valores estão distribuídos ao longo do eixo x.
A PDF é uma ferramenta essencial na análise estatística, permitindo modelar e compreender as distribuições de variáveis aleatórias contínuas. Ela é utilizada em uma ampla gama de aplicações, desde a inferência estatística até a modelagem de fenômenos complexos em diversas áreas, como ciências naturais, economia, engenharia, entre outras.
Em termos de código Python, é possível utilizar bibliotecas como o SciPy e o matplotlib para plotar a PDF de diferentes distribuições estatísticas. Por exemplo, para plotar a PDF de uma distribuição normal, podemos usar o seguinte código:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# Parâmetros da distribuição normal
mu = 0 # média
sigma = 1 # desvio padrão
# Valores de x para plotagem da função de densidade de probabilidade
x = np.linspace(-5, 5, 100)
# Calcula a PDF da distribuição normal
pdf = norm.pdf(x, mu, sigma)
# Plota a PDF
plt.plot(x, pdf)
plt.xlabel('x')
plt.ylabel('f(x)')
plt.title('Função de Densidade de Probabilidade (Distribuição Normal)')
plt.grid(True)
plt.show()
Nesse exemplo, utilizamos a biblioteca SciPy para calcular a PDF da distribuição normal (norm.pdf) e a biblioteca matplotlib para plotar o gráfico da função. É possível adaptar o código para outras distribuições estatísticas, alterando os parâmetros e a função correspondente da biblioteca SciPy.
1.2.4.9 - Função de distribuição acumulada
A função de distribuição acumulada (FDA), também conhecida como função de distribuição cumulativa, é uma função que descreve a probabilidade acumulada de uma variável aleatória assumir um valor menor ou igual a um determinado ponto.
A função de distribuição acumulada é denotada por F(x) e é definida para todos os valores de x. Para uma variável aleatória contínua, a função de distribuição acumulada é definida como a integral da função de densidade de probabilidade (PDF) até o valor x: $F(x) = ∫f(t)dt$, para $-∞ < x < ∞$
A função de distribuição acumulada tem as seguintes propriedades:
- A função de distribuição acumulada é não decrescente: $F(x_1) ≤ F(x_2)$ se $x_1 ≤ x_2$.
- A função de distribuição acumulada é limitada: $0 ≤ F(x) ≤ 1$ para todos os valores de $x$.
- A função de distribuição acumulada converge para 0 quando $x$ tende ao menos infinito: $F(x)_{lim(x→∞)} = 0$.
- A função de distribuição acumulada converge para 1 quando x tende ao mais infinito: $F(x)_{lim(x→∞)} = 1$.
A função de distribuição acumulada fornece informações sobre a probabilidade acumulada de observar valores menores ou iguais a um determinado ponto na distribuição. Por exemplo, se F(x) = 0,25, isso significa que há uma probabilidade de 25% de observar valores menores ou iguais a x.
A partir da função de distribuição acumulada, podemos calcular diversas medidas estatísticas, como a mediana m (ponto em que F(x) = 0,5), o percentil p (ponto em que F(x) = p/100) e o quartil q (ponto em que F(x) = q/4).
Em Python, é possível utilizar bibliotecas como o SciPy e o matplotlib para calcular e plotar a função de distribuição acumulada de diferentes distribuições estatísticas. Por exemplo, para plotar a função de distribuição acumulada de uma distribuição normal, podemos usar o seguinte código:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# Parâmetros da distribuição normal
mu = 0 # média
sigma = 1 # desvio padrão
# Valores de x para plotagem da função de distribuição acumulada
x = np.linspace(-5, 5, 100)
# Calcula a função de distribuição acumulada da distribuição normal
cdf = norm.cdf(x, mu, sigma)
# Plota a função de distribuição acumulada
plt.plot(x, cdf)
plt.xlabel('x')
plt.ylabel('F(x)')
plt.title('Função de Distribuição Acumulada (Distribuição Normal)')
plt.grid(True)
plt.show()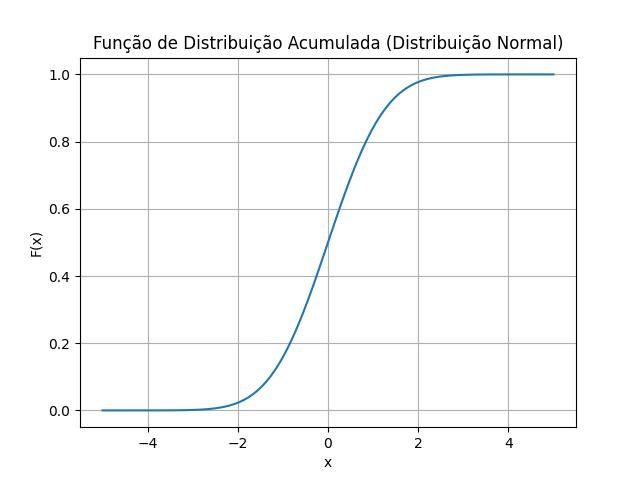
Nesse exemplo, utilizamos a biblioteca SciPy para calcular a função de distribuição acumulada da distribuição normal (norm.cdf) e a biblioteca matplotlib para plotar o gráfico da função. É possível adaptar o código para outras distribuições estatísticas, alterando os parâmetros e a função correspondente da biblioteca SciPy.
1.2.4.10 - Momentos de uma distribuição
Os momentos de uma distribuição são medidas estatísticas que fornecem informações sobre as características e forma da distribuição. Eles são calculados a partir dos valores da variável aleatória e podem ajudar a descrever propriedades como a tendência central, dispersão, assimetria e curtose da distribuição.
Existem diferentes tipos de momentos que podem ser calculados para uma distribuição. Os principais momentos são:
- Primeiro Momento: O primeiro momento de uma distribuição é a média, que representa a tendência central da distribuição. É calculado como a soma dos valores da variável aleatória dividida pelo número total de observações.
- Segundo Momento: O segundo momento de uma distribuição é a variância, que mede a dispersão dos valores em relação à média. A variância é calculada como a média dos quadrados das diferenças entre cada valor e a média.
- Terceiro Momento: O terceiro momento de uma distribuição é a assimetria, que indica a tendência da distribuição de se desviar de uma distribuição simétrica. A assimetria é calculada como a média dos cubos das diferenças entre cada valor e a média, normalizada pela variância ao cubo.
- Quarto Momento: O quarto momento de uma distribuição é a curtose, que mede o grau de achatamento ou apontamento da distribuição em relação à distribuição normal. A curtose é calculada como a média dos quartos poderes das diferenças entre cada valor e a média, normalizada pela variância elevada à quarta potência.
Os momentos podem ser calculados usando funções específicas em bibliotecas de análise estatística, como o NumPy ou o SciPy, em Python. Por exemplo, para calcular a média e a variância de uma lista de valores usando o NumPy, podemos usar o seguinte código:
import numpy as np
# Lista de valores
valores = [2, 4, 6, 8, 10]
# Cálculo da média
media = np.mean(valores)
# Cálculo da variância
variancia = np.var(valores)
print("Média:", media)
print("Variância:", variancia)Para calcular a assimetria e a curtose, o NumPy também possui funções específicas, skew() e kurtosis(), respectivamente:
import numpy as np
from scipy.stats import skew
from scipy.stats import kurtosis
# Lista de valores
valores = [2, 4, 6, 8, 10]
# Cálculo da assimetria
assimetria = skew(valores)
# Cálculo da curtose
curtose = kurtosis(valores)
print("Assimetria:", assimetria)
print("Curtose:", curtose)Esses são exemplos simples de cálculos de momentos utilizando o NumPy. As bibliotecas de análise estatística oferecem uma ampla variedade de funções para calcular momentos e outras medidas estatísticas, permitindo uma análise mais detalhada das distribuições.
1.2.5 - Intervalos de confiança e testes de hipóteses
1.2.6 - Testes de hipóteses
1.2.7 - Gráficos e visualizações
Gráficos e visualizações desempenham um papel fundamental na análise exploratória de dados, permitindo identificar padrões, tendências e anomalias de forma visualmente intuitiva.
Dentre as diversas opções disponíveis, alguns dos gráficos mais comumente utilizados incluem histogramas, gráficos de dispersão e boxplots.
- Histogramas: gráficos que representam a distribuição de frequências de uma variável contínua, consistindo em barras adjacentes, onde a altura de cada barra representa a frequência ou a densidade de ocorrência de valores dentro de um intervalo específico, permitindo visualizar a forma da distribuição dos dados, identificar a presença de picos ou assimetrias e observar a concentração dos valores em determinadas regiões. Essas informações são úteis para entender a distribuição dos dados e identificar possíveis padrões ou discrepâncias.
- Gráficos de dispersão: são utilizados para investigar a relação entre duas variáveis contínuas, apresentando os valores de uma variável no eixo horizontal e os valores correspondentes da outra variável no eixo vertical. Cada ponto no gráfico representa uma observação. Os gráficos de dispersão permitem visualizar a presença de padrões ou tendências lineares, bem como a dispersão dos dados em torno da tendência. Também podem ser usados para identificar valores atípicos ou anomalias que se desviem da tendência geral.
- Boxplots: também conhecidos como diagramas de caixa, fornecem uma representação visual compacta das principais estatísticas descritivas de uma variável, incluindo a mediana, os quartis e os valores mínimo e máximo. São úteis para comparar distribuições e identificar diferenças nos valores centrais, bem como a presença de valores extremos. Além disso, boxplots permitem detectar assimetrias e avaliar a variabilidade dos dados de forma intuitiva.
Além desses gráficos, existem diversas outras visualizações disponíveis, como gráficos de barras, gráficos de linha, gráficos de pizza, gráficos de áreas, entre outros.
Cada tipo de gráfico possui suas próprias características e é adequado para diferentes tipos de dados e propósitos analíticos.
A escolha da visualização mais adequada depende da natureza dos dados e das perguntas específicas que se deseja responder.
Em suma, gráficos e visualizações são ferramentas poderosas para explorar dados, identificar padrões, tendências e anomalias, e comunicar informações de forma clara e impactante.
Ao utilizar essas representações visuais, é possível obter insights mais profundos sobre os dados e embasar decisões fundamentadas em evidências.
1.2.7.1 - Tendências, discrepâncias e insights sobre os dados
Os gráficos e visualizações desempenham um papel essencial na identificação de tendências, discrepâncias e insights ocultos nos dados.
Eles capacitam os analistas a explorar plenamente o potencial informativo das análises estatísticas, fornecendo uma representação visual dos padrões subjacentes aos dados.
Ao examinar os gráficos, é possível identificar tendências ao longo do tempo ou em relação a outras variáveis.
Por exemplo, um gráfico de linha pode mostrar uma tendência ascendente ou descendente, indicando um aumento ou diminuição consistente em uma determinada variável ao longo do tempo. Isso permite compreender as mudanças e padrões que ocorrem nos dados. Além das tendências, as visualizações também podem revelar discrepâncias ou desvios significativos dos padrões esperados.
Por exemplo, em um gráfico de dispersão, é possível identificar pontos isolados que se desviam da tendência geral, sugerindo valores atípicos ou anomalias que merecem investigação adicional. Essas discrepâncias podem fornecer insights valiosos sobre padrões incomuns ou eventos excepcionais nos dados. Além disso, as visualizações podem revelar insights ocultos, ou seja, informações que não seriam prontamente perceptíveis ao realizar apenas análises estatísticas.
Por exemplo, um gráfico de barras empilhadas pode mostrar a distribuição de uma variável em diferentes grupos, revelando diferenças significativas entre eles. Essas descobertas podem levar a novas perguntas de pesquisa ou orientar a tomada de decisões informadas. As visualizações também facilitam a comunicação de resultados complexos e informações estatísticas de forma clara e concisa, permitindo a apresentação visual de padrões e relacionamentos, tornando mais fácil para o público entender as conclusões e insights derivados das análises estatísticas.
As visualizações capacitam os analistas a explorar, interpretar e comunicar os dados de maneira eficaz, permitindo a identificação de tendências, discrepâncias e insights ocultos nos dados, fornecendo uma visão mais completa e significativa das informações. Ao combinar análises estatísticas com visualizações apropriadas, é possível extrair o máximo de valor dos dados e tomar decisões mais embasadas e informadas.
1.2.7.2 - Tipos de gráficos
Os gráficos e visualizações desempenham um papel fundamental na análise estatística, pois permitem a exploração, comunicação e interpretação dos dados de maneira visualmente atraente e informativa. Eles ajudam a identificar padrões, tendências, relações e discrepâncias nos dados, facilitando a compreensão e a tomada de decisões baseadas em evidências. Vou fornecer uma excelente resenha sobre os principais tipos de gráficos e visualizações utilizados na estatística:
- Gráfico de barras: usado para representar a distribuição de uma variável categórica. Cada categoria é representada por uma barra, cuja altura indica a frequência, proporção ou valor associado à categoria.
- Gráfico de colunas: semelhante ao gráfico de barras, mas as barras são dispostas na vertical em vez de horizontalmente.
- Gráfico de setores (ou gráfico de pizza): usado para representar a distribuição de uma variável categórica em forma de pizza. Cada categoria é representada por uma fatia, cuja área ou ângulo é proporcional à frequência, proporção ou valor associado à categoria.
