

4 - Modelos de Regressão
4.1 Regressão linear múltipla
4.2 Modelos de regressão não linear
4.3 Modelos lineares generalizados
4.4 Análise de sobrevivência e modelos de risco proporcional
4.5 Regressão robusta e regressão de quantis
A análise de regressão é uma das ferramentas mais poderosas da estatística, permitindo-nos modelar e entender a relação entre variáveis e fazer previsões.
Exploraremos diferentes tipos de modelos de regressão, desde a regressão linear múltipla até técnicas mais avançadas e robustas.
- Regressão linear múltipla: Esta é uma extensão natural da regressão linear simples, permitindo-nos incorporar múltiplas variáveis independentes e examinar como elas se relacionam com a variável dependente. Veremos como ajustar o modelo, interpretar os coeficientes e realizar inferências sobre os efeitos das variáveis independentes. Além disso, discutiremos a importância das suposições do modelo e como diagnosticar sua adequação.
- Modelos com regressão não linear: Nem todas as relações entre variáveis podem ser adequadamente representadas por uma função linear. Portanto, aprenderemos sobre técnicas que permitem modelar relações não lineares, como curvas, polinômios e outras formas funcionais. Veremos como ajustar esses modelos e interpretar seus parâmetros, permitindo-nos capturar a complexidade das relações entre as variáveis.
- Modelos lineares generalizados (GLMs): Essa classe de modelos é uma generalização da regressão linear, permitindo-nos lidar com respostas que não seguem uma distribuição normal. Discutiremos diferentes famílias de distribuições e funções de ligação adequadas para cada tipo de resposta. Além disso, abordaremos a interpretação dos coeficientes e as inferências nos modelos GLMs.
- Análise de sobrevivência e nos modelos de risco proporcional: Esses modelos são amplamente utilizados em estudos de sobrevivência, nos quais estamos interessados em compreender o tempo até um evento ocorrer. Veremos como modelar a função de sobrevivência, estimar o risco relativo e lidar com censura dos dados. Esses modelos têm aplicações em áreas como medicina, engenharia e ciências sociais.
- Regressão robusta e a regressão de quantis: Essas técnicas são projetadas para lidar com dados que possuem características peculiares, como presença de outliers ou distribuições assimétricas. Veremos como esses modelos podem fornecer estimativas robustas e resistentes a influências atípicas, garantindo a estabilidade e confiabilidade das análises. Ao explorar os diferentes modelos de regressão neste capítulo, você terá uma compreensão aprofundada de suas aplicações, capacidades e limitações.
Aprenderá como ajustar esses modelos, interpretar seus resultados e realizar inferências adequadas.
Os modelos de regressão são uma poderosa ferramenta para extrair informações valiosas dos dados e fazer previsões precisas, permitindo-nos avançar na compreensão e no conhecimento em diversas áreas de estudo.
4.1 - Regressão linear múltipla (RLM)
A regressão linear múltipla (RLM) é uma extensão da regressão linear simples, na qual exploramos a relação entre uma variável dependente contínua e duas ou mais variáveis independentes.
Essa técnica nos permite modelar e entender como as variáveis independentes influenciam a variável dependente, levando em consideração os efeitos individuais de cada uma e suas interações.
No contexto da RLM, nosso objetivo é encontrar uma equação linear que relacione as variáveis independentes à variável dependente.
Essa equação é representada por:
- Y = β₀ + β₁X₁ + β₂X₂ + ... + βₚXₚ + ε
Onde:
- Y é a variável dependente que queremos prever;
- β₀ é o intercepto, que representa o valor médio esperado de Y quando todas as variáveis independentes são iguais a zero;
- β₁, β₂, ..., βₚ são os coeficientes de regressão que medem a influência das variáveis independentes (X₁, X₂, ..., Xₚ) em Y;
- X₁, X₂, ..., Xₚ são as variáveis independentes;
- ε é o termo de erro, que captura a variação não explicada pelo modelo.
Para estimar os coeficientes de regressão, utilizamos métodos como o método dos mínimos quadrados ordinários (OLS), que busca minimizar a soma dos quadrados dos resíduos.
Ao ajustar o modelo, também é importante verificar se as suposições da regressão linear múltipla são atendidas, como a linearidade, independência dos resíduos, homoscedasticidade e normalidade dos resíduos.
A RLM oferece várias vantagens, como permitir controlar e avaliar o efeito de múltiplas variáveis independentes simultaneamente, fornecendo uma visão mais completa e precisa das relações entre as variáveis, ou permitir realizar inferências sobre os coeficientes de regressão, como testes de significância e construção de intervalos de confiança.
A interpretação dos resultados da regressão linear múltipla envolve analisar os coeficientes de regressão para entender o efeito marginal de cada variável independente na variável dependente, levando em consideração as outras variáveis independentes presentes no modelo.
Também podemos avaliar a qualidade do ajuste do modelo por meio de métricas como o coeficiente de determinação (R²) e o erro padrão residual.
Nessa seção dedicada à RLM, você explorará em detalhes como ajustar e interpretar modelos de regressão com várias variáveis independentes, realizar inferências sobre os coeficientes e avaliar a adequação do modelo.
Você também aprenderá sobre técnicas avançadas, como a seleção de variáveis, diagnóstico de multicolinearidade e transformação de variáveis para melhorar o ajuste do modelo.
A regressão linear múltipla é uma ferramenta essencial para a análise de dados e a tomada de decisões em diversas áreas, desde as ciências sociais até a econometria e a pesquisa de mercado.
