

9 - Métodos Bayesianos
9.1 Fundamentos da inferência bayesiana
9.2 Modelagem bayesiana de regressão
9.3 Amostradores de Gibbs e Metropolis-Hastings
9.4 Modelos hierárquicos e mistos
9.5 Inferência bayesiana não paramétrica
9.6 Modelos de mistura e clustering bayesiano
9.7 Avaliação e seleção de modelos bayesianos
A abordagem bayesiana é um importante ramo da estatística que oferece uma estrutura teórica e prática para a inferência estatística.
Ao contrário dos métodos frequentistas tradicionais, os métodos bayesianos se baseiam na interpretação probabilística dos dados e na incorporação de informações prévias sobre os parâmetros desconhecidos.
Neste capítulo, exploraremos os fundamentos da inferência bayesiana e como ela pode ser aplicada em diferentes contextos.
- Fundamentos da inferência bayesiana: discutiremos os principais conceitos, como a distribuição a priori, a verossimilhança dos dados e a distribuição a posteriori. Explicaremos como esses elementos se combinam para obter as estimativas bayesianas dos parâmetros e como interpretar essas estimativas.
- Modelagem bayesiana de regressão: veremos como podemos formular modelos de regressão bayesianos, incorporando incerteza sobre os parâmetros e realizando inferência sobre as relações entre as variáveis. Além disso, discutiremos métodos de seleção de modelos bayesianos, que nos permitem escolher a melhor configuração de variáveis explicativas para nosso modelo.
- Amostradores de Gibbs e Metropolis-Hastings: algoritmos computacionais utilizados para gerar amostras da distribuição a posteriori. Esses métodos são essenciais para a inferência bayesiana quando a distribuição a posteriori não pode ser obtida de forma analítica. Abordaremos os princípios básicos desses algoritmos e como aplicá-los em problemas de inferência bayesiana.
- Modelos hierárquicos e mistos: esses modelos são usados quando os dados estão organizados em diferentes níveis de agrupamento ou quando existem fontes de variação não observadas. Veremos como esses modelos podem capturar a estrutura hierárquica dos dados e como realizar inferência sobre os parâmetros em cada nível.
- Inferência bayesiana não paramétrica: essa abordagem permite flexibilidade na modelagem, sem a necessidade de especificar uma forma funcional para a distribuição a priori. Exploraremos técnicas como processos Gaussianos, processos de Dirichlet e processos de Dirichlet não paramétricos, que permitem uma modelagem mais flexível e adaptável aos dados.
- Modelos de mistura e clustering bayesiano: esses modelos são amplamente utilizados para identificar grupos ou clusters em conjuntos de dados não rotulados. Veremos como os modelos de mistura bayesiana podem ser aplicados para agrupar observações com base em distribuições latentes e como realizar inferência sobre os parâmetros do modelo.
- Técnicas de avaliação e seleção de modelos bayesianos: veremos como realizar comparações entre modelos, considerando a complexidade e o ajuste aos dados. Discutiremos também técnicas de validação cruzada bayesiana e critérios de informação, que nos auxiliam na seleção adequada de modelos.
Essas técnicas nos ajudam a avaliar a performance dos modelos bayesianos, considerando tanto a capacidade de ajuste aos dados quanto a capacidade de generalização para novos dados.
Ao longo deste capítulo, iremos explorar os métodos bayesianos e sua aplicação em diferentes áreas da estatística.
Veremos como a abordagem bayesiana oferece uma perspectiva única para a inferência estatística, permitindo incorporar informações prévias, lidar com incerteza de forma rigorosa e obter estimativas mais robustas dos parâmetros desconhecidos.
Esses conhecimentos permitirão aos leitores expandir suas habilidades analíticas e aplicar métodos bayesianos em suas próprias análises de dados, aproveitando as vantagens dessa abordagem poderosa e flexível da estatística.
