

7 - Séries Temporais
7.1 Modelos autoregressivos (AR) e de médias móveis (MA)
7.2 Modelos ARMA e ARIMA
7.3 Modelos de séries temporais multivariadas
7.4 Modelos de componentes sazonais
7.5 Previsão e diagnóstico em séries temporais
Agora mergulharemos no fascinante campo das séries temporais.
As séries temporais são conjuntos de observações ordenadas no tempo, em que cada observação está associada a uma determinada marca temporal.
Esses dados são amplamente encontrados em diversos campos, como finanças, economia, meteorologia, saúde e muitos outros, e apresentam uma estrutura única e desafiadora.
Serão apresentados:
- Modelos autoregressivos (AR) e de médias móveis (MA): esses modelos são fundamentais para a compreensão das séries temporais, pois capturam a dependência serial entre as observações ao longo do tempo. Discutiremos os conceitos de autocorrelação e autocorrelação parcial, que são ferramentas essenciais para a identificação desses modelos e para o diagnóstico de sua adequação aos dados.
- Análise com os modelos ARMA e ARIMA: esses modelos combinam as características dos modelos autoregressivos e de médias móveis, permitindo modelar séries temporais mais complexas. Abordaremos os princípios de identificação, estimativa e diagnóstico desses modelos, bem como técnicas de seleção de ordem e critérios de informação para escolher o modelo mais adequado.
- Modelos de séries temporais multivariadas: nesse caso, analisaremos séries temporais com mais de uma variável observada simultaneamente. Exploraremos técnicas como o modelo de vetor autorregressivo (VAR) e o modelo de vetor autorregressivo de média móvel (VARMA), que permitem modelar as interações entre as variáveis ao longo do tempo.
- Modelos de componentes sazonais: muitas séries temporais exibem padrões sazonais, que se repetem em intervalos regulares. Abordaremos métodos para identificar, modelar e remover componentes sazonais, permitindo uma melhor compreensão da variação temporal.
- Previsão e diagnóstico em séries temporais: Exploraremos técnicas de previsão, como a suavização exponencial e a modelagem ARIMA, que nos permitem fazer projeções futuras com base nas informações passadas. Além disso, discutiremos métodos de diagnóstico para avaliar a adequação dos modelos às séries temporais e para identificar possíveis violações dos pressupostos.
Ao explorar esses tópicos, você desenvolverá uma compreensão sólida dos modelos e técnicas utilizados na análise de séries temporais, ficando apto a modelar, prever e interpretar séries temporais complexas, contribuindo para a tomada de decisões informadas em áreas que dependem do entendimento das tendências, padrões e comportamentos ao longo do tempo.
A análise de séries temporais é uma ferramenta poderosa para explorar a dinâmica temporal dos dados e fornecer insights valiosos para uma ampla gama de aplicações práticas.
7.1 - Modelos autoregressivos (AR) e de médias móveis (MA)
7.2 - Modelos ARMA e ARIMA
7.3 - Modelos de séries temporais multivariadas
7.4 - Modelos de Componentes Sazonais
7.5 - Previsão e diagnóstico em séries temporais
A previsão de séries temporais é uma área essencial da análise de dados, que visa estimar os valores futuros com base nos padrões e comportamentos observados no passado.
A capacidade de fazer previsões precisas é fundamental para tomadas de decisões estratégicas, planejamento de recursos, otimização de processos e muitos outros cenários.
Existem várias abordagens e técnicas para a previsão de séries temporais.
Uma das mais comuns é a utilização de modelos estatísticos, como os modelos ARIMA (Autoregressive Integrated Moving Average), modelos de suavização exponencial, modelos de regressão com componentes sazonais, entre outros.
Esses modelos exploram os padrões históricos da série temporal para fazer previsões futuras.
Além da previsão, o diagnóstico das séries temporais é uma etapa importante na análise.
O diagnóstico envolve a avaliação da qualidade e adequação dos modelos aplicados, bem como a identificação de possíveis problemas ou anomalias nos dados.
É fundamental realizar uma análise crítica dos resultados da previsão e avaliar a precisão do modelo.
O diagnóstico pode envolver a análise dos resíduos, que são as diferenças entre os valores observados e os valores previstos pelo modelo.
É importante verificar se os resíduos seguem uma distribuição normal, se não possuem padrões sistemáticos e se são independentes ao longo do tempo.
Essas verificações ajudam a identificar possíveis deficiências no modelo e guiam os ajustes e melhorias necessários.
A previsão e o diagnóstico em séries temporais podem ser apoiados por diversas técnicas estatísticas e ferramentas computacionais.
Além dos modelos estatísticos, também podem ser utilizados métodos de aprendizado de máquina, como redes neurais, árvores de decisão e modelos de séries temporais baseados em redes recorrentes, como LSTM (Long Short-Term Memory) e GRU (Gated Recurrent Unit).
Essas abordagens mais avançadas podem lidar com relações complexas e não lineares nos dados e capturar padrões mais sutis.