4.1.1 - Método dos mínimos quadrados ordinários (OLS)
O método dos mínimos quadrados ordinários (OLS) é uma técnica amplamente utilizada para estimar os coeficientes de um modelo de regressão linear.
Ele busca encontrar os valores dos coeficientes que minimizam a soma dos quadrados dos resíduos, ou seja, a diferença entre os valores observados e os valores previstos pelo modelo.
Aqui está um exemplo de código Python que demonstra como aplicar o método dos mínimos quadrados ordinários utilizando a biblioteca statsmodels:
import numpy as np
import statsmodels.api as sm
# Dados de exemplo
x = np.array([1, 2, 3, 4, 5])
y = np.array([2, 4, 5, 4, 6])
# Adicionando uma coluna de uns para representar a constante no modelo
X = sm.add_constant(x)
# Ajustando o modelo OLS aos dados
model = sm.OLS(y, X)
results = model.fit()
# Obtendo os coeficientes estimados
coefficients = results.params
# Obtendo o resíduo padrão
residuals = results.resid
# Exibindo os resultados
print("Coeficientes estimados:", coefficients)
print("Resíduo padrão:", np.std(residuals))Neste exemplo, temos uma variável independente x e uma variável dependente y.
Primeiro, adicionamos uma coluna de uns à matriz X usando a função sm.add_constant(), para representar a constante no modelo de regressão.
Em seguida, ajustamos o modelo OLS aos dados usando sm.OLS(y, X) e chamamos o método fit() para obter os resultados da regressão.
Os coeficientes estimados são armazenados em results.params.
Podemos calcular o resíduo padrão, que é uma medida da dispersão dos resíduos, usando results.resid e a função np.std(residuals).
Por fim, os resultados são exibidos na saída.
Certifique-se de ter a biblioteca statsmodels instalada para executar o código acima.
Você pode instalá-la usando o comando pip install statsmodels.
Ao ajustar um modelo de regressão linear múltipla utilizando o método dos mínimos quadrados ordinários (OLS), é importante verificar se as suposições da regressão linear estão sendo atendidas.
Essas suposições incluem a linearidade da relação entre as variáveis independentes e dependentes, a independência dos resíduos, a homoscedasticidade e a normalidade dos resíduos.
- Linearidade: A suposição de linearidade indica que a relação entre as variáveis independentes e a variável dependente é linear. Isso significa que os coeficientes estimados no modelo capturam adequadamente a relação linear entre as variáveis. Você pode verificar a linearidade visualizando gráficos de dispersão dos dados e avaliando se eles apresentam um padrão linear.
- Independência dos resíduos: A suposição de independência dos resíduos significa que os resíduos do modelo não devem apresentar padrões ou dependências sistemáticas. Isso implica que não deve haver correlação entre os resíduos e nenhuma estrutura de autocorrelação nos dados. Para verificar a independência dos resíduos, você pode examinar um gráfico de resíduos versus valores ajustados e também pode realizar testes estatísticos específicos para detectar a presença de autocorrelação.
- Homoscedasticidade: A suposição de homoscedasticidade indica que a variância dos resíduos é constante em todas as faixas de valores das variáveis independentes. Em outras palavras, os resíduos não devem mostrar um padrão de aumento ou diminuição da variância à medida que os valores das variáveis independentes mudam. Você pode verificar a homoscedasticidade visualizando um gráfico de resíduos versus valores ajustados ou utilizando testes estatísticos, como o teste de Breusch-Pagan ou o teste de White.
- Normalidade dos resíduos: A suposição de normalidade dos resíduos indica que os resíduos devem seguir uma distribuição normal. Isso é importante para realizar inferências estatísticas válidas e para garantir a precisão dos intervalos de confiança e dos testes de hipóteses. Você pode verificar a normalidade dos resíduos visualizando um gráfico de resíduos em relação a uma distribuição normal ou utilizando testes estatísticos, como o teste de normalidade de Shapiro-Wilk ou o teste de Kolmogorov-Smirnov.
Ao verificar essas suposições, é importante considerar que nem sempre elas serão estritamente atendidas.
Em alguns casos, pequenas violações podem ser toleradas, desde que não afetem substancialmente as inferências do modelo.
Se as suposições não forem atendidas de forma adequada, podem ser necessárias transformações nos dados, a inclusão de variáveis de controle ou a consideração de modelos alternativos.
Avaliar essas suposições é uma etapa crítica na análise de regressão linear, pois garante que os resultados do modelo sejam confiáveis e que as interpretações corretas possam ser feitas.
4.1.1.1 - Linearidade
Aqui está um exemplo de código em Python para verificar a linearidade em um modelo de regressão linear múltipla.
Vamos usar a biblioteca matplotlib para criar um gráfico de dispersão dos dados e traçar a linha de regressão.
import numpy as np
import matplotlib.pyplot as plt
# Dados de exemplo
x = np.array([1, 2, 3, 4, 5])
y = np.array([2, 4, 6, 8, 10])
# Ajuste do modelo de regressão
coefficients = np.polyfit(x, y, 1) # Grau 1 para uma regressão linear
poly = np.poly1d(coefficients)
y_pred = poly(x)
# Plotagem do gráfico de dispersão e linha de regressão
plt.scatter(x, y, color='blue', label='Dados Observados')
plt.plot(x, y_pred, color='red', label='Regressão Linear')
plt.xlabel('Variável Independente (x)')
plt.ylabel('Variável Dependente (y)')
plt.title('Gráfico de Dispersão e Regressão Linear')
plt.legend()
plt.show()
Neste exemplo, os dados são representados pelos arrays x e y.