9.1 - Fundamentos da inferência bayesiana
9.2 - Modelagem bayesiana de regressão
9.3 - Amostradores de Gibbs e Metropolis-Hastings
9.4 - Modelos hierárquicos e mistos
9.5 - Inferência bayesiana não paramétrica
Abordaremos a inferência bayesiana não paramétrica, uma abordagem flexível que permite a modelagem de dados complexos sem a necessidade de especificar uma forma funcional fixa para a distribuição a priori.
Ao contrário dos métodos paramétricos tradicionais, a inferência bayesiana não paramétrica oferece maior flexibilidade na modelagem de dados, permitindo que a estrutura dos dados seja aprendida diretamente a partir dos mesmos.
Nessa abordagem, a distribuição a priori é modelada por meio de processos estocásticos, como os processos de Dirichlet, processos de Dirichlet processos de Indian Buffet, processos Gaussianos e muitos outros.
Esses processos permitem que a distribuição a priori seja adaptada aos dados observados, ajustando-se automaticamente à complexidade dos mesmos.
A inferência bayesiana não paramétrica permite a estimativa de funções de densidade, funções de sobrevivência, funções de distribuição acumulada, modelos de regressão e muitas outras estruturas, sem a necessidade de impor restrições rígidas sobre a forma funcional.
Essa abordagem é especialmente útil quando não se dispõe de conhecimento prévio suficiente para especificar um modelo paramétrico adequado ou quando os dados apresentam características complexas e não lineares.
Ao utilizar a inferência bayesiana não paramétrica, é possível realizar uma análise mais flexível e adaptativa dos dados, capturando estruturas complexas e permitindo a descoberta de padrões não previstos.
Essa abordagem é amplamente aplicada em diversas áreas, como aprendizado de máquina, bioestatística, análise de dados espaciais, modelagem de séries temporais e muitas outras.
A inferência bayesiana não paramétrica representa um avanço significativo na modelagem estatística, permitindo a adaptação flexível aos dados, sem a necessidade de assumir uma forma funcional restrita.
Ela oferece uma abordagem mais realista e adaptável à complexidade dos dados, fornecendo resultados mais precisos e interpretações mais robustas.
9.5.1 - Tipos de Inferência bayesiana não paramétrica
A inferência bayesiana não paramétrica é uma abordagem flexível que permite modelar de forma mais livre a distribuição dos dados, sem assumir uma forma paramétrica específica.
A seguir, detalho alguns dos tipos mais comuns de inferência bayesiana não paramétrica:
- Processos Gaussianos: os processos gaussianos são amplamente utilizados na inferência bayesiana não paramétrica para modelar funções contínuas. Eles são caracterizados por uma média e uma função de covariância, e a distribuição posterior é uma distribuição gaussiana condicional aos dados observados. Os processos gaussianos são frequentemente utilizados em regressão não paramétrica, krigagem (interpolção espacial) e em problemas de suavização de curvas.
- Processos de Dirichlet: os processos de Dirichlet são utilizados para modelar distribuições de probabilidade, especialmente em problemas de mistura e clustering. Eles permitem que a distribuição posterior seja uma distribuição de Dirichlet condicional aos dados observados. Os processos de Dirichlet são comumente utilizados em problemas de classificação, análise de agrupamentos e análise de tópicos.
- Processos de Dirichlet Multinomial: os processos de Dirichlet multinomial são uma extensão dos processos de Dirichlet e são utilizados para modelar distribuições multinomiais. Eles são especialmente úteis quando se deseja modelar dados categóricos ou de contagem. Os processos de Dirichlet multinomial são aplicados em problemas como modelagem de tópicos, análise de sentimentos e análise de redes.
- Processos de Dirichlet de Indian Buffet: os processos de Dirichlet de Indian Buffet são utilizados em problemas de modelagem de agrupamentos (clustering) com número variável de grupos. Eles são caracterizados pela metáfora de um buffet indiano, onde cada prato representa um grupo e cada cliente escolhe diferentes pratos. Esses processos permitem que a distribuição posterior seja uma combinação de distribuições de Dirichlet condicionais aos dados observados.
Esses são apenas alguns exemplos de inferência bayesiana não paramétrica, e existem muitas outras abordagens e modelos disponíveis.