- Histograma: usado para representar a distribuição de uma variável contínua. O eixo horizontal representa os intervalos de valores e o eixo vertical representa a frequência, proporção ou densidade. Os retângulos adjacentes são desenhados para representar a frequência ou proporção dos valores que caem dentro de cada intervalo.
- Gráfico de dispersão: usado para visualizar a relação entre duas variáveis numéricas. Cada ponto no gráfico representa uma observação com seus valores correspondentes nas duas variáveis. possível identificar padrões, tendências, correlações e outliers através do padrão geral dos pontos.
- Gráfico de linhas: usado para representar a tendência ou mudança ao longo do tempo ou de uma variável em relação a outra. Os pontos são conectados por linhas, mostrando a evolução da variável ao longo de uma sequência temporal ou uma variável independente.
- Gráfico de caixas (boxplot): usado para representar a distribuição de uma variável numérica em termos de seus quartis, mediana, valores mínimos e máximos e possíveis outliers. Ele fornece informações sobre a dispersão, assimetria e presença de valores extremos nos dados.
- Gráfico de área: usado para representar a distribuição ou acumulação de uma variável ao longo do tempo ou de uma sequência. A área abaixo da linha representa a quantidade acumulada ou a proporção da variável.
- Gráfico de dispersão com bolhas: uma variação do gráfico de dispersão onde cada ponto é representado por uma bolha com tamanho proporcional a um terceiro valor associado à observação. Isso permite representar três variáveis simultaneamente.
- Mapas e gráficos geoespaciais: São usados para representar dados em um contexto geográfico, associando-os a regiões, países ou pontos específicos em um mapa.
- Gráfico de área empilhada: uma variação do gráfico de área em que múltiplas séries de dados são empilhadas uma sobre a outra para mostrar a contribuição relativa de cada categoria ao todo.
- Gráfico de radar: usado para comparar múltiplas variáveis em relação a um conjunto comum de categorias. Os valores são representados como pontos em torno de um eixo central, permitindo a visualização dos padrões e diferenças entre as variáveis.
- Gráfico de Gantt: usado para representar o planejamento e o cronograma de atividades em projetos. As barras horizontais representam as tarefas e suas durações, permitindo visualizar a alocação de tempo e as dependências entre as atividades.
- Gráfico de bolhas: uma variação do gráfico de dispersão onde cada ponto é representado por uma bolha com tamanho e cor proporcional a um terceiro e quarto valor associados à observação. Isso permite representar quatro variáveis simultaneamente.
- Gráfico de Sankey: usado para representar fluxos e proporções entre diferentes categorias. As faixas ou setas largas são usadas para representar a magnitude do fluxo de uma categoria para outra.
- Gráfico de rede (network graph): usado para representar relacionamentos complexos entre elementos. Os nós representam os elementos, e as arestas conectam os nós para mostrar as conexões e interações entre eles.
- Gráfico de cascata (waterfall chart): usado para mostrar a contribuição de diferentes fatores para uma mudança em um valor inicial. Ele mostra como o valor inicial é aumentado ou diminuído por cada fator, permitindo visualizar o impacto cumulativo dos diferentes elementos.
- Gráfico de controle: usado para monitorar e controlar processos ao longo do tempo. Ele exibe limites de controle superiores e inferiores, bem como pontos de dados, permitindo a detecção de variações e desvios significativos do processo.
- Gráfico de densidade: usado para visualizar a distribuição de uma variável contínua como uma curva suave. Ele fornece uma representação mais suave da distribuição em comparação com o histograma.
- Gráfico de heat map: usado para representar a relação entre duas variáveis em uma matriz. As células são coloridas de acordo com o valor da relação, permitindo visualizar padrões e tendências.
Esses são apenas alguns exemplos dos muitos tipos de gráficos e visualizações que podem ser utilizados na análise estatística. A escolha do gráfico adequado depende dos dados em questão, do objetivo da análise e da mensagem que se deseja transmitir. É importante criar gráficos claros, precisos e esteticamente agradáveis, que facilitem a compreensão dos dados e destaquem as principais conclusões. As visualizações eficazes podem fornecer insights valiosos e facilitar a comunicação dos resultados de forma impactante e acessível.
1.2.7.2.1 - Gráfico de barras
O gráfico de barras é uma visualização que permite representar a distribuição de uma variável categórica por meio de barras retangulares. Cada categoria é representada por uma barra, cuja altura indica a frequência, proporção ou valor associado à categoria. É uma das visualizações mais comuns e úteis na estatística e na análise de dados.
Aqui estão os principais elementos de um gráfico de barras:
- Eixo x: eixo horizontal do gráfico, que representa as categorias. Cada categoria é posicionada ao longo desse eixo, geralmente com rótulos ou nomes identificando-as.
- Eixo y: eixo vertical do gráfico, que representa a escala numérica dos valores associados às categorias. Pode representar a frequência, proporção, contagem ou qualquer outra medida que seja relevante para a variável categórica.
- Barras: retângulos verticais que representam cada categoria. A altura da barra é proporcional ao valor associado à categoria. A largura das barras pode ser uniforme ou variar dependendo do design do gráfico.
- Rótulos: usados para identificar as categorias ao longo do eixo x e, possivelmente, para fornecer informações adicionais, como valores numéricos exatos ou porcentagens.
- Título: texto descritivo que resume o conteúdo do gráfico de barras. Geralmente está localizado na parte superior do gráfico.
- Legendas: usadas para descrever o significado das barras ou fornecer informações adicionais sobre as categorias. Por exemplo, se as barras representam diferentes grupos ou subcategorias, as legendas podem indicar a que cada grupo pertence.
- Grade: grade de linhas horizontais e/ou verticais que auxilia na leitura e interpretação das barras. Pode ser útil para alinhar visualmente as barras ou fornecer uma referência adicional para os valores representados.
- Cores: barras podem ser coloridas para distinguir visualmente as categorias ou para enfatizar certas informações. As cores podem ser usadas de forma consistente ou variar para cada categoria.
Os gráficos de barras são amplamente utilizados em diversas áreas, como estatística descritiva, análise exploratória de dados, apresentações de resultados e comparações entre categorias. Eles permitem identificar diferenças, padrões ou tendências nos dados categóricos de forma clara e intuitiva.
É importante ressaltar que a escolha adequada de um gráfico de barras depende do contexto e dos objetivos da análise. Além disso, é essencial fornecer uma legenda adequada e garantir que o gráfico esteja devidamente rotulado e dimensionado para uma interpretação precisa dos dados.
Vamos explicar como criar um gráfico de barras utilizando a biblioteca Matplotlib em Python. Para este exemplo, vamos supor que temos uma lista de categorias e seus respectivos valores. Vamos criar um gráfico de barras para representar essa informação.
Primeiro, você precisará instalar a biblioteca Matplotlib, caso ainda não a tenha instalado. Você pode fazer isso executando o seguinte comando no seu ambiente Python:
pip install matplotlibAqui está um exemplo de código para criar um gráfico de barras:
import matplotlib.pyplot as plt
# Dados das categorias e seus valores
categorias = ['Categoria 1', 'Categoria 2', 'Categoria 3', 'Categoria 4']
valores = [20, 35, 30, 15]
# Criar o gráfico de barras
plt.bar(categorias, valores)
# Personalizar o gráfico
plt.title('Gráfico de Barras')
plt.xlabel('Categorias')
plt.ylabel('Valores')
# Exibir o gráfico
plt.show()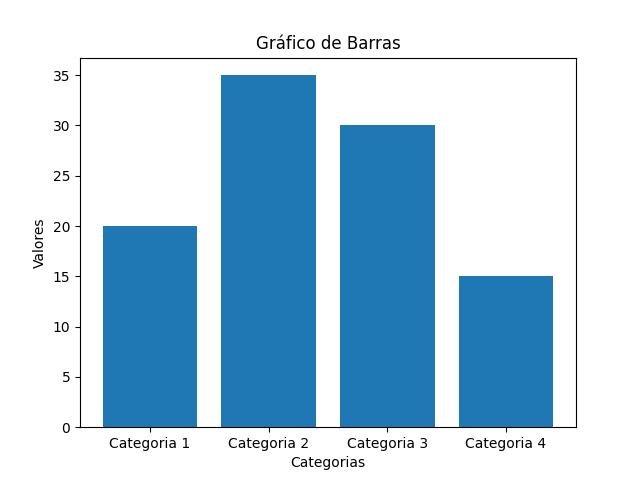
Neste exemplo, importamos o módulo pyplot da biblioteca Matplotlib como plt. Em seguida, definimos as categorias e valores que queremos representar no gráfico de barras.
Utilizamos a função plt.bar() para criar o gráfico de barras, passando as categorias e valores como argumentos. Em seguida, usamos as funções plt.title(), plt.xlabel() e plt.ylabel() para adicionar um título ao gráfico, e rótulos aos eixos x e y, respectivamente.
Por fim, utilizamos plt.show() para exibir o gráfico na tela.
Ao executar o código, você verá o gráfico de barras com as categorias no eixo x e os valores no eixo y. Você também pode personalizar ainda mais o gráfico, adicionando cores, legendas, grade, entre outros elementos, conforme necessário.
1.2.7.2.2 - Gráfico de colunas
O gráfico de colunas, também conhecido como gráfico de barras verticais, é uma visualização que permite representar a distribuição de uma variável categórica por meio de colunas retangulares. Cada categoria é representada por uma coluna, cuja altura indica a frequência, proporção ou valor associado à categoria. O gráfico de colunas é uma variação do gráfico de barras, em que as barras são dispostas verticalmente em vez de horizontalmente.
Aqui estão os principais elementos de um gráfico de colunas:
- Eixo x: eixo horizontal do gráfico, que representa as categorias. Cada categoria é posicionada ao longo desse eixo, geralmente com rótulos ou nomes identificando-as.
- Eixo y: eixo vertical do gráfico, que representa a escala numérica dos valores associados às categorias. Pode representar a frequência, proporção, contagem ou qualquer outra medida que seja relevante para a variável categórica.
- Colunas: retângulos verticais que representam cada categoria. A altura da coluna é proporcional ao valor associado à categoria. A largura das colunas pode ser uniforme ou variar dependendo do design do gráfico.
- Rótulos: usados para identificar as categorias ao longo do eixo x e, possivelmente, para fornecer informações adicionais, como valores numéricos exatos ou porcentagens.
- Título: texto descritivo que resume o conteúdo do gráfico de colunas. Geralmente está localizado na parte superior do gráfico.
- Legendas: usadas para descrever o significado das colunas ou fornecer informações adicionais sobre as categorias. Por exemplo, se as colunas representam diferentes grupos ou subcategorias, as legendas podem indicar a que cada grupo pertence.
- Grade: grade de linhas horizontais e/ou verticais que auxilia na leitura e interpretação das colunas. Pode ser útil para alinhar visualmente as colunas ou fornecer uma referência adicional para os valores representados.
- Cores: As colunas podem ser coloridas para distinguir visualmente as categorias ou para enfatizar certas informações. As cores podem ser usadas de forma consistente ou variar para cada categoria.
O gráfico de colunas é amplamente utilizado para representar e comparar a distribuição de categorias e seus valores associados. Ele é especialmente útil quando há muitas categorias a serem representadas ou quando se deseja destacar visualmente as diferenças entre as categorias.
Assim como no gráfico de barras, é importante garantir que o gráfico de colunas esteja devidamente rotulado, dimensionado e fornecer uma legenda adequada para facilitar a interpretação correta dos dados.
Aqui está um exemplo de código em Python utilizando a biblioteca Matplotlib para criar um gráfico de colunas:
import matplotlib.pyplot as plt
# Dados das categorias e seus valores
categorias = ['Categoria 1', 'Categoria 2', 'Categoria 3', 'Categoria 4']
valores = [20, 35, 30, 15]
# Criar o gráfico de colunas
plt.bar(categorias, valores)
# Personalizar o gráfico
plt.title('Gráfico de Colunas')
plt.xlabel('Categorias')
plt.ylabel('Valores')
# Exibir o gráfico
plt.show()
Neste exemplo, estamos utilizando a biblioteca Matplotlib para criar o gráfico de colunas. A lista categorias contém os rótulos das categorias e a lista valores contém os valores associados a cada categoria.
Utilizamos a função plt.bar() para criar o gráfico de colunas, passando as categorias e valores como argumentos. Em seguida, utilizamos as funções plt.title(), plt.xlabel() e plt.ylabel() para adicionar um título ao gráfico, e rótulos aos eixos x e y, respectivamente.
Por fim, utilizamos plt.show() para exibir o gráfico na tela.
Ao executar o código, você verá o gráfico de colunas com as categorias no eixo x e os valores no eixo y. Você também pode personalizar o gráfico adicionando cores, legendas, grade, entre outros elementos, conforme necessário.
1.2.7.2.3 - Gráfico de setores
O gráfico de setores, também conhecido como gráfico de pizza, é uma visualização que permite representar a distribuição de uma variável categórica por meio de setores de um círculo. Cada categoria é representada por um setor, cujo tamanho angular é proporcional à frequência, proporção ou valor associado à categoria.