Utilizamos a função np.polyfit para ajustar uma linha de regressão linear aos dados, com grau 1.
Em seguida, usamos a função np.poly1d para criar um polinômio com base nos coeficientes obtidos.
Com o polinômio, podemos gerar as previsões y_pred para os valores de x e traçar a linha de regressão usando plt.plot.
Também adicionamos os pontos de dados originais usando plt.scatter.
Ao executar esse código, você verá um gráfico de dispersão dos dados observados e uma linha de regressão linear que melhor se ajusta aos dados.
A visualização pode ajudar a identificar padrões lineares e avaliar se a suposição de linearidade é atendida.
4.1.1.2 - Independência dos resíduos
Aqui está um exemplo de código em Python para verificar a independência dos resíduos em um modelo de regressão linear múltipla.
Vamos usar a biblioteca statsmodels para ajustar o modelo e extrair os resíduos, e em seguida, usaremos o teste de Durbin-Watson para verificar a autocorrelação dos resíduos.
import numpy as np
import statsmodels.api as sm
from statsmodels.stats.stattools import durbin_watson
# Dados de exemplo
x1 = np.array([1, 2, 3, 4, 5])
x2 = np.array([2, 4, 6, 8, 10])
y = np.array([3, 5, 7, 9, 11])
# Adicionando uma coluna de 1's para o termo constante
X = np.column_stack((x1, x2, np.ones(len(x1))))
# Ajuste do modelo de regressão linear
model = sm.OLS(y, X)
results = model.fit()
# Cálculo dos resíduos
residuals = results.resid
# Teste de Durbin-Watson para autocorrelação dos resíduos
durbin_watson_statistic = durbin_watson(residuals)
# Impressão do resultado do teste
print("Estatística de Durbin-Watson:", durbin_watson_statistic)Neste exemplo, os dados são representados pelos arrays x1, x2 e y.
Utilizamos a biblioteca statsmodels para ajustar um modelo de regressão linear utilizando a função sm.OLS.
Em seguida, extraímos os resíduos do modelo ajustado usando results.resid.
Por fim, aplicamos o teste de Durbin-Watson aos resíduos utilizando a função durbin_watson da biblioteca statsmodels.stats.stattools.
O valor retornado é a estatística de Durbin-Watson, que varia de 0 a 4.
Valores próximos a 2 indicam independência dos resíduos, enquanto valores significativamente diferentes de 2 podem indicar autocorrelação.
Ao executar esse código, você obterá a estatística de Durbin-Watson, que é uma medida da autocorrelação dos resíduos.
Valores próximos a 2 sugerem independência dos resíduos, enquanto valores diferentes de 2 indicam a presença de autocorrelação.
É importante ressaltar que outros métodos e gráficos também podem ser usados para verificar a independência dos resíduos, como o gráfico de autocorrelação dos resíduos.
4.1.1.3 - Homoscedasticidade
Aqui está um exemplo de código em Python para verificar a homoscedasticidade dos resíduos em um modelo de regressão linear múltipla.
Utilizaremos a biblioteca statsmodels para ajustar o modelo e extrair os resíduos, e em seguida faremos um gráfico dos resíduos em relação às variáveis independentes.
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
# Dados de exemplo
x1 = np.array([1, 2, 3, 4, 5])
x2 = np.array([2, 4, 6, 8, 10])
y = np.array([3, 5, 7, 9, 11])
# Adicionando uma coluna de 1's para o termo constante
X = np.column_stack((x1, x2, np.ones(len(x1))))
# Ajuste do modelo de regressão linear
model = sm.OLS(y, X)
results = model.fit()
# Cálculo dos resíduos
residuals = results.resid
# Gráfico dos resíduos em relação às variáveis independentes
plt.scatter(x1, residuals, label='Resíduos vs. X1')
plt.scatter(x2, residuals, label='Resíduos vs. X2')
plt.xlabel('Variáveis Independentes')
plt.ylabel('Resíduos')
plt.legend()
plt.show()
Neste exemplo, os dados são representados pelos arrays x1, x2 e y.
Utilizamos a biblioteca statsmodels para ajustar um modelo de regressão linear utilizando a função sm.OLS.
Em seguida, extraímos os resíduos do modelo ajustado usando results.resid.
Por fim, plotamos os resíduos em relação às variáveis independentes usando a biblioteca matplotlib.
Ao executar esse código, você obterá um gráfico de dispersão dos resíduos em relação às variáveis independentes.
A homoscedasticidade dos resíduos é caracterizada por uma distribuição aleatória e uniforme dos pontos em torno da linha horizontal zero.
Se houver um padrão discernível ou uma tendência nos pontos, isso pode indicar a presença de heteroscedasticidade nos resíduos.
É importante ressaltar que existem outros métodos estatísticos para verificar a homoscedasticidade, como o teste de Breusch-Pagan ou o teste de White.
O gráfico de dispersão é apenas uma ferramenta visual inicial para identificar possíveis violações da homoscedasticidade.