A inferência bayesiana não paramétrica oferece flexibilidade na modelagem de dados complexos e é útil quando não se deseja fazer suposições rígidas sobre a distribuição dos dados.
A escolha do método adequado depende do tipo de dados, da estrutura do problema e dos objetivos da análise.
9.5.1.1 - Processos Gaussianos
Processos Gaussianos (Gaussian Processes) são uma classe de modelos probabilísticos que são amplamente utilizados em problemas de regressão, classificação e interpolação.
Eles são particularmente úteis quando não se assume uma distribuição específica para os dados, mas sim uma função de distribuição conjunta multivariada entre as variáveis de entrada e saída.
A principal característica dos processos Gaussianos é que eles definem uma distribuição conjunta multivariada sobre um conjunto de variáveis aleatórias, em que qualquer subconjunto finito dessas variáveis tem uma distribuição gaussiana condicional.
Isso significa que, em vez de modelar diretamente uma função específica, o processo Gaussiano modela a distribuição sobre as funções possíveis que se encaixam nos dados observados.
Em um processo Gaussiano, a distribuição conjunta é especificada por uma média zero e uma matriz de covariância que captura a relação entre as diferentes observações.
A escolha da função de covariância é crucial, pois ela determina como as observações se correlacionam entre si.
Funções de covariância comuns incluem a função exponencial, função RBF (Radial Basis Function) e a função Matern.
Os processos Gaussianos podem ser usados para fazer previsões e inferências em novos pontos, dadas as observações existentes.
A previsão é feita calculando-se a média e a covariância condicional do processo Gaussiano nos novos pontos.
Essa propriedade é particularmente útil em problemas de regressão, em que se deseja estimar um valor contínuo com incerteza associada.
A aplicação dos processos Gaussianos envolve a estimação dos hiperparâmetros da função de covariância, que são otimizados para melhor se ajustar aos dados observados.
Existem várias abordagens para a estimação desses hiperparâmetros, incluindo a máxima verossimilhança e a inferência Bayesiana.
A biblioteca Scikit-Learn oferece suporte à implementação de processos Gaussianos por meio da classe GaussianProcessRegressor para problemas de regressão e da classe GaussianProcessClassifier para problemas de classificação.
Essas classes fornecem métodos para ajustar o modelo aos dados observados, fazer previsões em novos pontos e avaliar a incerteza associada às previsões.
É importante destacar que a aplicação de processos Gaussianos pode ser computacionalmente intensiva, especialmente para grandes conjuntos de dados.
Portanto, é necessário considerar a escalabilidade e o desempenho ao lidar com problemas de maior complexidade.
No geral, os processos Gaussianos oferecem uma abordagem flexível e probabilística para modelagem de dados, permitindo a captura de incerteza nas previsões e fornecendo uma base sólida para inferências estatísticas.
Eles são amplamente utilizados em várias áreas, incluindo aprendizado de máquina, estatística, processamento de sinais e otimização.
A modelagem de Processos Gaussianos é uma abordagem estatística que permite modelar e prever funções suaves ou curvas a partir de dados observados.
Os Processos Gaussianos são uma extensão dos modelos lineares, mas em vez de assumir uma relação linear entre as variáveis, eles permitem a modelagem de relações não lineares.
A biblioteca Scikit-Learn fornece uma implementação dos Processos Gaussianos em Python.