Aqui estão os principais elementos de um gráfico de setores:
- Setores: São as fatias circulares que representam cada categoria. O tamanho angular de cada setor é proporcional ao valor associado à categoria. Quanto maior o valor, maior será o ângulo ocupado pelo setor.
- Rótulos: São usados para identificar as categorias dentro de cada setor. Os rótulos são posicionados próximos aos setores correspondentes e geralmente contêm o nome ou descrição da categoria, e possivelmente o valor associado.
- Título: É um texto descritivo que resume o conteúdo do gráfico de setores. Geralmente está localizado na parte central ou superior do gráfico.
- Legenda: É uma tabela ou lista que descreve o significado de cada setor, associando os rótulos das categorias aos valores representados. A legenda é útil para ajudar a identificar e interpretar os setores.
- Cores: Os setores podem ser coloridos para distinguir visualmente as categorias ou para enfatizar certas informações. É comum usar cores diferentes para cada setor, proporcionando uma distinção clara entre as categorias.
O gráfico de setores é comumente utilizado para representar a composição ou a distribuição relativa de diferentes categorias dentro de um todo. Ele é especialmente útil quando se deseja mostrar as proporções de cada categoria em relação ao total.
No entanto, é importante observar que o gráfico de setores pode ter algumas limitações na representação precisa dos dados. A interpretação correta dos setores requer uma boa compreensão dos ângulos e proporções, e é mais adequada quando se trabalha com um pequeno número de categorias distintas.
Aqui está um exemplo de código Python utilizando a biblioteca Matplotlib para criar um gráfico de setores:
import matplotlib.pyplot as plt
# Dados das categorias e seus valores
categorias = ['Categoria 1', 'Categoria 2', 'Categoria 3', 'Categoria 4']
valores = [20, 35, 30, 15]
# Criar o gráfico de setores
plt.pie(valores, labels=categorias)
# Personalizar o gráfico
plt.title('Gráfico de Setores')
# Exibir o gráfico
plt.show()
Neste exemplo, utilizamos a função plt.pie() para criar o gráfico de setores, passando os valores das categorias e os rótulos como argumentos. O gráfico é então personalizado com o título utilizando a função plt.title(), e é exibido na tela usando plt.show().
Ao executar o código, você verá o gráfico de setores com os setores circulares representando cada categoria. Os rótulos das categorias são exibidos ao lado de seus respectivos setores.
Espero que esta explicação detalhada tenha sido útil para entender o conceito do gráfico de setores!
1.2.7.2.4 - Histograma
O histograma é uma visualização gráfica que permite representar a distribuição de uma variável quantitativa contínua ou discreta. Ele divide o intervalo dos valores em várias faixas chamadas de "intervalos" ou "bins" e mostra a frequência ou a densidade de ocorrência dos valores dentro de cada intervalo.
Aqui estão os principais elementos de um histograma:
- Eixo x: É o eixo horizontal do histograma, que representa a escala dos valores da variável em estudo. O eixo x é dividido em intervalos ou bins, e cada intervalo representa uma faixa de valores.
- Eixo y: É o eixo vertical do histograma, que representa a frequência ou densidade de ocorrência dos valores dentro de cada intervalo. A escala do eixo y depende da escolha de representação do histograma: frequência absoluta, frequência relativa, densidade ou outra medida relevante.
- Intervalos (bins): São as faixas em que o eixo x é dividido. Cada intervalo representa uma faixa de valores contínuos ou um conjunto de valores discretos. A largura e o número de intervalos podem variar dependendo da distribuição dos dados e do objetivo do histograma.
- Barras: São retângulos verticais que representam cada intervalo no histograma. A altura da barra é proporcional à frequência ou densidade de ocorrência dos valores dentro do intervalo.
- Rótulos: São usados para identificar os intervalos ao longo do eixo x e, possivelmente, para fornecer informações adicionais, como os limites dos intervalos ou as categorias representadas.
- Título: É um texto descritivo que resume o conteúdo do histograma. Geralmente está localizado na parte superior do gráfico.
- Legendas: São usadas para descrever o significado das barras ou fornecer informações adicionais sobre a distribuição dos valores. As legendas podem incluir informações como média, mediana, desvio padrão, entre outros.
Os histogramas são amplamente utilizados para explorar e visualizar a distribuição de uma variável, identificar padrões, detectar assimetrias, avaliar a concentração ou dispersão dos dados, entre outras análises descritivas.
Aqui está um exemplo de código Python utilizando a biblioteca Matplotlib para criar um histograma:
import matplotlib.pyplot as plt
# Dados da variável
dados = [22, 30, 32, 35, 38, 40, 42, 45, 50, 55, 60, 65, 70, 72, 75]
# Criar o histograma
plt.hist(dados, bins=5)
# Personalizar o histograma
plt.title('Histograma')
plt.xlabel('Valores')
plt.ylabel('Frequência')
# Exibir o histograma
plt.show()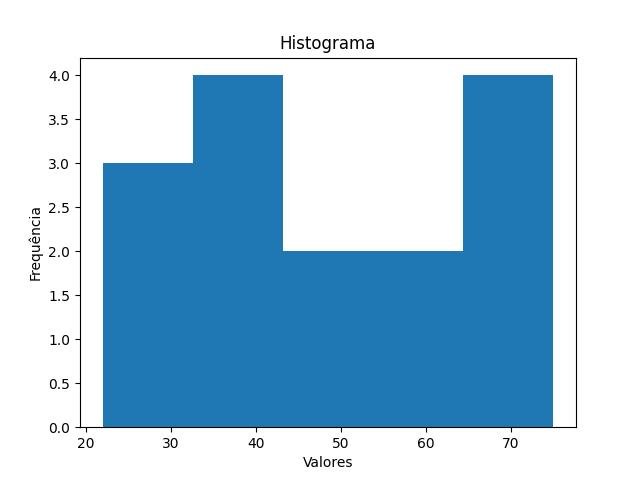
Neste exemplo, utilizamos a função plt.hist() para criar o histograma, passando os dados da variável e o número de bins como argumentos. O histograma é personalizado com um título, rótulos nos eixos x e y, utilizando as funções plt.title(), plt.xlabel() e plt.ylabel(), respectivamente. Por fim, o histograma é exibido na tela com plt.show().
Ao executar o código, você verá o histograma representando a distribuição dos valores
1.2.7.2.5 - Gráfico de dispersão
O gráfico de dispersão, também conhecido como gráfico de pontos, é uma visualização que permite explorar a relação entre duas variáveis quantitativas. Ele representa os pontos de dados em um plano cartesiano, onde cada ponto representa um par de valores correspondentes às duas variáveis.
Aqui estão os principais elementos de um gráfico de dispersão:
- Eixo x: É o eixo horizontal do gráfico, que representa os valores da primeira variável. Essa variável é geralmente referida como variável independente ou variável explanatória.
- Eixo y: É o eixo vertical do gráfico, que representa os valores da segunda variável. Essa variável é geralmente referida como variável dependente ou variável de resposta.
- Pontos: São os marcadores no gráfico que representam cada par de valores correspondentes às duas variáveis. Cada ponto é posicionado no plano cartesiano com base nos valores das duas variáveis.
- Título: É um texto descritivo que resume o conteúdo do gráfico de dispersão. Geralmente está localizado na parte superior do gráfico.
- Rótulos: São usados para identificar as variáveis ao longo dos eixos x e y. Eles fornecem informações sobre o que cada eixo representa e podem incluir unidades de medida, quando aplicável.
- Legendas: São usadas para descrever o significado dos pontos ou fornecer informações adicionais sobre os dados representados no gráfico.
- Linha de tendência: Opcionalmente, pode-se traçar uma linha de tendência ou linha de regressão que represente o padrão geral dos pontos. Essa linha pode ajudar a identificar padrões ou tendências na relação entre as variáveis.
Os gráficos de dispersão são frequentemente utilizados para identificar correlações, padrões, outliers ou qualquer relação entre duas variáveis. Eles permitem visualizar a dispersão dos dados e analisar a relação geral entre as variáveis.
Aqui está um exemplo de código Python utilizando a biblioteca Matplotlib para criar um gráfico de dispersão:
import matplotlib.pyplot as plt
# Dados das variáveis
x = [1, 2, 3, 4, 5, 6]
y = [3, 5, 4, 6, 8, 7]
# Criar o gráfico de dispersão
plt.scatter(x, y)
# Personalizar o gráfico
plt.title('Gráfico de Dispersão')
plt.xlabel('Variável X')
plt.ylabel('Variável Y')
# Exibir o gráfico
plt.show()
Neste exemplo, utilizamos a função plt.scatter() para criar o gráfico de dispersão, passando as duas variáveis x e y como argumentos. O gráfico é então personalizado com um título, rótulos nos eixos x e y, utilizando as funções plt.title(), plt.xlabel() e plt.ylabel(), respectivamente. Por fim, o gráfico de dispersão é exibido na tela com plt.show().
Ao executar o código, você verá o gráfico de dispersão representando a relação entre as variáveis x e y, onde cada ponto corresponde a um par de valores das duas variáveis.
1.2.7.2.6 - Gráfico de linhas
O gráfico de linhas é uma visualização que conecta pontos de dados através de segmentos de linha reta. Ele é usado para representar a evolução ou tendência de uma variável ao longo de um eixo de tempo ou outro tipo de escala contínua. É especialmente útil para mostrar a mudança progressiva de um valor ao longo de um período ou para comparar várias séries temporais.
Aqui estão os principais elementos de um gráfico de linhas:
- Eixo x: É o eixo horizontal do gráfico, que representa a escala de tempo ou outra escala contínua. Geralmente, é utilizado para representar os períodos, datas ou pontos de referência correspondentes aos valores.
- Eixo y: É o eixo vertical do gráfico, que representa os valores da variável em estudo. Pode representar qualquer medida quantitativa ou contínua.
- Linhas: São segmentos de linha reta que conectam os pontos de dados no gráfico. Cada ponto representa um valor específico da variável no eixo y em relação à posição correspondente no eixo x. As linhas permitem observar tendências, mudanças ao longo do tempo e padrões gerais da variável.
- Título: É um texto descritivo que resume o conteúdo do gráfico de linhas. Geralmente está localizado na parte superior do gráfico.
- Rótulos: São usados para identificar as variáveis ao longo dos eixos x e y. Fornecem informações sobre o que cada eixo representa e podem incluir unidades de medida, quando aplicável.
- Legendas: São usadas para descrever o significado de cada linha no gráfico, especialmente quando há várias séries de dados sendo representadas.
- Marcadores: Opcionalmente, é possível adicionar marcadores (pontos) nos pontos de dados para enfatizar sua localização exata no gráfico.
Os gráficos de linhas são amplamente utilizados para visualizar a tendência ao longo do tempo de uma variável, identificar padrões, comparar várias séries de dados ou destacar mudanças significativas. Eles fornecem uma representação clara e intuitiva da evolução dos valores.
Aqui está um exemplo de código Python utilizando a biblioteca Matplotlib para criar um gráfico de linhas:
import matplotlib.pyplot as plt
# Dados das variáveis
x = [1, 2, 3, 4, 5, 6]
y = [3, 5, 4, 6, 8, 7]
# Criar o gráfico de linhas
plt.plot(x, y)
# Personalizar o gráfico
plt.title('Gráfico de Linhas')
plt.xlabel('Eixo X')
plt.ylabel('Eixo Y')
# Exibir o gráfico
plt.show()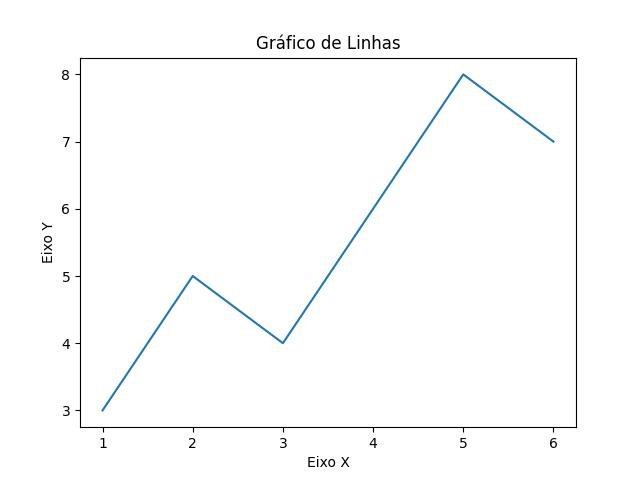
Neste exemplo, utilizamos a função plt.plot() para criar o gráfico de linhas, passando as duas variáveis x e y como argumentos. O gráfico é personalizado com um título, rótulos nos eixos x e y, utilizando as funções plt.title(), plt.xlabel() e plt.ylabel(), respectivamente. Por fim, o gráfico de linhas é exibido na tela com plt.show().
Ao executar o código, você verá o gráfico de linhas representando a relação entre as variáveis x e y, mostrando a tendência ou evolução dos valores ao longo do eixo x.
1.2.7.2.7 - Gráfico de caixas (boxplot)
O gráfico de caixas, também conhecido como boxplot, é uma visualização estatística que fornece informações sobre a distribuição de um conjunto de dados numéricos. Ele é especialmente útil para explorar a dispersão dos dados, identificar valores atípicos (outliers) e comparar distribuições entre diferentes grupos ou categorias.