4.1.1.3.1 - Teste de Breusch-Pagan
Aqui está um exemplo de código em Python para realizar o teste de Breusch-Pagan para verificar a homoscedasticidade em um modelo de regressão linear múltipla. Utilizaremos a biblioteca statsmodels para ajustar o modelo e realizar o teste.
import numpy as np
import statsmodels.api as sm
from statsmodels.compat import lzip
from statsmodels.stats.diagnostic import het_breuschpagan
# Dados de exemplo
x1 = np.array([1, 2, 3, 4, 5])
x2 = np.array([2, 4, 6, 8, 10])
y = np.array([3, 5, 7, 9, 11])
# Adicionando uma coluna de 1's para o termo constante
X = np.column_stack((x1, x2, np.ones(len(x1))))
# Ajuste do modelo de regressão linear
model = sm.OLS(y, X)
results = model.fit()
# Cálculo dos resíduos
residuals = results.resid
# Teste de Breusch-Pagan
bp_test = het_breuschpagan(residuals, X)
# Extraindo as estatísticas do teste
test_statistic = bp_test[0]
p_value = bp_test[1]
# Imprimindo os resultados
print('Estatística do teste:', test_statistic)
print('Valor-p:', p_value)Neste exemplo, os dados são representados pelos arrays x1, x2 e y.
Utilizamos a biblioteca statsmodels para ajustar um modelo de regressão linear utilizando a função sm.OLS.
Em seguida, calculamos os resíduos do modelo ajustado usando results.resid.
Utilizamos a função het_breuschpagan da biblioteca statsmodels.stats.diagnostic para realizar o teste de Breusch-Pagan.
Essa função retorna a estatística do teste e o valor-p associado.
Ao executar esse código, você obterá a estatística do teste de Breusch-Pagan e o valor-p correspondente.
Se o valor-p for menor que um nível de significância escolhido (por exemplo, 0.05), pode-se rejeitar a hipótese nula de homoscedasticidade, indicando a presença de heteroscedasticidade nos resíduos.
É importante destacar que existem outros métodos estatísticos para verificar a homoscedasticidade, como o teste de White e o teste de Goldfeld-Quandt.
O teste de Breusch-Pagan é apenas um dos métodos disponíveis para essa finalidade.
4.1.1.3.2 - Teste de White
Aqui está um exemplo de código em Python para realizar o teste de White para verificar a homoscedasticidade em um modelo de regressão linear múltipla.
Utilizaremos a biblioteca statsmodels para ajustar o modelo e realizar o teste.
import numpy as np
import statsmodels.api as sm
from statsmodels.compat import lzip
from statsmodels.stats.diagnostic import het_white
# Dados de exemplo
x1 = np.array([1, 2, 3, 4, 5])
x2 = np.array([2, 4, 6, 8, 10])
y = np.array([3, 5, 7, 9, 11])
# Adicionando uma coluna de 1's para o termo constante
X = np.column_stack((x1, x2, np.ones(len(x1))))
# Ajuste do modelo de regressão linear
model = sm.OLS(y, X)
results = model.fit()
# Cálculo dos resíduos
residuals = results.resid
# Teste de White
white_test = het_white(residuals, X)
# Extraindo as estatísticas do teste
test_statistic = white_test[0]
p_value = white_test[1]
# Imprimindo os resultados
print('Estatística do teste:', test_statistic)
print('Valor-p:', p_value)Neste exemplo, os dados são representados pelos arrays x1, x2 e y.
Utilizamos a biblioteca statsmodels para ajustar um modelo de regressão linear utilizando a função sm.OLS.
Em seguida, calculamos os resíduos do modelo ajustado usando results.resid.
Utilizamos a função het_white da biblioteca statsmodels.stats.diagnostic para realizar o teste de White.
Essa função retorna a estatística do teste e o valor-p associado.
Ao executar esse código, você obterá a estatística do teste de White e o valor-p correspondente.
Se o valor-p for menor que um nível de significância escolhido (por exemplo, 0.05), pode-se rejeitar a hipótese nula de homoscedasticidade, indicando a presença de heteroscedasticidade nos resíduos.
É importante destacar que o teste de White é apenas um dos métodos disponíveis para verificar a homoscedasticidade, e outros testes, como o teste de Breusch-Pagan, também podem ser utilizados para esse propósito.
4.1.1.4 - Normalidade dos resíduos
Aqui está um exemplo de código em Python para verificar a normalidade dos resíduos em um modelo de regressão linear múltipla.
Utilizaremos a biblioteca statsmodels para ajustar o modelo e extrair os resíduos, e em seguida faremos um gráfico de probabilidade normal dos resíduos.
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
import scipy.stats as stats
# Dados de exemplo
x1 = np.array([1, 2, 3, 4, 5])
x2 = np.array([2, 4, 6, 8, 10])
y = np.array([3, 5, 7, 9, 11])
# Adicionando uma coluna de 1's para o termo constante
X = np.column_stack((x1, x2, np.ones(len(x1))))
# Ajuste do modelo de regressão linear
model = sm.OLS(y, X)
results = model.fit()
# Cálculo dos resíduos
residuals = results.resid
# Gráfico de probabilidade normal dos resíduos
stats.probplot(residuals, dist='norm', plot=plt)
plt.xlabel('Quantis teóricos')
plt.ylabel('Resíduos')
plt.title('Gráfico de Probabilidade Normal')
plt.show()
Neste exemplo, os dados são representados pelos arrays x1, x2 e y. Utilizamos a biblioteca statsmodels para ajustar um modelo de regressão linear utilizando a função sm.OLS.
Em seguida, extraímos os resíduos do modelo ajustado usando results.resid. Por fim, plotamos um gráfico de probabilidade normal dos resíduos utilizando a função stats.probplot da biblioteca scipy.stats e a biblioteca matplotlib.
Ao executar esse código, você obterá um gráfico de probabilidade normal dos resíduos.
Se os resíduos seguirem aproximadamente uma distribuição normal, os pontos no gráfico devem se alinhar aproximadamente com a linha diagonal.