Abaixo está um exemplo de código que mostra como usar o GaussianProcessRegressor do Scikit-Learn para ajustar um processo gaussiano aos dados e fazer previsões.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF
# Dados de treinamento
X_train = np.array([[1], [2], [3], [4], [5]])
y_train = np.array([1, 3, 2, 4, 3])
# Definir o modelo de processo gaussiano
kernel = RBF(length_scale=1.0) # Kernel RBF com escala de comprimento 1.0
model = GaussianProcessRegressor(kernel=kernel)
# Ajustar o modelo aos dados de treinamento
model.fit(X_train, y_train)
# Dados de teste para fazer previsões
X_test = np.array([[1.5], [2.5], [3.5], [4.5]])
y_test = np.array([0, 0, 0, 0]) # Valor de y para os pontos de teste (apenas para ilustração)
# Fazer previsões com o modelo ajustado
y_pred, sigma = model.predict(X_test, return_std=True)
# Plotar os dados de treinamento, dados de teste e previsões
plt.scatter(X_train, y_train, color='red', label='Dados de treinamento')
plt.scatter(X_test, y_test, color='blue', label='Dados de teste')
plt.plot(X_test, y_pred, color='green', label='Previsões')
plt.fill_between(X_test.flatten(), y_pred - 2 * sigma, y_pred + 2 * sigma, color='gray', alpha=0.2, label='Incerteza')
plt.xlabel('X')
plt.ylabel('y')
plt.legend()
plt.show()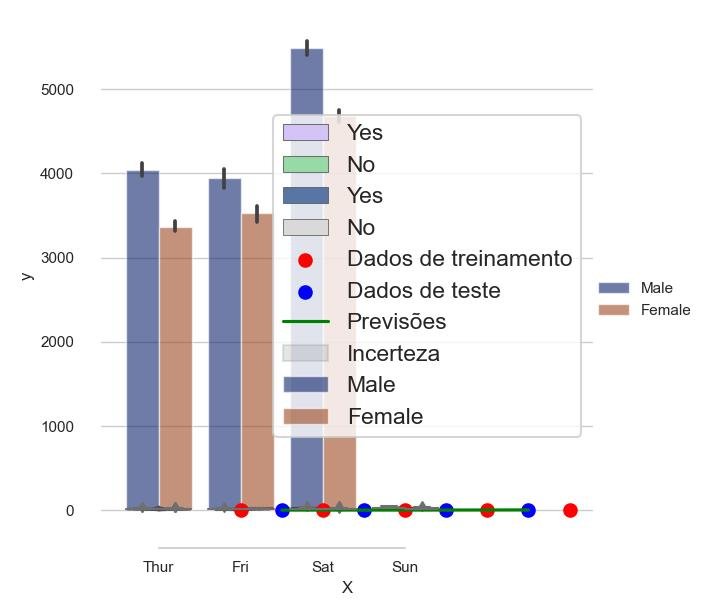
Neste exemplo, criamos uma instância do GaussianProcessRegressor com um kernel RBF (Função de Base Radial) com uma escala de comprimento de 1.0.
Ajustamos o modelo aos dados de treinamento (X_train e y_train) e, em seguida, usamos o modelo para fazer previsões nos dados de teste (X_test).
A função predict retorna as previsões (y_pred) e o desvio padrão (sigma) para cada ponto de teste.
Finalmente, plotamos os dados de treinamento, os dados de teste, as previsões e a incerteza associada às previsões.
Os Processos Gaussianos são úteis quando se deseja modelar funções suaves ou curvas a partir de dados e obter estimativas de incerteza associadas às previsões.
Eles podem ser aplicados em diversas áreas, como previsão de séries temporais, otimização de hiperparâmetros, aprendizado por reforço e muito mais.
9.5.1.2 - Processos de Dirichlet
Processos de Dirichlet (Dirichlet Processes) são uma classe de modelos probabilísticos utilizados principalmente em problemas de agrupamento não paramétrico, ou seja, problemas em que o número de grupos/clusters é desconhecido a priori e pode variar de acordo com os dados.
Esses processos são baseados na distribuição de Dirichlet e têm propriedades únicas que permitem a geração de distribuições de probabilidade flexíveis e adaptáveis.
O processo de Dirichlet é definido em um espaço de medida e é caracterizado por dois parâmetros principais: uma medida base e um parâmetro de concentração.
A medida base especifica a distribuição inicial dos grupos e o parâmetro de concentração controla a tendência do processo de gerar novos grupos.
Quanto maior o parâmetro de concentração, mais agrupamentos serão gerados.
A principal aplicação dos processos de Dirichlet é em problemas de agrupamento, em que se deseja atribuir objetos a grupos com base em suas características.