Aqui estão os principais elementos de um gráfico de caixas (boxplot):
- Caixa (Box): É a parte central do gráfico que representa a distribuição dos dados. Ela é definida pelos quartis (Q1, Q2 e Q3) do conjunto de dados. O Q2 (segundo quartil) corresponde à mediana dos dados. O Q1 (primeiro quartil) é o valor que separa os 25% dos dados mais baixos, enquanto o Q3 (terceiro quartil) separa os 25% dos dados mais altos. A altura da caixa é conhecida como amplitude interquartil (IQR), calculada como IQR = Q3 - Q1.
- Linha mediana (Median): É uma linha dentro da caixa que indica a posição da mediana (Q2).
- Bigodes (Whiskers): São as linhas que se estendem a partir da caixa. Eles representam a extensão dos dados dentro de um intervalo específico. Os bigodes são geralmente calculados com base no IQR, estendendo-se 1,5 vezes o IQR a partir dos quartis Q1 e Q3. Pontos fora dessa extensão são frequentemente considerados valores atípicos.
- Valores atípicos (Outliers): São pontos individuais que estão além dos bigodes. Eles podem ser indicativos de valores extremos ou anômalos no conjunto de dados.
- Título: É um texto descritivo que resume o conteúdo do gráfico de caixas. Geralmente está localizado na parte superior do gráfico.
- Rótulo: É usado para identificar o eixo vertical e pode fornecer informações sobre a variável representada.
Os gráficos de caixas são amplamente utilizados para resumir e comparar a distribuição de dados numéricos em diferentes grupos ou categorias. Eles permitem visualizar a mediana, a dispersão dos dados, a presença de valores atípicos e identificar possíveis diferenças entre os grupos.
Aqui está um exemplo de código Python utilizando a biblioteca Seaborn para criar um gráfico de caixas:
import seaborn as sns
# Dados das variáveis
grupo1 = [10, 12, 15, 18, 20, 22, 25]
grupo2 = [5, 8, 10, 12, 15, 18, 20]
# Criar o gráfico de caixas
sns.boxplot(data=[grupo1, grupo2])
# Personalizar o gráfico
plt.title('Gráfico de Caixas')
plt.ylabel('Valores')
# Exibir o gráfico
plt.show()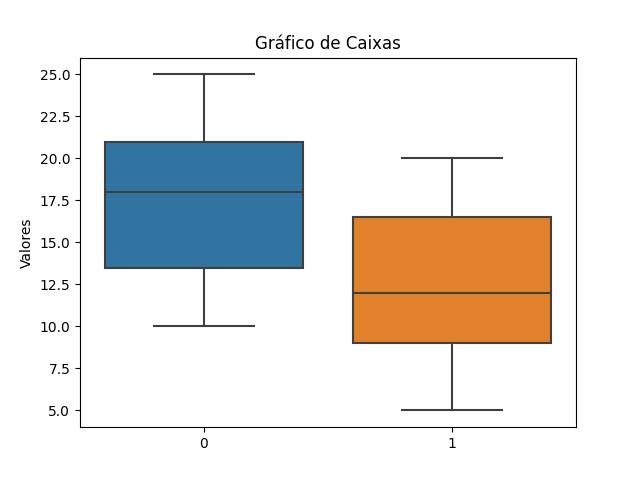
Neste exemplo, utilizamos a função sns.boxplot() do Seaborn para criar o gráfico de caixas, passando os dados dos grupos como uma lista de listas. O gráfico é personalizado com um título e um rótulo no eixo y utilizando as funções plt.title() e plt.ylabel(), respectivamente. Por fim, o gráfico de caixas é exibido na tela com plt.show().
Ao executar o código, você verá o gráfico de caixas representando a distribuição dos valores nos grupos 1 e 2, permitindo a comparação entre eles.
Espero que esta explicação detalhada tenha sido útil para entender o conceito do gráfico de caixas (boxplot)!
1.2.7.2.8 - Gráfico de área
O gráfico de área é uma visualização que mostra a distribuição ou a contribuição de diferentes categorias ao longo de um eixo. É uma variação do gráfico de linha em que a área abaixo da linha é preenchida, criando uma representação visual da contribuição de cada categoria em relação ao todo.
Aqui estão os principais elementos de um gráfico de área:
- Eixo x: É o eixo horizontal do gráfico, que representa as categorias ou o intervalo de valores em que os dados estão agrupados.
- Eixo y: É o eixo vertical do gráfico, que representa a escala numérica ou a proporção da contribuição de cada categoria.
- Áreas: São as regiões preenchidas abaixo das linhas, que representam a contribuição de cada categoria em relação ao todo. Cada categoria é representada por uma área colorida no gráfico.
- Título: É um texto descritivo que resume o conteúdo do gráfico de área. Geralmente está localizado na parte superior do gráfico.
- Rótulos: São usados para identificar as categorias ao longo do eixo x e podem incluir unidades de medida, quando aplicável.
- Legendas: São usadas para descrever o significado de cada área ou fornecer informações adicionais sobre as categorias representadas no gráfico.
Os gráficos de área são comumente usados para visualizar a distribuição de dados ao longo do tempo ou para comparar a contribuição de diferentes categorias em um conjunto de dados. Eles permitem identificar tendências, proporções e mudanças na distribuição ao longo do eixo x.
Aqui está um exemplo de código Python utilizando a biblioteca Matplotlib para criar um gráfico de área:
import matplotlib.pyplot as plt
# Dados das categorias
categorias = ['Categoria A', 'Categoria B', 'Categoria C', 'Categoria D']
valores = [30, 45, 25, 50]
# Criar o gráfico de área
plt.stackplot(categorias, valores, labels=categorias)
# Personalizar o gráfico
plt.title('Gráfico de Área')
plt.xlabel('Categorias')
plt.ylabel('Valores')
# Exibir as legendas
plt.legend(loc='upper left')
# Exibir o gráfico
plt.show()
Neste exemplo, utilizamos a função plt.stackplot() para criar o gráfico de área, passando as categorias e os valores correspondentes como argumentos. Utilizamos a opção labels para fornecer rótulos para as áreas correspondentes às categorias. O gráfico é personalizado com um título, rótulos nos eixos x e y, utilizando as funções plt.title(), plt.xlabel() e plt.ylabel(), respectivamente. Também exibimos as legendas utilizando a função plt.legend() e especificando a localização onde devem ser exibidas. Por fim, o gráfico de área é exibido na tela com plt.show().
Ao executar o código, você verá o gráfico de área representando a contribuição das categorias A, B, C e D, permitindo a comparação visual da contribuição de cada categoria.
Espero que esta explicação detalhada tenha sido útil para entender o conceito do gráfico de área!
1.2.7.2.9 - Gráfico de dispersão com bolhas
O gráfico de dispersão com bolhas, também conhecido como bubble plot, é uma visualização que combina as características do gráfico de dispersão tradicional com o uso de bolhas para representar uma terceira variável. É útil para explorar a relação entre duas variáveis contínuas e adicionar uma dimensão adicional para representar uma variável adicional através do tamanho das bolhas.
Aqui estão os principais elementos de um gráfico de dispersão com bolhas:
- Eixo x: Representa a primeira variável contínua que está sendo analisada.
- Eixo y: Representa a segunda variável contínua que está sendo analisada.
- Bolhas: São representações gráficas dos pontos de dados, onde o tamanho da bolha é proporcional a uma terceira variável. Quanto maior o tamanho da bolha, maior é o valor correspondente da terceira variável.
- Título: É um texto descritivo que resume o conteúdo do gráfico de dispersão com bolhas. Geralmente está localizado na parte superior do gráfico.
- Rótulos: São usados para identificar as variáveis ao longo dos eixos x e y e podem incluir unidades de medida, quando aplicável.
- Legenda: É usada para descrever o significado do tamanho das bolhas, representando a terceira variável. Geralmente é exibida em uma caixa de legenda na parte do gráfico.
Os gráficos de dispersão com bolhas são úteis para identificar padrões, tendências e correlações entre duas variáveis contínuas, além de fornecer uma dimensão adicional através do tamanho das bolhas. Eles são amplamente utilizados para visualizar dados multidimensionais e comunicar informações complexas de forma eficaz.
Aqui está um exemplo de código Python utilizando a biblioteca Matplotlib para criar um gráfico de dispersão com bolhas:
import matplotlib.pyplot as plt
import numpy as np
# Dados das variáveis
x = np.random.rand(50) # Exemplo de valores aleatórios para o eixo x
y = np.random.rand(50) # Exemplo de valores aleatórios para o eixo y
z = np.random.rand(50) # Exemplo de valores aleatórios para a terceira variável
# Criar o gráfico de dispersão com bolhas
plt.scatter(x, y, s=z*1000, alpha=0.5)
# Personalizar o gráfico
plt.title('Gráfico de Dispersão com Bolhas')
plt.xlabel('Eixo X')
plt.ylabel('Eixo Y')
# Exibir o gráfico
plt.show()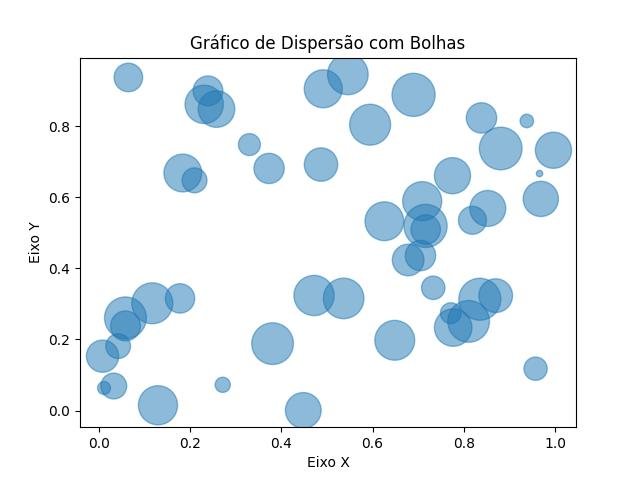
Neste exemplo, utilizamos a função plt.scatter() para criar o gráfico de dispersão com bolhas. Passamos os valores das variáveis x e y como argumentos para os eixos x e y, respectivamente. A variável z é utilizada para determinar o tamanho das bolhas, multiplicando por 1000 (no exemplo) e utilizando o argumento s da função scatter(). O argumento alpha define a transparência das bolhas. O gráfico é personalizado com um título, rótulos nos eixos x e y, utilizando as funções plt.title(), plt.xlabel() e plt.ylabel(), respectivamente. Por fim, o gráfico de dispersão com bolhas é ex
1.2.7.2.10 - Mapas e gráficos geoespaciais
Mapas e gráficos geoespaciais são visualizações que representam dados relacionados a localizações geográficas. Eles são amplamente utilizados para analisar padrões espaciais, identificar tendências regionais e comunicar informações geográficas de forma visualmente eficaz.
Existem várias técnicas e ferramentas para criar mapas e gráficos geoespaciais, e algumas delas são:
- Sistemas de Informação Geográfica (SIG): São ferramentas que permitem a captura, armazenamento, análise e exibição de dados geográficos. Eles fornecem recursos avançados para criar mapas, realizar análises espaciais e integrar dados geográficos com outras informações.
- Shapefiles: São arquivos populares para armazenar dados geoespaciais. Eles consistem em arquivos com extensão .shp que contêm geometrias (pontos, linhas, polígonos) representando características geográficas, como países, cidades, estradas, entre outros. Esses arquivos podem ser lidos e processados por várias bibliotecas de geoprocessamento em diferentes linguagens de programação.
- Bibliotecas de Geoprocessamento: Existem diversas bibliotecas disponíveis para processamento e visualização de dados geoespaciais em diferentes linguagens de programação. Alguns exemplos populares incluem:
- Python: GeoPandas, Shapely, Folium, Basemap.
- R: ggplot2, leaflet, sp.
- JavaScript: Leaflet, D3.js, Mapbox.
- Mapas de calor (Heatmaps): São representações visuais que utilizam cores para mostrar a intensidade ou densidade de um fenômeno geográfico em uma área específica. Eles são úteis para identificar padrões de concentração ou dispersão de dados em um mapa.
- Cartogramas: São mapas que distorcem a forma e o tamanho das áreas geográficas com base em uma variável específica. Eles são usados para enfatizar a representação proporcional de dados em uma área geográfica, como população, renda per capita, entre outros.
- Gráficos de densidade espacial (Spatial Density Plots): São gráficos que representam a densidade de ocorrência de eventos em um mapa. Eles são úteis para identificar áreas de maior ou menor concentração de eventos, como crimes, acidentes, pontos de interesse, entre outros.
- Visualizações 3D: Além dos mapas tradicionais em duas dimensões, também é possível criar visualizações geoespaciais em três dimensões. Isso permite explorar dados em diferentes alturas, inclinações e perspectivas, proporcionando uma experiência imersiva.
Essas são apenas algumas das técnicas e ferramentas disponíveis para criar mapas e gráficos geoespaciais. A escolha da técnica adequada dependerá dos dados e das informações que você deseja visualizar e analisar. É importante considerar a natureza dos dados geográficos, as necessidades de análise espacial e as habilidades e recursos disponíveis.