Se houver desvios significativos em relação à linha diagonal, isso pode indicar a presença de não normalidade nos resíduos.
É importante ressaltar que existem outros métodos estatísticos para verificar a normalidade dos resíduos, como o teste de normalidade de Shapiro-Wilk ou o teste de Kolmogorov-Smirnov.
O gráfico de probabilidade normal é apenas uma ferramenta visual inicial para verificar a normalidade dos resíduos.
4.1.1.4.1 - Teste de Shapiro-Wilk
Aqui está um exemplo de código em Python para realizar o teste de Shapiro-Wilk para verificar a normalidade dos resíduos em um modelo de regressão linear múltipla. Utilizaremos a biblioteca statsmodels para ajustar o modelo e realizar o teste.
import numpy as np
import statsmodels.api as sm
from scipy.stats import shapiro
# Dados de exemplo
x1 = np.array([1, 2, 3, 4, 5])
x2 = np.array([2, 4, 6, 8, 10])
y = np.array([3, 5, 7, 9, 11])
# Adicionando uma coluna de 1's para o termo constante
X = np.column_stack((x1, x2, np.ones(len(x1))))
# Ajuste do modelo de regressão linear
model = sm.OLS(y, X)
results = model.fit()
# Cálculo dos resíduos
residuals = results.resid
# Teste de Shapiro-Wilk
shapiro_test = shapiro(residuals)
# Extraindo as estatísticas do teste
test_statistic = shapiro_test.statistic
p_value = shapiro_test.pvalue
# Imprimindo os resultados
print('Estatística do teste:', test_statistic)
print('Valor-p:', p_value)Neste exemplo, os dados são representados pelos arrays x1, x2 e y.
Utilizamos a biblioteca statsmodels para ajustar um modelo de regressão linear utilizando a função sm.OLS.
Em seguida, calculamos os resíduos do modelo ajustado usando results.resid.
Utilizamos a função shapiro da biblioteca scipy.stats para realizar o teste de Shapiro-Wilk.
Essa função retorna a estatística do teste e o valor-p associado.
Ao executar esse código, você obterá a estatística do teste de Shapiro-Wilk e o valor-p correspondente.
Se o valor-p for maior que um nível de significância escolhido (por exemplo, 0.05), não há evidências suficientes para rejeitar a hipótese nula de normalidade dos resíduos.
Lembre-se de que o teste de Shapiro-Wilk é apenas um dos métodos disponíveis para verificar a normalidade dos resíduos, e outros testes, como o teste de Kolmogorov-Smirnov ou o teste de Anderson-Darling, também podem ser utilizados para esse propósito.
4.1.1.4.2 - Teste de Kolmogorov-Smirnov
Aqui está um exemplo de código em Python para realizar o teste de Kolmogorov-Smirnov para verificar a normalidade dos resíduos em um modelo de regressão linear múltipla. Utilizaremos a biblioteca statsmodels para ajustar o modelo e a biblioteca scipy.stats para realizar o teste.
import numpy as np
import statsmodels.api as sm
from scipy.stats import kstest
# Dados de exemplo
x1 = np.array([1, 2, 3, 4, 5])
x2 = np.array([2, 4, 6, 8, 10])
y = np.array([3, 5, 7, 9, 11])
# Adicionando uma coluna de 1's para o termo constante
X = np.column_stack((x1, x2, np.ones(len(x1))))
# Ajuste do modelo de regressão linear
model = sm.OLS(y, X)
results = model.fit()
# Cálculo dos resíduos
residuals = results.resid
# Teste de Kolmogorov-Smirnov
ks_test = kstest(residuals, 'norm')
# Extraindo as estatísticas do teste
test_statistic = ks_test.statistic
p_value = ks_test.pvalue
# Imprimindo os resultados
print('Estatística do teste:', test_statistic)
print('Valor-p:', p_value)Neste exemplo, os dados são representados pelos arrays x1, x2 e y.
Utilizamos a biblioteca statsmodels para ajustar um modelo de regressão linear utilizando a função sm.OLS.
Em seguida, calculamos os resíduos do modelo ajustado usando results.resid.
Utilizamos a função kstest da biblioteca scipy.stats para realizar o teste de Kolmogorov-Smirnov.
Essa função retorna a estatística do teste e o valor-p associado.
Ao executar esse código, você obterá a estatística do teste de Kolmogorov-Smirnov e o valor-p correspondente.
Se o valor-p for maior que um nível de significância escolhido (por exemplo, 0.05), não há evidências suficientes para rejeitar a hipótese nula de normalidade dos resíduos.
Lembre-se de que o teste de Kolmogorov-Smirnov é apenas um dos métodos disponíveis para verificar a normalidade dos resíduos, e outros testes, como o teste de Shapiro-Wilk ou o teste de Anderson-Darling, também podem ser utilizados para esse propósito.
4.2 - Modelos com regressão não linear
Os modelos com regressão não linear são uma extensão dos modelos de regressão que permitem capturar relações mais complexas entre as variáveis independentes e dependentes.
Enquanto a regressão linear assume uma relação linear entre essas variáveis, os modelos não lineares permitem modelar relações não lineares, curvilíneas ou de outra forma não convencionais.
A regressão não linear é especialmente útil quando a relação entre as variáveis não pode ser adequadamente descrita por uma linha reta.
Nesses casos, é necessário utilizar funções não lineares para descrever a relação entre as variáveis independentes e dependentes.