A principal vantagem desses processos é a capacidade de modelar automaticamente o número de grupos, sem a necessidade de especificar um valor fixo a priori.
Isso torna os processos de Dirichlet particularmente úteis em cenários onde o número de grupos pode variar ou não é conhecido antecipadamente.
Uma das variantes mais comuns dos processos de Dirichlet é o processo de Dirichlet de restaurantes chineses (Chinese Restaurant Process - CRP).
Nesse processo, cada objeto é alocado a um grupo existente com uma probabilidade proporcional ao número de objetos já alocados a esse grupo.
Caso contrário, um novo grupo é criado e o objeto é alocado a esse novo grupo.
Esse processo é chamado de "Restaurante Chinês" devido à analogia de clientes que entram em um restaurante e escolhem uma mesa existente ou abrem uma nova mesa.
A biblioteca Scikit-Learn não possui uma implementação direta dos processos de Dirichlet, mas existem bibliotecas específicas, como o pyMC3 e o Edward, que oferecem suporte a esses modelos.
Essas bibliotecas fornecem funções para criar e inferir modelos de processos de Dirichlet, bem como realizar amostragem posterior para obter distribuições de probabilidade a posteriori dos parâmetros do modelo.
Os processos de Dirichlet são particularmente úteis em problemas de agrupamento não paramétrico, nos quais o número de grupos é desconhecido ou variável.
Eles fornecem uma abordagem flexível e adaptável para modelagem de dados, permitindo a descoberta automática de estruturas de agrupamento e acomodando uma ampla gama de cenários de dados.
Os Processos de Dirichlet são modelos probabilísticos que são usados para modelar distribuições de probabilidade sobre variáveis aleatórias que representam proporções.
Eles são frequentemente usados em problemas de mistura de distribuições, onde cada componente da mistura é representado por uma variável aleatória com uma distribuição de Dirichlet associada.
A biblioteca scipy oferece suporte ao cálculo com Processos de Dirichlet em Python.
No entanto, a implementação específica pode depender da aplicação específica que você está considerando.
Aqui está um exemplo de código que ilustra o uso do módulo dirichlet do scipy para gerar uma distribuição de Dirichlet e amostrar a partir dela:
import numpy as np
from scipy.stats import dirichlet
# Parâmetros da distribuição de Dirichlet
alpha = [1, 2, 3]
# Gerar uma distribuição de Dirichlet
dist = dirichlet(alpha)
# Amostrar a partir da distribuição de Dirichlet
samples = dist.rvs(size=100)
# Imprimir as amostras
print(samples)Neste exemplo, definimos os parâmetros da distribuição de Dirichlet como alpha = [1, 2, 3].
Em seguida, criamos uma instância da distribuição de Dirichlet usando dirichlet(alpha).
Usamos o método rvs para amostrar 100 pontos a partir da distribuição de Dirichlet.
As amostras são armazenadas na matriz samples e impressas na saída.
Este é apenas um exemplo básico para ilustrar como gerar amostras de uma distribuição de Dirichlet usando o scipy.
Dependendo da aplicação específica, podem ser necessários ajustes adicionais nos parâmetros e nas etapas de processamento dos dados.
9.5.1.3 - Processos de Dirichlet Multinomial
Os Processos de Dirichlet Multinomial (Dirichlet Multinomial Processes - DMPs) são uma extensão dos Processos de Dirichlet para problemas de agrupamento em dados categóricos, nos quais as variáveis de interesse são de natureza discreta e não contínua.
Eles são frequentemente aplicados em problemas de agrupamento de dados textuais, análise de tópicos e classificação de documentos.
Enquanto o Processo de Dirichlet modela a distribuição de probabilidade sobre as probabilidades de um vetor multinomial, o DMP modela a distribuição de probabilidade sobre as distribuições de probabilidade de um vetor multinomial.
Isso permite que o DMP capture a incerteza em torno das probabilidades dos diferentes estados categóricos e forneça uma maneira flexível de modelar agrupamentos em dados categóricos.