Aqui está um exemplo de código para criar um mapa simples usando Folium:
import folium
# Criar um objeto de mapa
mapa = folium.Map(location=[-22.9068, -43.1729], zoom_start=12)
# Adicionar um marcador no mapa
folium.Marker([-22.9068, -43.1729], popup='Rio de Janeiro').add_to(mapa)
# Exibir o mapa
mapa.save('mapa.html')Neste exemplo, importamos a biblioteca folium e criamos um objeto de mapa usando a função folium.Map(). Passamos a localização inicial do mapa (latitude e longitude) e o nível de zoom desejado.
Em seguida, adicionamos um marcador ao mapa usando a função folium.Marker(). Passamos a localização do marcador (latitude e longitude) e um texto de popup que será exibido quando o marcador for clicado.
Por fim, usamos o método save() para salvar o mapa em um arquivo HTML chamado "mapa.html". Você pode abrir esse arquivo em um navegador para visualizar o mapa interativo.
Você pode personalizar ainda mais o mapa adicionando camadas, polígonos, linhas, cores e muito mais. O Folium oferece uma série de recursos e opções de personalização para criar mapas interativos ricos em detalhes.
Lembre-se de instalar a biblioteca Folium usando o pip antes de executar o código:
pip install foliumEspero que este exemplo tenha sido útil! Você pode explorar a documentação oficial do Folium para obter mais informações e exemplos avançados: https://python-visualization.github.io/folium/
1.2.7.2.11 - Gráfico de área empilhada
O gráfico de área empilhada, também conhecido como stacked area chart, é uma visualização que mostra a distribuição de várias categorias ao longo de um eixo, empilhando as áreas correspondentes a cada categoria. Ele é semelhante ao gráfico de área, mas no gráfico de área empilhada, as áreas das categorias são sobrepostas umas sobre as outras, criando uma representação visual das proporções relativas entre as categorias.
Aqui estão os principais elementos de um gráfico de área empilhada:
- Eixo x: É o eixo horizontal do gráfico, que representa as categorias ou o intervalo de valores em que os dados estão agrupados.
- Eixo y: É o eixo vertical do gráfico, que representa a escala numérica ou a proporção da contribuição de cada categoria.
- Áreas empilhadas: São as áreas preenchidas abaixo das linhas, representando as contribuições de cada categoria em relação ao todo. As áreas são empilhadas uma sobre a outra, mostrando a soma cumulativa das proporções das categorias.
- Título: É um texto descritivo que resume o conteúdo do gráfico de área empilhada. Geralmente está localizado na parte superior do gráfico.
- Rótulos: São usados para identificar as categorias ao longo do eixo x e podem incluir unidades de medida, quando aplicável.
- Legendas: São usadas para descrever o significado de cada área empilhada ou fornecer informações adicionais sobre as categorias representadas no gráfico.
Os gráficos de área empilhada são comumente usados para visualizar a distribuição de dados ao longo do tempo ou para comparar as contribuições de diferentes categorias em um conjunto de dados. Eles permitem identificar tendências, proporções e mudanças na distribuição ao longo do eixo x, bem como a contribuição relativa de cada categoria para o todo.
Aqui está um exemplo de código Python utilizando a biblioteca Matplotlib para criar um gráfico de área empilhada:
import matplotlib.pyplot as plt
# Dados das categorias
categorias = ['Categoria A', 'Categoria B', 'Categoria C']
valores1 = [20, 35, 15] # Valores para a primeira categoria
valores2 = [30, 15, 25] # Valores para a segunda categoria
valores3 = [10, 30, 20] # Valores para a terceira categoria
# Criar o gráfico de área empilhada
plt.stackplot(categorias, valores1, valores2, valores3, labels=['Valor 1', 'Valor 2', 'Valor 3'])
# Personalizar o gráfico
plt.title('Gráfico de Área Empilhada')
plt.xlabel('Categorias')
plt.ylabel('Valores')
# Exibir as legendas
plt.legend(loc='upper left')
# Exibir o gráfico
plt.show()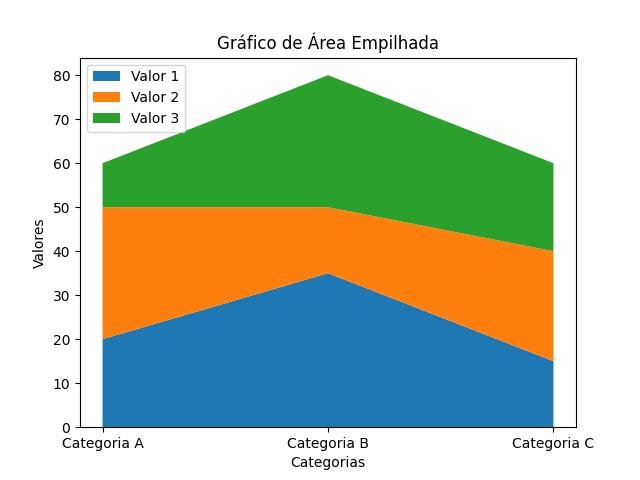
Neste exemplo, utilizamos a função plt.stackplot() para criar o gráfico de área empilhada. Passamos as categorias e os valores correspondentes para cada categoria como argumentos. Utilizamos a opção labels para fornecer rótulos para cada área empilhada. O gráfico é personalizado com um título, rótulos nos eixos x e y, utilizando as funções plt.title(), `plt
1.2.7.2.12 - Gráfico de radar
O gráfico de radar, também conhecido como gráfico de teia ou gráfico de aranha, é uma visualização que representa múltiplas variáveis em um formato radial. É útil para comparar o desempenho ou características de diferentes categorias em relação a várias métricas.
Aqui estão os principais elementos de um gráfico de radar:
- Eixo radial: É composto por várias linhas que partem de um ponto central e se estendem em direções diferentes. Cada linha representa uma variável ou métrica.
- Eixo angular: É uma circunferência ou uma série de ângulos que indicam as diferentes direções das linhas radiais. Cada ângulo representa uma categoria ou uma unidade de observação.
- Linhas de dados: São linhas que conectam os pontos de dados correspondentes a cada categoria nas linhas radiais. Elas representam o valor de cada variável para a categoria correspondente.
- Área fechada: Em alguns casos, as linhas de dados podem ser preenchidas para formar uma área fechada. Isso pode ajudar a enfatizar a distribuição e o padrão geral dos dados.
- Rótulos: São usados para identificar as variáveis ao longo das linhas radiais e as categorias ao longo do eixo angular.
- Legenda: É usada para descrever o significado das linhas ou áreas no gráfico de radar, indicando a qual categoria ou variável cada linha se refere.
Os gráficos de radar são úteis para comparar o desempenho ou características de várias categorias em relação a diferentes variáveis. Eles permitem identificar padrões, pontos fortes e pontos fracos em diferentes métricas para cada categoria. Além disso, o formato radial facilita a comparação entre as categorias, pois todas as variáveis estão representadas na mesma escala e na mesma visualização.
Aqui está um exemplo de código Python utilizando a biblioteca Matplotlib para criar um gráfico de radar:
import numpy as np
import matplotlib.pyplot as plt
# Dados das variáveis e categorias
variaveis = ['Variável A', 'Variável B', 'Variável C', 'Variável D', 'Variável E', 'Variável F']
categorias = ['Categoria 1', 'Categoria 2', 'Categoria 3', 'Categoria 4', 'Categoria 5', 'Categoria 6']
# Valores para cada categoria e variável
valores_categoria1 = [3, 4, 2, 5, 3]
valores_categoria2 = [4, 2, 3, 2, 5]
valores_categoria3 = [2, 5, 4, 3, 2]
valores_categoria4 = [5, 3, 2, 4, 4]
valores_categoria5 = [3, 2, 5, 3, 4]
valores_categoria6 = [4, 2, 2, 3, 3]
# Criar o gráfico de radar
fig, ax = plt.subplots(figsize=(6, 6), subplot_kw={'projection': 'polar'})
ax.set_theta_offset(np.pi/2)
ax.set_theta_direction(-1)
# Calcular os ângulos para cada variável
angulos = np.linspace(0, 2*np.pi, len(variaveis), endpoint=False).tolist()
# Adicionar as linhas de dados para cada categoria
ax.plot(angulos, valores_categoria1 + [valores_categoria1[0]], label='Categoria 1')
ax.plot(angulos, valores_categoria2 + [valores_categoria2[0]], label='Categoria 2')
ax.plot(angulos, valores_categoria3 + [valores_categoria3[0]], label='Categoria 3')
ax.plot(angulos, valores_categoria4 + [valores_categoria4[0]], label='Categoria 4')
ax.plot(angulos, valores_categoria5 + [valores_categoria5[0]], label='Categoria 5')
ax.plot(angulos, valores_categoria6 + [valores_categoria6[0]], label='Categoria 6')
# Personalizar o gráfico
ax.set_xticks(angulos)
ax.set_xticklabels(variaveis)
ax.yaxis.grid(True)
ax.legend()
# Exibir o gráfico
plt.show()
Neste exemplo, utilizamos a função plt.subplots() para criar uma figura e um conjunto de eixos para o gráfico de radar. Configuramos o subplot_kw com {'projection': 'polar'} para criar um gráfico polar.
Em seguida, definimos os ângulos para cada variável utilizando a função np.linspace() e adicionamos as linhas de dados correspondentes a cada categoria usando a função ax.plot(). É importante fechar o polígono, adicionando o primeiro valor novamente ao final de cada lista de valores.
Personalizamos o gráfico definindo os ângulos no eixo x, as etiquetas das variáveis, habilitando as linhas de grade no eixo y e exibindo a legenda.
Finalmente, exibimos o gráfico usando a função plt.show().
Espero que este exemplo tenha sido útil! Você pode explorar mais opções de personalização e funcionalidades da biblioteca Matplotlib para criar gráficos de radar mais avançados.
1.2.7.2.13 - Gráfico de Gantt
O gráfico de Gantt é uma visualização que representa as tarefas de um projeto em um cronograma, mostrando a duração de cada tarefa e a sobreposição entre elas. É uma ferramenta amplamente utilizada na gestão de projetos para planejar, acompanhar e visualizar o progresso das atividades ao longo do tempo.
Aqui estão os principais elementos de um gráfico de Gantt:
- Linhas de tarefas: São as linhas horizontais que representam cada tarefa do projeto. Cada linha é rotulada com o nome da tarefa ou uma identificação única.
- Barras de tarefas: São barras horizontais que representam a duração de cada tarefa. As barras são posicionadas ao longo do eixo de tempo do gráfico.
- Eixo de tempo: É o eixo horizontal do gráfico que representa o período de tempo em que as tarefas são executadas. Pode ser exibido em dias, semanas, meses, etc.
- Rótulos de data: São usados para identificar as datas ao longo do eixo de tempo. Podem ser exibidos em intervalos regulares, como dias ou semanas.
- Dependências entre tarefas: Podem ser representadas por setas ou linhas conectando as barras de tarefas. Isso mostra a sequência de execução das tarefas e as relações de dependência entre elas.
- Legenda: É usada para fornecer informações adicionais sobre as cores, símbolos ou outros elementos do gráfico.
Os gráficos de Gantt são úteis para visualizar a ordem e a duração das tarefas de um projeto, identificar sobreposições ou lacunas na programação, determinar dependências entre as atividades e acompanhar o progresso do projeto ao longo do tempo.
Existem várias bibliotecas em Python que podem ser usadas para criar gráficos de Gantt, como matplotlib, plotly e gantt. Aqui está um exemplo de código usando a biblioteca matplotlib:
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
# Dados das tarefas
tarefas = ['Tarefa A', 'Tarefa B', 'Tarefa C', 'Tarefa D']
datas_inicio = ['2023-01-01', '2023-01-05', '2023-01-10', '2023-01-15']
duracoes = [5, 8, 6, 4] # Duração em dias
# Converter as datas para o formato apropriado
datas_inicio = [mdates.datestr2num(data) for data in datas_inicio]
# Criar o gráfico de Gantt
fig, ax = plt.subplots()
# Configurar o eixo x como datas
ax.xaxis_date()
ax.xaxis.set_major_formatter(mdates.DateFormatter('%y-%m-%d'))
# Plotar as barras de tarefas
ax.barh(tarefas, duracoes, left=datas_inicio)
# Personalizar o gráfico
ax.set_xlabel('Data')
ax.set_ylabel('Tarefas')
ax.set_title('Gráfico de Gantt')
# Exibir o gráfico
plt.show()
Neste exemplo, importamos as bibliotecas matplotlib.pyplot e matplotlib.dates. Definimos os dados das tarefas, incluindo os nomes das tarefas, as
1.2.7.2.14 - Gráfico de bolhas
O gráfico de bolhas, também conhecido como bubble chart, é uma visualização que representa dados em três dimensões: duas dimensões para os eixos x e y e a terceira dimensão para o tamanho das bolhas. É uma forma eficaz de mostrar a relação entre três variáveis e destacar padrões ou clusters nos dados.
Aqui estão os principais elementos de um gráfico de bolhas:
- Eixo x e eixo y: São os eixos horizontal e vertical que representam duas variáveis independentes. Cada ponto de dados é posicionado de acordo com os valores dessas duas variáveis.