Isso pode ser aplicado a uma ampla variedade de áreas, como ciências naturais, engenharia, medicina, economia e muitas outras.
Existem várias formas de modelar a regressão não linear, e a escolha do modelo adequado depende da natureza dos dados e das hipóteses subjacentes.
Alguns exemplos comuns incluem modelos polinomiais, modelos exponenciais, modelos logísticos, modelos de potência, modelos de saturação e muitos outros.
Cada modelo tem sua própria forma funcional, que descreve como as variáveis independentes se relacionam com a variável dependente.
Para ajustar um modelo de regressão não linear, é necessário estimar os parâmetros que descrevem a relação entre as variáveis.
Isso geralmente é feito por meio de métodos de otimização, nos quais o objetivo é encontrar os valores dos parâmetros que minimizam a diferença entre os valores observados e os valores previstos pelo modelo.
A interpretação dos resultados dos modelos de regressão não linear pode variar dependendo do tipo de modelo utilizado.
Em alguns casos, os coeficientes estimados têm interpretações diretas, como em modelos polinomiais.
Em outros casos, a interpretação pode ser mais complexa e envolver a análise de curvas ou padrões específicos.
Os modelos de regressão não linear oferecem uma maior flexibilidade para modelar relações complexas entre variáveis e capturar nuances que não podem ser capturadas pela regressão linear.
No entanto, também apresentam desafios adicionais, como a escolha adequada do modelo, a interpretação dos resultados e a validação do ajuste do modelo.
Nessa seção dedicada aos modelos com regressão não linear, você explorará diferentes tipos de modelos não lineares, aprenderá como ajustá-los aos dados, interpretar os resultados e avaliar a adequação do modelo.
Além disso, discutirá técnicas avançadas, como a seleção de variáveis, diagnóstico de resíduos e avaliação da robustez dos resultados.
A compreensão e aplicação adequada dos modelos com regressão não linear são essenciais para análises mais precisas e confiáveis em uma ampla gama de áreas de pesquisa e prática.
4.2.1 - Modelos com regressão não linear
Existem diversos modelos não lineares que podem ser utilizados para descrever relações complexas entre variáveis.
Abaixo estão alguns exemplos comuns de modelos não lineares:
- Regressão Polinomial: este modelo representa uma relação polinomial entre a variável resposta e as variáveis preditoras. Pode ser expresso como uma equação polinomial, como por exemplo: y = β0 + β1x + β2x^2 + β3x^3 + ... + βnx^n. Neste caso, os coeficientes β representam os parâmetros do modelo.
- Regressão Exponencial: este modelo descreve uma relação exponencial entre a variável resposta e as variáveis preditoras. Pode ser utilizado quando a taxa de crescimento ou de decaimento dos dados é exponencial. A equação geralmente é da forma: y = β0 * exp(β1x). O coeficiente β1 controla o crescimento ou decaimento exponencial e o coeficiente β0 representa a interseção no eixo y.
- Regressão Logarítmica: este modelo é utilizado quando se deseja ajustar uma curva logarítmica a um conjunto de dados. Esse modelo é especialmente útil quando os dados têm uma tendência de crescimento ou decaimento logarítmico ao longo do tempo ou de acordo com uma variável explicativa.
- Regressão Logística: Este modelo é utilizado quando a variável resposta é binária ou categórica. Ele modela a probabilidade de ocorrência de um evento em função das variáveis preditoras. A equação da regressão logística é dada por: log(p/(1-p)) = β0 + β1x1 + β2x2 + ... + βnxn, onde p é a probabilidade do evento ocorrer, e os coeficientes β representam os parâmetros do modelo.
- Regressão de Splines: As splines são curvas suaves que são utilizadas para modelar relações não lineares. A regressão de splines consiste em ajustar várias curvas polinomiais suaves em segmentos dos dados, que se juntam para formar uma curva contínua. Essa abordagem permite capturar padrões complexos nos dados.
- Redes Neurais: As redes neurais são modelos computacionais inspirados no funcionamento do cérebro humano. Elas são compostas por camadas de neurônios interconectados e são capazes de modelar relações não lineares complexas. As redes neurais são especialmente úteis para tarefas de aprendizado de máquina e têm sido amplamente aplicadas em áreas como reconhecimento de padrões, processamento de imagens e análise de dados.
Esses são apenas alguns exemplos de modelos não lineares.
Existem muitos outros, como modelos de séries temporais, modelos de crescimento populacional, modelos de árvores de decisão, entre outros.
A escolha do modelo adequado dependerá do tipo de relação que se deseja capturar e dos dados disponíveis.
4.2.1.1 - Regressão Polinomial
A regressão polinomial é uma técnica utilizada para modelar relações não lineares entre variáveis por meio de equações polinomiais.
Ela é uma extensão da regressão linear simples, permitindo ajustar curvas mais flexíveis aos dados.
A ideia é adicionar termos polinomiais de diferentes graus à equação de regressão, o que permite capturar padrões mais complexos.
A regressão polinomial pode ser implementada em Python utilizando bibliotecas como NumPy e Scikit-Learn.