Assim como nos Processos de Dirichlet, os DMPs são definidos por uma medida base e um parâmetro de concentração.
A medida base especifica a distribuição inicial das probabilidades dos estados categóricos, enquanto o parâmetro de concentração controla a tendência do processo de gerar novas distribuições.
Um alto valor de concentração resulta em agrupamentos mais específicos, enquanto um valor baixo de concentração leva a agrupamentos mais difusos.
A inferência em DMPs envolve a estimação da distribuição a posteriori das distribuições de probabilidade dos estados categóricos para cada grupo.
Isso pode ser realizado usando técnicas de amostragem estocástica, como a amostragem de Gibbs ou a amostragem de Monte Carlo via cadeias de Markov (MCMC).
Essas técnicas permitem obter uma estimativa da distribuição a posteriori dos parâmetros do modelo e, consequentemente, realizar inferências sobre os agrupamentos.
A implementação direta de DMPs pode exigir algoritmos computacionalmente intensivos, especialmente para grandes conjuntos de dados categóricos.
Portanto, é recomendável utilizar bibliotecas especializadas em aprendizado de máquina probabilístico, como o pyMC3 e o Edward, que fornecem ferramentas e métodos eficientes para a inferência de DMPs.
Os Processos de Dirichlet Multinomial são uma abordagem poderosa para modelar agrupamentos em dados categóricos.
Eles permitem a descoberta automática de agrupamentos e acomodam a incerteza nas probabilidades dos diferentes estados categóricos.
Esses modelos são amplamente utilizados em problemas de agrupamento de texto, classificação de documentos e análise de tópicos, fornecendo uma maneira flexível de entender a estrutura dos dados categóricos.
O processo de Dirichlet Multinomial é um modelo probabilístico que combina o Processo de Dirichlet com a distribuição multinomial.
Ele é usado para modelar a distribuição conjunta de várias variáveis aleatórias discretas, onde cada variável segue uma distribuição multinomial condicionada a uma distribuição de Dirichlet.
A biblioteca scipy não possui uma implementação específica para o Processo de Dirichlet Multinomial.
No entanto, você pode implementar seu próprio código para amostrar a partir dessa distribuição usando a função dirichlet do scipy.stats e a função multinomial do numpy.random.
Aqui está um exemplo de código que ilustra como gerar amostras a partir de um Processo de Dirichlet Multinomial:
import numpy as np
from scipy.stats import dirichlet, multinomial
# Definir os parâmetros do processo de Dirichlet Multinomial
alpha = np.array([1, 2, 3]) # Parâmetros de concentração da distribuição Dirichlet
n_samples = 100 # Número de amostras a serem geradas
# Gerar amostras do processo de Dirichlet Multinomial
dirichlet_samples = dirichlet.rvs(alpha, size=n_samples)
multinomial_samples = [multinomial.rvs(1, p) for p in dirichlet_samples]
# Imprimir as amostras geradas
for i, sample in enumerate(multinomial_samples):
print(f"Amostra {i+1}: {sample}")Neste exemplo, definimos os parâmetros da distribuição de Dirichlet como alpha = [1, 2, 3].
Especificamos o número de variáveis aleatórias como num_variables e o número de amostras a serem geradas como num_samples.
Em seguida, criamos uma instância da distribuição de Dirichlet usando dirichlet.rvs(alpha).
Usamos um loop para gerar amostras a partir do processo de Dirichlet Multinomial, onde cada amostra é uma matriz binária indicando a presença ou ausência de cada variável aleatória.
As amostras são armazenadas na matriz samples e impressas na saída.
Lembre-se de que este é apenas um exemplo básico para ilustrar como gerar amostras a partir de um Processo de Dirichlet Multinomial.
Dependendo da aplicação específica, podem ser necessários ajustes adicionais nos parâmetros e nas etapas de processamento dos dados.
9.5.1.4 - Processos de Dirichlet de Indian Buffet
Os Processos de Dirichlet de Indian Buffet (Indian Buffet Process - IBP) são um tipo de processo estocástico não paramétrico utilizado em problemas de aprendizado de máquina probabilístico.