Dominar a previsão e o diagnóstico em séries temporais é essencial para a análise de dados em diversas áreas, como finanças, economia, marketing, energia, meteorologia e muitas outras.
A capacidade de antecipar tendências, identificar padrões e avaliar a qualidade dos modelos permite uma tomada de decisão mais informada e eficaz, contribuindo para o sucesso das organizações em um mundo cada vez mais orientado por dados.
O principais tipos de previsão e diagnóstico em séries temporais são:
- Previsão de curto prazo: A previsão de curto prazo envolve a estimativa dos valores futuros da série em um horizonte de tempo próximo, geralmente de alguns períodos até um ano. É amplamente utilizada em planejamento operacional, gestão de estoques, logística e outros contextos em que a tomada de decisão precisa considerar as flutuações imediatas da série.
- Previsão de longo prazo: A previsão de longo prazo envolve a projeção dos valores futuros da série em um horizonte de tempo mais amplo, geralmente além de um ano. É útil em análises estratégicas, planejamento de negócios, previsões econômicas de longo prazo e outras aplicações em que a visão de longo prazo é necessária.
- Previsão univariada: A previsão univariada refere-se à previsão de uma única série temporal. Nesse caso, apenas as informações históricas dessa série são usadas para fazer a previsão. É adequada quando estamos interessados em prever apenas uma variável de interesse, independentemente de outras séries temporais.
- Previsão multivariada: A previsão multivariada envolve a previsão simultânea de múltiplas séries temporais. Nesse caso, as informações históricas de várias séries são consideradas para fazer as previsões. É útil quando as séries temporais estão inter-relacionadas e as previsões de uma variável podem ser melhoradas considerando as informações de outras variáveis.
- Diagnóstico de modelos: O diagnóstico de modelos em séries temporais refere-se à avaliação da qualidade e adequação dos modelos utilizados para a previsão. Envolve a análise dos resíduos dos modelos, verificando se eles atendem às suposições de independência, homocedasticidade e normalidade. Também pode envolver a análise de métricas de desempenho do modelo, como erro médio absoluto (MAE), erro quadrático médio (MSE) e outros indicadores de ajuste do modelo.
Esses são os principais tipos de previsão e diagnóstico em séries temporais. Cada um deles possui abordagens e técnicas específicas, que podem variar dependendo do contexto e dos objetivos da análise.
7.5.1 - Previsão de curto prazo
7.5.2 - Previsão de longo prazo
7.5.3 - Previsão univariada
7.5.4 - Previsão multivariada
7.5.5 - Diagnóstico de modelos
O diagnóstico de modelos é uma etapa essencial na análise de séries temporais, que envolve a avaliação da qualidade e adequação do modelo ajustado aos dados observados. O objetivo é verificar se o modelo captura adequadamente os padrões e características da série temporal, identificar possíveis problemas ou violações das suposições do modelo e avaliar a confiabilidade das previsões geradas.
Existem várias técnicas e métodos disponíveis para realizar o diagnóstico de modelos de séries temporais. Alguns dos principais aspectos a serem considerados durante o diagnóstico incluem:
- Resíduos: Os resíduos são as diferenças entre os valores observados e os valores previstos pelo modelo. A análise dos resíduos é fundamental para verificar se eles apresentam comportamento aleatório, se são independentes e se não contêm informações úteis. Alguns métodos para avaliar os resíduos incluem a análise gráfica (como gráficos de dispersão, histogramas, gráficos de autocorrelação dos resíduos) e testes estatísticos (como o teste de Ljung-Box para autocorrelação dos resíduos).
- Suposições do modelo: Cada tipo de modelo de séries temporais possui suas suposições específicas. Por exemplo, os modelos ARMA assumem que a série é estacionária e que os resíduos seguem uma distribuição normal. Verificar a estacionariedade da série, a normalidade dos resíduos e outras suposições é fundamental para garantir a validade das inferências e previsões do modelo.
- Acurácia das previsões: O desempenho do modelo em termos de previsão também é um aspecto importante a ser avaliado. Comparar as previsões geradas pelo modelo com os valores observados, calcular métricas de desempenho (como erro médio absoluto, erro quadrático médio, etc.) e realizar testes estatísticos para verificar a precisão das previsões são abordagens comuns para avaliar a acurácia do modelo.
- Sensibilidade às mudanças: Verificar como o modelo se comporta em diferentes cenários ou períodos de tempo é crucial para entender sua robustez e capacidade de adaptação. Avaliar a sensibilidade do modelo a mudanças nas condições da série (por exemplo, mudanças estruturais, eventos extraordinários) e verificar se o modelo é capaz de capturar essas mudanças de forma adequada é uma parte importante do diagnóstico.
- Testes adicionais: Dependendo do contexto e dos objetivos da análise, podem ser aplicados outros testes específicos para verificar a adequação do modelo. Isso inclui testes de raiz unitária para verificar a presença de tendência ou não estacionariedade, testes de heterocedasticidade para verificar a presença de variância não constante nos resíduos, entre outros.