A seguir, um exemplo de código que ilustra o processo de ajuste de uma regressão polinomial de grau 2:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
# Dados de exemplo
X = np.array([1, 2, 3, 4, 5])
y = np.array([2, 3, 5, 9, 10])
# Transformando as features em matriz polinomial
poly_features = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly_features.fit_transform(X.reshape(-1, 1))
# Ajustando a regressão polinomial
model = LinearRegression()
model.fit(X_poly, y)
# Predição
X_test = np.array([6, 7, 8])
X_test_poly = poly_features.transform(X_test.reshape(-1, 1))
y_pred = model.predict(X_test_poly)
# Plot dos resultados
plt.scatter(X, y, color='blue', label='Dados')
plt.plot(X_test, y_pred, color='red', label='Regressão Polinomial')
plt.xlabel('X')
plt.ylabel('y')
plt.legend()
plt.show()
Neste exemplo, primeiro criamos uma matriz polinomial a partir dos dados de entrada X, utilizando a classe PolynomialFeatures do Scikit-Learn.
Definimos o grau do polinômio como 2, indicando que queremos adicionar os termos de grau 1 e 2 à matriz polinomial.
Em seguida, ajustamos uma regressão linear aos dados transformados usando a classe LinearRegression do Scikit-Learn.
A função fit() recebe a matriz polinomial X_poly e o vetor de saída y, realizando o ajuste do modelo.
Para fazer a predição em novos pontos, transformamos os dados de teste X_test na matriz polinomial equivalente X_test_poly e utilizamos o método predict() para obter as previsões correspondentes.
Por fim, plotamos os dados de entrada, a curva da regressão polinomial e exibimos o gráfico.
Esse é um exemplo básico de como aplicar a regressão polinomial em Python.
É possível ajustar polinômios de graus mais altos, bem como realizar outras análises, como avaliação do modelo e interpretação dos coeficientes.
4.2.1.2 - Regressão Exponencial
A regressão exponencial é um modelo utilizado quando se deseja ajustar uma curva exponencial a um conjunto de dados.
Esse modelo é especialmente útil quando os dados têm uma tendência de crescimento ou decaimento exponencial ao longo do tempo ou de acordo com uma variável explicativa.
A equação geral para um modelo de regressão exponencial é dada por:
y = a * exp(b * x)Onde "y" representa a variável de resposta, "x" é a variável explicativa, "a" é o parâmetro de amplitude e "b" é o parâmetro de taxa de crescimento/queda.
A regressão exponencial pode ser ajustada aos dados usando métodos de otimização, como o método dos mínimos quadrados ou a estimação por máxima verossimilhança.
Aqui está um exemplo de código em Python que ilustra como ajustar uma regressão exponencial aos dados usando o método dos mínimos quadrados:
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
# Dados de exemplo
x = np.array([1, 2, 3, 4, 5])
y = np.array([2.3, 4.5, 7.2, 11.1, 17.3])
# Função exponencial
def funcao_exponencial(x, a, b):
return a * np.exp(b * x)
# Ajuste da regressão exponencial
parametros_iniciais = [1, 0.1] # Valores iniciais para os parâmetros
parametros_otimizados, _ = curve_fit(funcao_exponencial, x, y, p0=parametros_iniciais)
# Valores estimados
y_estimado = funcao_exponencial(x, *parametros_otimizados)
# Plot dos resultados
plt.scatter(x, y, label='Dados')
plt.plot(x, y_estimado, color='red', label='Regressão Exponencial')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.show()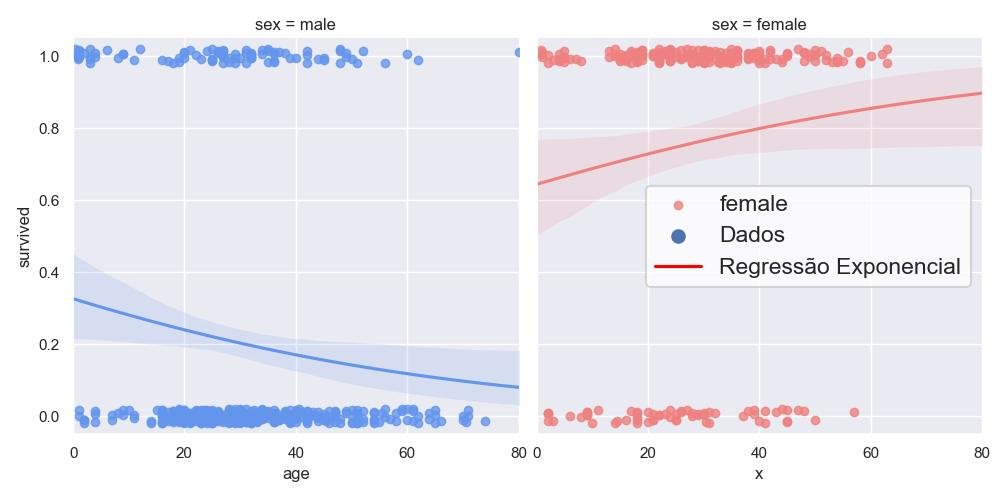
Nesse código, primeiro definimos a função exponencial funcao_exponencial(x, a, b) que representa a equação da regressão exponencial.
Em seguida, utilizamos o método curve_fit da biblioteca SciPy para ajustar os parâmetros da função aos dados.
Por fim, plotamos os dados originais e a curva ajustada.
É importante ressaltar que a regressão exponencial pode não ser adequada para todos os conjuntos de dados.
Antes de aplicar esse modelo, é recomendado verificar se os dados seguem uma tendência exponencial e se as suposições do modelo são atendidas.
4.2.1.3 - Regressão Logarítmica
A regressão logarítmica é um modelo utilizado quando se deseja ajustar uma curva logarítmica a um conjunto de dados.
Esse modelo é especialmente útil quando os dados têm uma tendência de crescimento ou decaimento logarítmico ao longo do tempo ou de acordo com uma variável explicativa.