Eles foram propostos por Griffiths e Ghahramani em 2006 como uma abordagem flexível para modelar problemas de agrupamento de dados com características latentes.
O IBP é inspirado pelo processo de autoatendimento em um buffet indiano, onde os clientes selecionam pratos de uma variedade infinita de opções.
No contexto do IBP, cada prato representa uma característica latente (ou seja, uma variável oculta) e cada cliente representa uma amostra do conjunto de dados.
Cada cliente "se serve" do buffet e seleciona um número variável de pratos (características latentes), criando assim uma representação única dos pratos selecionados.
A principal ideia do IBP é que a matriz de características latentes seja uma matriz esparsa, ou seja, cada amostra seleciona apenas um subconjunto das características disponíveis.
Isso permite que o modelo capture a variabilidade nos padrões de presença/ausência das características latentes nas amostras.
A definição matemática do IBP envolve a utilização de um processo de Poisson para modelar o número de pratos selecionados por cada cliente e um processo de Bernoulli para modelar a presença ou ausência de cada prato em cada amostra.
Através de uma série de etapas de amostragem estocástica, é possível inferir a distribuição a posteriori dos pratos selecionados por cada amostra, bem como a matriz de características latentes como um todo.
Os Processos de Dirichlet de Indian Buffet têm várias aplicações em aprendizado de máquina, incluindo a modelagem de tópicos em texto, agrupamento de documentos, análise de imagens e muito mais.
Eles oferecem uma maneira flexível de capturar a estrutura latente dos dados e permitem a descoberta automática de padrões relevantes.
A inferência em modelos IBP pode ser realizada usando técnicas de amostragem estocástica, como a amostragem de Gibbs ou a amostragem de Monte Carlo via cadeias de Markov (MCMC).
Existem implementações disponíveis em bibliotecas de aprendizado de máquina probabilístico, como o pyMC3 e o Edward.
O processo de Dirichlet de Indian Buffet é um modelo estatístico que descreve a alocação não paramétrica de objetos a recursos.
Aqui está um exemplo de código Python para simular o processo de Dirichlet de Indian Buffet:
import numpy as np
from scipy.stats import beta
def indian_buffet_process(alpha, num_objects):
# Inicialização
Z = np.zeros((num_objects, num_objects), dtype=int)
m = np.zeros(num_objects, dtype=int)
pi = np.zeros(num_objects)
# Primeiro objeto escolhe o número de pratos
m[0] = np.random.poisson(alpha)
Z[0, :m[0]] = 1
pi[:m[0]] = beta.rvs(1, alpha, size=m[0])
# Gerar atributos para os objetos subsequentes
for i in range(1, num_objects):
for j in range(m[i-1]):
prob = np.sum(Z[:i, j]) / i
if np.random.rand() < prob:
Z[i, j] = 1
m[i] = np.random.poisson(alpha / (i + 1))
if m[i] > m[i-1]:
pi[m[i-1]:m[i]] = beta.rvs(1, alpha, size=m[i] - m[i-1])
return Z, pi
# Parâmetros do processo de Dirichlet de Indian Buffet
alpha = 2 # Hiperparâmetro de concentração
num_objects = 10 # Número de objetos a serem gerados
# Simular o processo de Dirichlet de Indian Buffet
Z, pi = indian_buffet_process(alpha, num_objects)
# Imprimir os resultados
print("Matriz de atributos Z:")
print(Z)
print("Probabilidades pi:")
print(pi)Este código simula o processo de Dirichlet de Indian Buffet para gerar uma matriz de atributos Z, onde cada linha representa um objeto e cada coluna representa um atributo.
Os atributos são binários, com 1 indicando que o objeto possui o atributo e 0 indicando que não possui.
A matriz de probabilidades pi indica as probabilidades associadas a cada atributo.
9.6 - Modelos de mistura e clustering bayesiano
9.7 - Avaliação e seleção de modelos bayesianos