- Tamanho das bolhas: É uma terceira variável que determina o tamanho das bolhas no gráfico. Quanto maior o valor dessa variável, maior será o tamanho da bolha correspondente.
- Rótulos: São usados para identificar os pontos de dados ou fornecer informações adicionais sobre cada bolha.
- Legenda: É usada para descrever o significado das bolhas ou fornecer informações adicionais sobre as variáveis representadas no gráfico.
Os gráficos de bolhas são úteis para mostrar relacionamentos complexos entre três variáveis e identificar padrões, clusters ou anomalias nos dados. Eles são especialmente úteis quando a terceira variável (tamanho das bolhas) é significativa e adiciona uma dimensão adicional à visualização.
Aqui está um exemplo de código Python utilizando a biblioteca Matplotlib para criar um gráfico de bolhas:
import numpy as np
import matplotlib.pyplot as plt
# Dados das variáveis
x = np.random.rand(50) # Valores para o eixo x
y = np.random.rand(50) # Valores para o eixo y
tamanhos = np.random.rand(50) * 100 # Valores para o tamanho das bolhas
# Criar o gráfico de bolhas
plt.scatter(x, y, s=tamanhos, alpha=0.5)
# Personalizar o gráfico
plt.title('Gráfico de Bolhas')
plt.xlabel('Eixo X')
plt.ylabel('Eixo Y')
# Exibir o gráfico
plt.show()
Neste exemplo, utilizamos a função plt.scatter() para criar o gráfico de bolhas. Passamos os valores para os eixos x e y como argumentos, e utilizamos a opção s para definir os tamanhos das bolhas com base nos valores da terceira variável. A opção alpha é usada para controlar a transparência das bolhas.
O gráfico é personalizado com um título, rótulos nos eixos x e y, utilizando as funções plt.title(), plt.xlabel() e plt.ylabel().
Você pode personalizar ainda mais o gráfico de bolhas, como alterar as cores das bolhas, adicionar uma legenda, aplicar escala aos tamanhos das bolhas ou adicionar informações adicionais aos rótulos. A biblioteca Matplotlib oferece várias opções de personalização para criar gráficos de bolhas visualmente atraentes e informativos.
1.2.7.2.15 - Gráfico de Sankey
O gráfico de Sankey, também conhecido como diagrama de fluxo de Sankey, é uma visualização que representa o fluxo de dados, recursos ou quantidades entre diferentes categorias. É uma forma eficaz de mostrar relações de entrada e saída, proporções e fluxos entre diferentes elementos de um sistema.
Aqui estão os principais elementos de um gráfico de Sankey:
- Nós: São as categorias ou elementos do sistema representados por retângulos ou caixas. Cada nó é rotulado com o nome ou identificação da categoria.
- Fluxos: São as conexões entre os nós que representam o fluxo de dados, recursos ou quantidades. Os fluxos são representados por setas ou linhas de diferentes espessuras, que indicam a quantidade ou proporção do fluxo.
- Rótulos: São usados para identificar os fluxos ou fornecer informações adicionais sobre cada conexão.
- Proporções: As larguras dos fluxos podem ser usadas para representar as proporções relativas entre os nós e a quantidade de fluxo entre eles.
Os gráficos de Sankey são úteis para visualizar e analisar o fluxo de dados ou recursos em sistemas complexos, como redes de energia, fluxos de tráfego, processos industriais, orçamentos financeiros, entre outros. Eles permitem identificar gargalos, distribuição desigual de recursos e entender como as quantidades são divididas e transferidas entre diferentes categorias.
Existem várias bibliotecas em Python que podem ser usadas para criar gráficos de Sankey, como plotly, matplotlib e networkx. Aqui está um exemplo de código usando a biblioteca plotly:
import plotly.graph_objects as go
# Dados dos nós e fluxos
nos = ["A", "B", "C", "D", "E"]
fluxos = {
"A": {"B": 20, "C": 30},
"B": {"D": 15},
"C": {"D": 10, "E": 20},
"D": {"E": 5}
}
# Criar as listas de fontes, alvos e valores dos fluxos
sources = []
targets = []
values = []
# Mapear os nomes dos nós para índices
indice_nos = {nome: idx for idx, nome in enumerate(nos)}
# Iterar sobre os dados dos fluxos
for origem, destinos in fluxos.items():
for destino, valor in destinos.items():
sources.append(indice_nos[origem])
targets.append(indice_nos[destino])
values.append(valor)
# Criar o gráfico de Sankey
fig = go.Figure(data=[go.Sankey(
node=dict(
label=nos,
pad=15,
thickness=20
),
link=dict(
source=sources, # Usar índices dos nós de origem
target=targets, # Usar índices dos nós de destino
value=values
)
)])
# Personalizar o gráfico
fig.update_layout(title_text="Gráfico de Sankey")
# Exibir o gráfico
fig.show()
Neste exemplo, importamos a biblioteca plotly.graph_objects e definimos os dados dos nós e fluxos. Cada nó é representado por uma string única, e os fluxos são definidos como um dicionário em que as chaves são os nós de origem e os valores são
1.2.7.2.16 - Gráfico de rede (network graph)
O gráfico de rede, também conhecido como network graph ou grafo, é uma visualização que representa as relações entre diferentes elementos em um conjunto de dados. É composto por nós (ou vértices) e arestas (ou conexões) que representam as interações, conexões ou relações entre os nós.
Aqui estão os principais elementos de um gráfico de rede:
- Nós (vértices): São os elementos individuais do conjunto de dados. Cada nó pode representar uma entidade, uma pessoa, um local ou qualquer objeto do conjunto de dados. Os nós são geralmente representados por pontos ou formas.
- Arestas (conexões): São as linhas ou conexões entre os nós que representam as relações ou interações entre eles. As arestas podem ser direcionais (com uma seta que indica a direção da relação) ou não direcionais (sem seta, indicando uma relação bidirecional).
- Peso das arestas: Em alguns casos, as arestas podem ter um peso ou valor associado, que representa a intensidade, a frequência ou a força da relação entre os nós. Isso pode ser visualizado usando a espessura das arestas.
- Rótulos: São usados para identificar os nós ou fornecer informações adicionais sobre cada elemento. Os rótulos podem ser os nomes dos nós ou quaisquer outras informações relevantes.
Os gráficos de rede são úteis para visualizar relações complexas e interconexões em dados que podem não ser facilmente compreendidos em outras formas de visualização. Eles são amplamente utilizados em diversas áreas, como redes sociais, análise de redes, ciência de dados, sistemas complexos, entre outros.
Existem várias bibliotecas em Python que podem ser usadas para criar gráficos de rede, como networkx, igraph e plotly. Aqui está um exemplo de código usando a biblioteca networkx:
import networkx as nx
import matplotlib.pyplot as plt
# Criar um objeto de grafo
G = nx.Graph()
# Adicionar nós ao grafo
G.add_nodes_from([1, 2, 3, 4, 5])
# Adicionar arestas ao grafo
G.add_edges_from([(1, 2), (1, 3), (2, 3), (2, 4), (3, 4), (4, 5)])
# Layout do grafo
pos = nx.spring_layout(G)
# Desenhar os nós
nx.draw_networkx_nodes(G, pos)
# Desenhar as arestas
nx.draw_networkx_edges(G, pos)
# Adicionar rótulos aos nós
nx.draw_networkx_labels(G, pos)
# Exibir o grafo
plt.axis('off')
plt.show()
Neste exemplo, importamos a biblioteca networkx e criamos um objeto de grafo chamado G. Adicionamos nós ao grafo usando a função add_nodes_from() e adicionamos arestas usando a função add_edges_from().
Em seguida, definimos o layout do grafo usando a função spring_layout() do networkx. Essa função atribui posições aos nós usando um algoritmo baseado em física.
Depois, desenhamos os nós usando a função draw_networkx_nodes(), as arestas usando a função draw_networkx_edges() e adicionamos rótulos aos nós usando a
1.2.7.2.17 - Gráfico de cascata (waterfall chart)
O gráfico de cascata, também conhecido como waterfall chart, é uma visualização que ilustra como um valor inicial é alterado por uma série de fatores positivos e negativos, mostrando o impacto acumulado dessas mudanças. Ele é frequentemente usado para analisar o efeito líquido de diferentes componentes em um determinado valor, destacando contribuições individuais e variações ao longo do tempo.
Aqui estão os principais elementos de um gráfico de cascata:
- Valor inicial: É o valor de referência a partir do qual as mudanças serão calculadas. É geralmente mostrado como o primeiro nível no gráfico.
- Componentes: São os fatores positivos e negativos que contribuem para a mudança no valor inicial. Cada componente é representado por uma barra que se estende acima ou abaixo do nível anterior, dependendo se é positivo ou negativo.
- Níveis intermediários: São os níveis intermediários que mostram os valores acumulados à medida que os componentes são adicionados ou subtraídos do valor inicial. Eles ajudam a visualizar a mudança acumulada em cada etapa.
- Valor final: É o valor resultante após a consideração de todos os componentes. É mostrado como o último nível no gráfico.
Os gráficos de cascata são úteis para entender as mudanças cumulativas em um valor ao longo do tempo ou entre diferentes categorias. Eles são comumente usados em áreas como análise financeira, demonstrações de fluxo de caixa, análise de desempenho de vendas, entre outros.
Aqui está um exemplo de código Python usando a biblioteca matplotlib para criar um gráfico de cascata:
import matplotlib.pyplot as plt
# Dados dos componentes
componentes = ['Receita', 'Custos', 'Impostos', 'Despesas', 'Lucro']
valores = [100, -50, -20, -30, 40]
# Calcular os níveis intermediários
niveis = [0] + [sum(valores[:i+1]) for i in range(len(valores)-1)]
# Criar o gráfico de cascata
plt.bar(componentes, valores, bottom=niveis, color=['g', 'r', 'r', 'r', 'b'])
# Personalizar o gráfico
plt.title('Gráfico de Cascata')
plt.xlabel('Componentes')
plt.ylabel('Valor')
plt.grid(True)
# Exibir o gráfico
plt.show()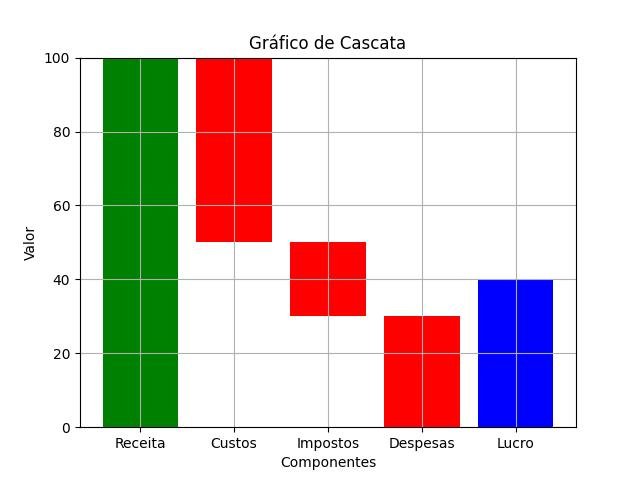
Neste exemplo, definimos os dados dos componentes e seus valores correspondentes. Os valores positivos são representados por barras verdes e os valores negativos por barras vermelhas. O valor final, que é a soma de todos os componentes, é mostrado como uma barra azul.
Calculamos os níveis intermediários somando os valores anteriores. A função plt.bar() é usada para criar as barras do gráfico de cascata, onde definimos os componentes, os valores, os níveis intermediários e as cores correspondentes.
Personalizamos o gráfico com um título, rótulos nos eixos x e y, e adicionamos grades para melhorar a legibilidade.
Você pode ajustar o exemplo de código de acordo com seus próprios dados e personalizações adicionais, como cores, rótulos, estilos de linha, entre outros. A biblioteca matplotlib oferece diversas opções para aprimorar a aparência do gráfico.
1.2.7.2.18 - Gráfico de controle
O gráfico de controle, também conhecido como gráfico de controle estatístico de processo (CEP - Controle Estatístico de Processo), é uma ferramenta utilizada na análise de dados para monitorar e controlar a qualidade de um processo ao longo do tempo. Ele é especialmente útil na identificação de variações inaceitáveis no desempenho do processo, permitindo que ações corretivas sejam tomadas.
Existem vários tipos de gráficos de controle, mas os mais comumente utilizados são o gráfico de controle para dados individuais e o gráfico de controle para médias e amplitudes.
O gráfico de controle para dados individuais é usado quando temos apenas um valor observado em cada medição. Ele consiste em uma linha central que representa a média do processo e duas linhas de controle superior e inferior que são calculadas com base na variabilidade dos dados. Essas linhas de controle são geralmente definidas a uma distância fixa em relação à linha central, considerando a variabilidade esperada do processo. Quando um ponto ultrapassa essas linhas de controle, isso indica uma variação significativa que requer investigação.
O gráfico de controle para médias e amplitudes é usado quando temos várias medições em cada ponto de coleta. Ele é dividido em dois subgráficos: o gráfico de controle da média e o gráfico de controle da amplitude. O gráfico de controle da média mostra a média dos subgrupos de dados ao longo do tempo, enquanto o gráfico de controle da amplitude mostra a variação (amplitude) dentro de cada subgrupo. As linhas de controle são calculadas com base nas médias e amplitudes dos subgrupos e ajudam a monitorar a estabilidade do processo.