O diagnóstico de modelos é um processo iterativo, no qual é possível realizar ajustes e melhorias no modelo com base nas informações obtidas durante a análise.
É importante lembrar que nenhum modelo é perfeito e que o diagnóstico é uma forma de avaliar suas limitações e incertezas.
A interpretação dos resultados do diagnóstico requer conhecimento teórico e prático sobre modelos de séries temporais, além de considerar o contexto específico da aplicação.
Podemos usar a função normaltest do módulo scipy.stats para realizar um teste de normalidade nos resíduos:
import pandas as pd
import numpy as np
import statsmodels.api as sm
import scipy.stats as stats
import matplotlib.pyplot as plt
# Criar um dataframe de exemplo
data = pd.DataFrame({'data': pd.date_range('2022-01-01', periods=100, freq='M'),
'valor': np.random.rand(100),
'const': 1})
# Definir a variável data como o índice do dataframe
data.set_index('data', inplace=True)
# Ajustar o modelo SARIMAX
model = sm.tsa.SARIMAX(data['valor'], order=(1, 0, 1), seasonal_order=(1, 0, 1, 12))
model_fit = model.fit()
# Diagnosticar o modelo
model_fit.plot_diagnostics(figsize=(10, 8))
plt.show()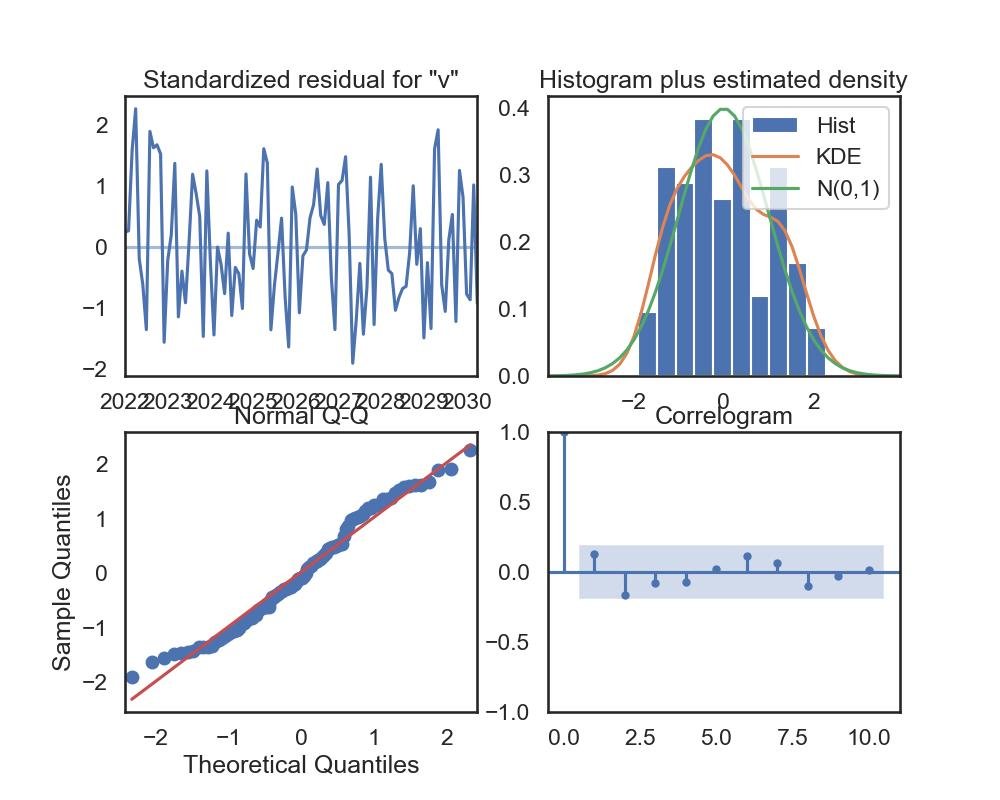
Obter os resíduos do modelo:
residuals = model_fit.residTeste de normalidade dos resíduos (Teste de Shapiro-Wilk):
shapiro_test = stats.normaltest(residuals)
#print("Teste de Shapiro-Wilk - p-value:", shapiro_test.pvalue)
print("Teste de Shapiro-Wilk:", shapiro_test)Teste de autocorrelação dos resíduos (Teste de Ljung-Box):
ljung_box_test = sm.stats.acorr_ljungbox(residuals, lags=[10])
#print("Teste de Ljung-Box - p-value:", ljung_box_test[1][0])
print("Teste de Ljung-Box:", ljung_box_test)Teste de heterocedasticidade dos resíduos (Teste de Breusch-Pagan):
breusch_pagan_test = sm.stats.diagnostic.het_breuschpagan(residuals, exog_het=data)
#print("Teste de Breusch-Pagan - p-value:", breusch_pagan_test[1])
print("Teste de Breusch-Pagan:", breusch_pagan_test[["valor","const"]])Neste código, usamos a função normaltest do módulo scipy.stats para realizar o teste de normalidade nos resíduos.
Os outros testes de diagnóstico permanecem os mesmos.