Aqui está um exemplo de código Python utilizando a biblioteca matplotlib para criar um gráfico de controle para dados individuais:
import numpy as np
import matplotlib.pyplot as plt
# Dados de exemplo
dados = np.array([5.1, 5.3, 5.2, 5.4, 5.6, 5.3, 5.5, 5.2, 5.4, 5.6, 5.2, 5.3, 5.5])
# Média e desvio padrão dos dados
media = np.mean(dados)
desvio_padrao = np.std(dados)
# Limite superior e inferior de controle
limite_superior = media + 3 * desvio_padrao
limite_inferior = media - 3 * desvio_padrao
# Plotagem do gráfico de controle
plt.plot(dados, 'bo-', label='Dados')
plt.axhline(media, color='r', linestyle='-', linewidth=2, label='Média')
plt.axhline(limite_superior, color='g', linestyle='--', linewidth=1, label='Limite Superior de Controle')
plt.axhline(limite_inferior, color='g', linestyle='--', linewidth=1, label='Limite Inferior de Controle')
# Configurações do gráfico
plt.title('Gráfico de Controle para Dados Individuais')
plt.xlabel('Amostras')
plt.ylabel('Valores')
plt.legend()
# Exibição do gráfico
plt.show()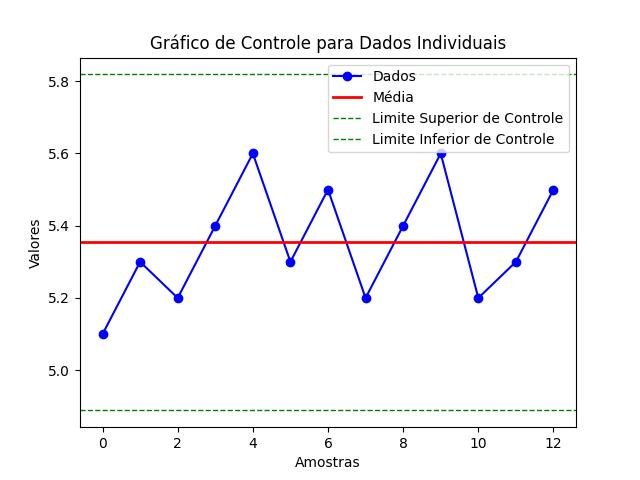
Neste exemplo, definimos um conjunto de dados de exemplo e calculamos a média e o desvio padrão dos dados. Com base nesses valores, calculamos as linhas de controle superior e inferior, que estão a três desvios padrão de distância da média.
Em seguida, usamos a função plt.plot() para traçar os pontos dos dados e a linha média. Também adicionamos as linhas de controle superior e inferior usando a função plt.axhline(), especificando a posição e o estilo das linhas.
Finalmente, personalizamos o gráfico com um título, rótulos nos eixos x e y, e uma legenda para indicar as diferentes linhas.
Você pode adaptar o exemplo de código para atender aos seus próprios dados, definindo seus próprios valores de limite e personalizando o estilo do gráfico de controle. A biblioteca matplotlib oferece várias opções para formatação e customização de gráficos.
1.2.7.2.19 - Gráfico de densidade
O gráfico de densidade é uma visualização que representa a distribuição de probabilidade de uma variável contínua. Ele é usado para entender a forma da distribuição dos dados e identificar a concentração de valores em diferentes regiões.
A área sob o gráfico de densidade representa a probabilidade de uma observação cair em uma determinada faixa de valores. Quanto maior a área em uma região específica, maior a probabilidade de encontrar valores nessa faixa.
Existem várias maneiras de criar um gráfico de densidade em Python. Uma das bibliotecas mais comumente usadas é o matplotlib, juntamente com o módulo seaborn. Aqui está um exemplo de código usando essas bibliotecas:
import seaborn as sns
import matplotlib.pyplot as plt
# Dados de exemplo
dados = [1.2, 1.5, 1.6, 1.8, 2.0, 2.2, 2.4, 2.6, 2.8, 3.0, 3.2, 3.3, 3.4]
# Criar o gráfico de densidade
sns.kdeplot(dados)
# Personalizar o gráfico
plt.title('Gráfico de Densidade')
plt.xlabel('Valores')
plt.ylabel('Densidade')
# Exibir o gráfico
plt.show()
Neste exemplo, utilizamos a função kdeplot da biblioteca seaborn para criar o gráfico de densidade. Passamos os dados de exemplo como argumento para a função.
Em seguida, personalizamos o gráfico definindo um título, rótulos nos eixos x e y.
Finalmente, utilizamos a função plt.show() para exibir o gráfico de densidade.
O gráfico de densidade pode ser útil para identificar se os dados estão concentrados em torno de um único pico (distribuição unimodal) ou se há múltiplos picos (distribuição multimodal). Ele também permite visualizar a forma da distribuição, como assimetrias ou caudas longas.
Além do seaborn, outras bibliotecas como numpy e scipy também fornecem funções para criar gráficos de densidade. A escolha da biblioteca depende das suas preferências e das funcionalidades específicas que você deseja utilizar.
1.2.7.2.20 - Gráfico de heat map
O gráfico de heatmap, ou mapa de calor, é uma representação visual de dados onde as cores são usadas para mostrar a intensidade ou magnitude de uma variável em uma matriz de valores. É frequentemente usado para visualizar a relação entre duas variáveis em uma grade ou tabela.
A biblioteca matplotlib em Python oferece suporte para criar gráficos de heatmap. Aqui está um exemplo de código que utiliza a biblioteca matplotlib para criar um gráfico de heatmap:
import numpy as np
import matplotlib.pyplot as plt
# Dados de exemplo
dados = np.random.rand(5, 5) # Matriz de valores aleatórios 5x5
# Criar o gráfico de heatmap
plt.imshow(dados, cmap='hot', interpolation='nearest')
# Personalizar o gráfico
plt.title('Gráfico de Heatmap')
plt.colorbar()
# Exibir o gráfico
plt.show()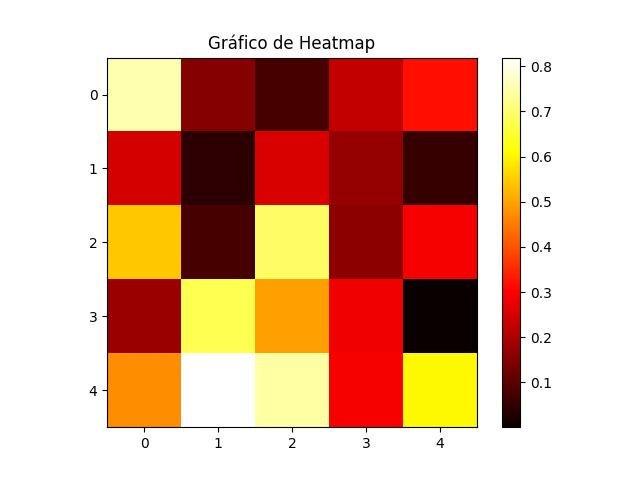
Neste exemplo, usamos a função imshow() para criar o gráfico de heatmap. Passamos a matriz de valores de exemplo (dados) como argumento para a função. Também especificamos a paleta de cores usando o parâmetro cmap, que neste caso foi definido como 'hot' para usar uma paleta de cores quentes.
Além disso, personalizamos o gráfico com um título e adicionamos uma barra de cores usando a função colorbar() para indicar a escala de cores e a correspondência entre valores e cores.
O gráfico de heatmap é especialmente útil quando você tem uma matriz de dados e deseja visualizar a distribuição e os padrões dessa matriz. Ele pode ser usado em várias áreas, como análise de dados, ciência de dados, visualização de correlações, análise de desempenho, entre outros.
Você pode adaptar o exemplo de código para os seus próprios dados, modificando a matriz dados e personalizando outros aspectos do gráfico, como título, rótulos dos eixos, paleta de cores e interpolação (parâmetro interpolation). A biblioteca matplotlib oferece diversas opções de personalização para gráficos de heatmap.
1.2.7.3 - Gráficos compostos
Gráficos compostos, também conhecidos como gráficos combinados ou gráficos múltiplos, referem-se à criação de visualizações que combinam diferentes tipos de gráficos em uma única figura. Essa técnica é usada para mostrar múltiplas informações ou aspectos de um conjunto de dados em um único espaço visual.
A ideia por trás dos gráficos compostos é aproveitar os pontos fortes de diferentes tipos de gráficos para fornecer uma representação mais abrangente e compreensível dos dados. Por exemplo, você pode combinar um gráfico de linha com um gráfico de barras, um gráfico de área com um gráfico de dispersão, ou qualquer outra combinação que seja relevante para os dados em questão.
Existem várias razões pelas quais os gráficos compostos são úteis:
- Visualização de diferentes variáveis: Ao combinar diferentes tipos de gráficos, é possível exibir e comparar múltiplas variáveis ao mesmo tempo. Isso ajuda a identificar padrões, relações e tendências nos dados que podem não ser evidentes em uma única visualização.
- Contextualização dos dados: Gráficos compostos permitem incluir informações adicionais ou contextuais para auxiliar na interpretação dos dados. Por exemplo, você pode adicionar linhas de referência, anotações, legendas ou outras informações relevantes.
- Comparação visual: Ao colocar diferentes gráficos lado a lado, é possível fazer comparações visuais diretas entre eles. Isso é especialmente útil para destacar diferenças, semelhanças ou padrões entre diferentes conjuntos de dados ou categorias.
- Comunicação efetiva: Gráficos compostos podem fornecer uma representação visual mais rica e informativa dos dados, o que facilita a comunicação de informações complexas de maneira clara e concisa.
A criação de gráficos compostos pode ser feita usando bibliotecas de visualização de dados em Python, como matplotlib e seaborn. Essas bibliotecas fornecem recursos flexíveis para combinar diferentes tipos de gráficos em uma única figura, permitindo que você personalize a aparência e o layout do gráfico composto de acordo com suas necessidades.
Ao criar gráficos compostos, é importante garantir que a combinação de gráficos seja lógica e facilite a compreensão dos dados. É fundamental escolher os tipos de gráficos apropriados e posicionar os elementos de forma clara e organizada. A legibilidade e a clareza da informação devem ser priorizadas para garantir que os usuários possam extrair insights significativos dos gráficos compostos.
Existem várias maneiras de combinar diferentes tipos de gráficos para criar gráficos compostos. Alguns dos tipos mais comuns de gráficos compostos são:
- Gráfico de linhas com gráfico de barras: Essa combinação é útil quando se deseja comparar uma tendência ao longo do tempo (gráfico de linhas) com valores específicos em pontos de dados individuais (gráfico de barras).
- Gráfico de dispersão com linha de regressão: Isso permite visualizar a relação entre duas variáveis usando um gráfico de dispersão e, ao mesmo tempo, traçar uma linha de regressão para identificar a tendência geral dos dados.
- Gráfico de barras empilhadas: Nesse tipo de gráfico, as barras são divididas em segmentos, representando diferentes categorias ou grupos dentro de cada barra. Isso é útil para comparar a distribuição de uma variável em diferentes grupos.
- Gráfico de área empilhada: Semelhante ao gráfico de barras empilhadas, mas usando áreas coloridas em vez de barras para representar as proporções ou distribuição de diferentes categorias ou grupos.
- Gráfico de barras e gráfico de setores: Essa combinação é útil quando se deseja exibir valores absolutos (gráfico de barras) e proporções relativas (gráfico de setores) de diferentes categorias em um único gráfico.
- Gráfico de dispersão com tamanho de bolhas: Nesse tipo de gráfico, os pontos de dados são exibidos em um gráfico de dispersão, mas o tamanho das bolhas é usado para representar uma terceira variável. Isso permite visualizar a relação entre duas variáveis e ao mesmo tempo mostrar a magnitude de uma terceira variável.
Esses são apenas alguns exemplos de combinações de gráficos compostos. A escolha dos tipos de gráficos a serem combinados depende dos dados e das informações que você deseja comunicar. A criatividade e a compreensão dos dados são fundamentais para criar gráficos compostos eficazes e informativos.
1.2.7.3.1 - Gráfico de linhas com gráfico de barras
O gráfico de linhas com gráfico de barras é uma combinação visual de dois tipos de gráficos: o gráfico de linhas e o gráfico de barras. Essa combinação é útil quando se deseja mostrar uma tendência ao longo do tempo usando um gráfico de linhas e, ao mesmo tempo, exibir valores específicos em pontos de dados individuais usando um gráfico de barras.
O gráfico de linhas é adequado para visualizar uma tendência contínua ou progressão ao longo do eixo x, geralmente representando o tempo. Os pontos de dados são conectados por uma linha, mostrando a variação da variável ao longo do tempo ou de outro fator contínuo.
Por outro lado, o gráfico de barras é usado para representar valores discretos ou categorias distintas. Cada barra representa um valor específico em uma categoria ou grupo. Essas barras podem ser organizadas lado a lado ou empilhadas para comparar os valores entre as categorias.
Ao combinar esses dois tipos de gráficos, é possível mostrar a tendência geral dos dados ao longo do tempo (gráfico de linhas) e, ao mesmo tempo, destacar valores específicos em momentos específicos (gráfico de barras).
Aqui está um exemplo de código em Python usando as bibliotecas matplotlib e seaborn para criar um gráfico de linhas com gráfico de barras:
import matplotlib.pyplot as plt
import seaborn as sns
# Dados de exemplo
anos = [2010, 2011, 2012, 2013, 2014, 2015]
valores_linha = [50, 60, 55, 70, 80, 75]
valores_barra = [45, 55, 60, 65, 70, 75]
# Criar a figura e os eixos
fig, ax1 = plt.subplots()
# Plotar o gráfico de linhas
ax1.plot(anos, valores_linha, marker='o', color='blue')
ax1.set_xlabel('Anos')
ax1.set_ylabel('Valores Linha', color='blue')
# Plotar o gráfico de barras
ax2 = ax1.twinx()
ax2.bar(anos, valores_barra, alpha=0.5, color='red')
ax2.set_ylabel('Valores Barra', color='red')
# Personalizar o gráfico
plt.title('Gráfico de Linhas com Gráfico de Barras')
plt.grid(True)
# Exibir o gráfico
plt.show()
Nesse exemplo, temos os dados de exemplo representando os anos e os valores correspondentes para o gráfico de linhas (valores_linha) e o gráfico de barras (valores_barra).
Usamos a função plt.subplots() para criar a figura e os eixos. Em seguida, plotamos o gráfico de linhas usando a função ax1.plot() e personalizamos os rótulos dos eixos x e y para o gráfico de linhas.
Depois disso, criamos o segundo conjunto de eixos ax2 usando o método ax1.twinx(). Em seguida, usamos a função ax2.bar() para plotar o gráfico de barras e definimos a cor das barras como vermelho.
Por fim, personalizamos o gráfico adicionando um título e ativando as grades. O
1.2.7.3.2 - Gráfico de dispersão com linha de regressão
O gráfico de dispersão com linha de regressão é uma combinação visual de um gráfico de dispersão e uma linha de regressão. Essa combinação é útil quando se deseja visualizar a relação entre duas variáveis usando o gráfico de dispersão e, ao mesmo tempo, traçar uma linha de regressão para identificar a tendência geral dos dados.
O gráfico de dispersão é usado para representar pares de valores em um plano cartesiano, onde cada ponto de dados é exibido como um ponto no gráfico. Ele é adequado para identificar a relação ou a correlação entre duas variáveis contínuas.
A linha de regressão, por sua vez, é uma linha que melhor se ajusta aos pontos de dados no gráfico de dispersão. Ela é calculada usando técnicas estatísticas, como regressão linear, para modelar a tendência geral dos dados e fornecer uma estimativa da relação entre as variáveis.
Aqui está um exemplo de código em Python usando as bibliotecas matplotlib e seaborn para criar um gráfico de dispersão com linha de regressão:
import matplotlib.pyplot as plt
import seaborn as sns
# Dados de exemplo
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
y = [3, 5, 7, 8, 9, 10, 11, 13, 15, 16]
# Criar o gráfico de dispersão com linha de regressão
sns.regplot(x=x, y=y)
# Personalizar o gráfico
plt.title('Gráfico de Dispersão com Linha de Regressão')
plt.xlabel('Variável X')
plt.ylabel('Variável Y')
# Exibir o gráfico
plt.show()
Nesse exemplo, temos os dados de exemplo representando as variáveis x e y. Usamos a função sns.regplot() do seaborn para criar o gráfico de dispersão com linha de regressão.
A função sns.regplot() calcula automaticamente a linha de regressão e a plota no gráfico de dispersão. Ela usa regressão linear por padrão, mas você pode especificar outros métodos de regressão, se necessário.
Em seguida, personalizamos o gráfico adicionando um título, rótulos para os eixos x e y. Depois disso, chamamos plt.show() para exibir o gráfico.
O gráfico de dispersão com linha de regressão ajuda a visualizar a tendência geral dos dados e a identificar a direção e a intensidade da relação entre as variáveis. A linha de regressão pode ser usada para fazer previsões ou inferências com base nos dados disponíveis.
1.2.7.3.3 - Gráfico de barras empilhadas
O gráfico de barras empilhadas é uma representação visual que permite comparar a distribuição de uma variável entre diferentes categorias ou grupos. Nesse tipo de gráfico, as barras são empilhadas uma sobre a outra, mostrando a contribuição de cada categoria para o total.
Esse tipo de gráfico é útil quando se deseja visualizar não apenas os valores absolutos de cada categoria, mas também a proporção relativa de cada categoria dentro do total. Isso facilita a comparação das contribuições individuais e a identificação de padrões ou tendências.
Aqui está um exemplo de código em Python usando as bibliotecas matplotlib e seaborn para criar um gráfico de barras empilhadas:
import matplotlib.pyplot as plt
# Dados de exemplo
categorias = ['A', 'B', 'C', 'D']
valores1 = [10, 15, 12, 8]
valores2 = [5, 8, 6, 9]
valores3 = [7, 9, 11, 6]
# Criar o gráfico de barras empilhadas
plt.bar(categorias, valores1, label='Grupo 1')
plt.bar(categorias, valores2, bottom=valores1, label='Grupo 2')
plt.bar(categorias, valores3, bottom=[i+j for i,j in zip(valores1, valores2)], label='Grupo 3')
# Personalizar o gráfico
plt.title('Gráfico de Barras Empilhadas')
plt.xlabel('Categorias')
plt.ylabel('Valores')
plt.legend()
# Exibir o gráfico
plt.show()
Nesse exemplo, temos os dados de exemplo representando as categorias (categorias) e os valores correspondentes para três grupos (valores1, valores2 e valores3).
Usamos a função plt.bar() para criar as barras empilhadas. Cada chamada dessa função representa um grupo diferente, onde passamos os valores correspondentes e usamos o parâmetro bottom para especificar a base das barras empilhadas. A base é calculada somando os valores dos grupos anteriores.
Depois disso, personalizamos o gráfico adicionando um título, rótulos para os eixos x e y, e uma legenda para identificar cada grupo.
O gráfico de barras empilhadas permite visualizar as contribuições relativas de cada categoria dentro do total. É útil para comparar a distribuição de uma variável entre diferentes grupos e identificar padrões ou discrepâncias entre as categorias.
1.2.7.3.4 - Gráfico de área empilhada
Com certeza! O gráfico de área empilhada é uma representação visual que permite comparar a distribuição de diferentes categorias ou grupos ao longo de um eixo, mostrando como as áreas coloridas se acumulam uma sobre a outra.
Esse tipo de gráfico é semelhante ao gráfico de barras empilhadas, mas em vez de usar barras retangulares, ele usa áreas coloridas para representar as proporções ou distribuição de cada categoria em relação ao total.
O gráfico de área empilhada é útil quando se deseja visualizar tanto a contribuição individual de cada categoria quanto a distribuição geral de todas as categorias. Ele permite analisar as mudanças nas proporções ao longo do tempo ou em diferentes grupos, destacando as áreas de maior ou menor contribuição.
Aqui está um exemplo de código em Python usando as bibliotecas matplotlib e seaborn para criar um gráfico de área empilhada:
import matplotlib.pyplot as plt
# Dados de exemplo
categorias = ['A', 'B', 'C', 'D']
valores1 = [10, 15, 12, 8]
valores2 = [5, 8, 6, 9]
valores3 = [7, 9, 11, 6]
# Criar o gráfico de área empilhada
plt.stackplot(categorias, valores1, valores2, valores3, labels=['Grupo 1', 'Grupo 2', 'Grupo 3'])
# Personalizar o gráfico
plt.title('Gráfico de Área Empilhada')
plt.xlabel('Categorias')
plt.ylabel('Valores')
plt.legend(loc='upper left')
# Exibir o gráfico
plt.show()
Nesse exemplo, temos os dados de exemplo representando as categorias (categorias) e os valores correspondentes para três grupos (valores1, valores2 e valores3).
Usamos a função plt.stackplot() para criar o gráfico de área empilhada. Passamos as categorias e os valores de cada grupo como argumentos, e usamos o parâmetro labels para definir as legendas para cada grupo.
Depois disso, personalizamos o gráfico adicionando um título, rótulos para os eixos x e y, e uma legenda para identificar cada grupo.
O gráfico de área empilhada permite visualizar a distribuição de diferentes categorias em relação ao total. É útil para mostrar as proporções relativas das categorias e identificar quais categorias têm maior ou menor contribuição. Além disso, ele permite analisar as mudanças nas proporções ao longo do tempo ou em diferentes grupos.
1.2.7.3.5 - Gráfico de barras e gráfico de setores
Certamente! O gráfico de barras e o gráfico de setores (ou gráfico de pizza) são dois tipos populares de gráficos usados para visualizar dados categorizados. Eles têm finalidades diferentes, mas ambos são eficazes na representação de informações em formato visual.
O gráfico de barras é adequado para comparar valores entre diferentes categorias. Ele consiste em barras retangulares que são proporcionais aos valores que representam. Cada categoria é representada por uma barra individual, e a altura da barra indica o valor correspondente.
Por outro lado, o gráfico de setores é ideal para mostrar a composição ou a distribuição relativa de partes em relação a um todo. Ele usa setores circulares para representar cada categoria, onde o tamanho do setor é proporcional à proporção da categoria em relação ao total. Os setores são agrupados em um círculo completo que representa o total.
Aqui está um exemplo de código em Python usando a biblioteca matplotlib para criar um gráfico de barras e um gráfico de setores:
import matplotlib.pyplot as plt
# Dados de exemplo
categorias = ['A', 'B', 'C', 'D']
valores = [20, 35, 30, 15]
# Gráfico de barras
plt.subplot(121)
plt.bar(categorias, valores)
plt.title('Gráfico de Barras')
# Gráfico de setores
plt.subplot(122)
plt.pie(valores, labels=categorias, autopct='%1.1f%%')
plt.title('Gráfico de Setores')
# Ajustar o layout
plt.tight_layout()
# Exibir os gráficos
plt.show()
Nesse exemplo, temos os dados de exemplo representando as categorias (categorias) e os valores correspondentes (valores).
Usamos a função plt.bar() para criar o gráfico de barras, passando as categorias e os valores como argumentos.
Para o gráfico de setores, usamos a função plt.pie(). Passamos os valores e as categorias como argumentos e usamos o parâmetro autopct para formatar as porcentagens exibidas nos setores.
Em seguida, ajustamos o layout usando plt.tight_layout() para evitar sobreposição de elementos nos gráficos.
Por fim, chamamos plt.show() para exibir os gráficos.
O gráfico de barras é eficaz para comparar valores entre categorias, enquanto o gráfico de setores destaca a composição ou a distribuição relativa das categorias em relação ao todo. A escolha entre esses gráficos depende do objetivo de comunicação e do tipo de informação que se deseja destacar.
1.2.7.3.6 - Gráfico de dispersão com tamanho de bolhas
O gráfico de dispersão com tamanho de bolhas (bubble chart) é uma variação do gráfico de dispersão em que o tamanho das bolhas é usado para representar uma terceira variável. Ele é útil para visualizar a relação entre duas variáveis contínuas, como em um gráfico de dispersão tradicional, enquanto o tamanho das bolhas representa uma medida adicional.
Nesse tipo de gráfico, cada ponto no gráfico de dispersão é representado por uma bolha, onde a posição horizontal e vertical das bolhas indica os valores das duas variáveis em análise, e o tamanho das bolhas é determinado por uma terceira variável.
O gráfico de dispersão com tamanho de bolhas permite exibir a relação entre as duas variáveis principais, enquanto adiciona uma dimensão extra por meio do tamanho das bolhas. Isso pode fornecer informações adicionais sobre a intensidade ou a magnitude da terceira variável.
Aqui está um exemplo de código em Python usando as bibliotecas matplotlib e seaborn para criar um gráfico de dispersão com tamanho de bolhas:
import matplotlib.pyplot as plt
import seaborn as sns
# Dados de exemplo
x = [1, 2, 3, 4, 5]
y = [10, 15, 7, 12, 8]
sizes = [30, 50, 20, 40, 10]
# Criar o gráfico de dispersão com tamanho de bolhas
plt.scatter(x, y, s=sizes)
# Personalizar o gráfico
plt.title('Gráfico de Dispersão com Tamanho de Bolhas')
plt.xlabel('Variável X')
plt.ylabel('Variável Y')
# Exibir o gráfico
plt.show()
Nesse exemplo, temos os dados de exemplo representando as variáveis x e y, e também a variável sizes, que representa os tamanhos das bolhas.
Usamos a função plt.scatter() para criar o gráfico de dispersão com tamanho de bolhas. Passamos os valores de x e y como argumentos, e especificamos os tamanhos das bolhas usando o parâmetro s e fornecendo a lista de sizes.
Em seguida, personalizamos o gráfico adicionando um título, rótulos para os eixos x e y.
O gráfico de dispersão com tamanho de bolhas ajuda a visualizar a relação entre as duas variáveis principais e a terceira variável representada pelo tamanho das bolhas. É útil para identificar padrões ou tendências e também para destacar a magnitude ou a intensidade da terceira variável em relação aos valores das duas variáveis principais.