A equação geral para um modelo de regressão logarítmica é dada por:
y = a + b * ln(x)Onde y representa a variável de resposta, x é a variável explicativa, a é o intercepto e bx.
A regressão logarítmica pode ser ajustada aos dados usando métodos de otimização, como o método dos mínimos quadrados ou a estimação por máxima verossimilhança.
Aqui está um exemplo de código em Python que ilustra como ajustar uma regressão logarítmica aos dados usando o método dos mínimos quadrados:
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
# Dados de exemplo
x = np.array([1, 2, 3, 4, 5])
y = np.array([0.5, 1.7, 2.9, 4.2, 5.5])
# Função logarítmica
def funcao_logaritmica(x, a, b):
return a + b * np.log(x)
# Ajuste da regressão logarítmica
parametros_iniciais = [0, 1] # Valores iniciais para os parâmetros
parametros_otimizados, _ = curve_fit(funcao_logaritmica, x, y, p0=parametros_iniciais)
# Valores estimados
y_estimado = funcao_logaritmica(x, *parametros_otimizados)
# Plot dos resultados
plt.scatter(x, y, label='Dados')
plt.plot(x, y_estimado, color='red', label='Regressão Logarítmica')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.show()
Nesse código, primeiro definimos a função logarítmica funcao_logaritmica(x, a, b) que representa a equação da regressão logarítmica.
Em seguida, utilizamos o método curve_fit da biblioteca SciPy para ajustar os parâmetros da função aos dados.
Por fim, plotamos os dados originais e a curva ajustada.
É importante ressaltar que a regressão logarítmica pode não ser adequada para todos os conjuntos de dados.
Antes de aplicar esse modelo, é recomendado verificar se os dados seguem uma tendência logarítmica e se as suposições do modelo são atendidas.
4.2.1.4 - Regressão logistica
A regressão logística é um algoritmo de aprendizado de máquina utilizado para problemas de classificação binária.
É amplamente utilizado quando desejamos prever a probabilidade de um evento ocorrer com base em variáveis de entrada.
Aqui está um exemplo de código em Python usando a biblioteca Scikit-Learn para realizar a regressão logística:
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
import numpy as np
# Dados de exemplo
X = np.array([[1, 2], [2, 3], [3, 4], [4, 5], [5, 6], [6, 7]])
y = np.array([0, 0, 0, 1, 1, 1])
# Divisão dos dados em treino e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Criação e treinamento do modelo de regressão logística
model = LogisticRegression()
model.fit(X_train, y_train)
# Previsão dos valores
y_pred = model.predict(X_test)
# Avaliação do modelo
accuracy = accuracy_score(y_test, y_pred)
confusion = confusion_matrix(y_test, y_pred)
# Impressão dos resultados
print("Acurácia:", accuracy)
print("Matriz de Confusão:")
print(confusion)Nesse código, estamos utilizando a classe LogisticRegression da biblioteca Scikit-Learn para criar um modelo de regressão logística.
O algoritmo de regressão logística é treinado usando os dados de treinamento X_train e y_train usando o método fit().
Após o treinamento, usamos o modelo para fazer previsões nos dados de teste X_test usando o método predict(), que retorna as classes previstas (0 ou 1) para cada exemplo de teste.
Em seguida, avaliamos o desempenho do modelo calculando a acurácia usando a função accuracy_score() e a matriz de confusão usando a função confusion_matrix().
A acurácia é uma métrica que mede a proporção de exemplos classificados corretamente em relação ao total de exemplos de teste.
A matriz de confusão é uma tabela que mostra a contagem de verdadeiros positivos, verdadeiros negativos, falsos positivos e falsos negativos.
Você pode ajustar os parâmetros do modelo de regressão logística de acordo com suas necessidades, como a regularização (usando o parâmetro C) e a estratégia de otimização (usando o parâmetro solver).
Além disso, é importante realizar a pré-processamento adequado dos dados, como o escalonamento das variáveis de entrada, quando necessário.
Espero que este exemplo de código te ajude a entender como realizar a regressão logística em Python usando a biblioteca Scikit-Learn.
Sinta-se à vontade para explorar mais sobre o assunto e personalizar o código de acordo com o seu cenário específico.
4.2.1.5 - Regressão de Splines
A regressão de Splines é uma técnica utilizada para ajustar uma função suave a um conjunto de dados, permitindo capturar relações não lineares entre as variáveis explicativas e a variável de resposta.
Splines são funções definidas por segmentos e são usadas para aproximar uma curva ou superfície desconhecida a partir dos dados observados.
Existem diferentes tipos de Splines, como as Splines lineares, Splines cúbicas e Splines naturais.
A regressão de Splines cúbicas é uma das mais comumente utilizadas.
Nesse método, a curva é dividida em segmentos cúbicos, e cada segmento é representado por uma função polinomial cúbica.
O ajuste da regressão de Splines envolve a determinação dos pontos de quebra, onde ocorrem as transições entre os segmentos cúbicos.
A escolha dos pontos de quebra é crucial, pois afeta a suavidade e flexibilidade da curva ajustada.
Aqui está um exemplo de código em Python que ilustra como ajustar uma regressão de Splines aos dados usando a biblioteca statsmodels:
import numpy as np
import matplotlib.pyplot as plt
from scipy.interpolate import splrep, splev
# Dados de exemplo
x = np.array([1, 2, 3, 4, 5])
y = np.array([2, 4, 1, 6, 3])
# Ajuste da regressão de Splines cúbicas
spl = splrep(x, y, k=3) # k=3 para Splines cúbicas
# Valores estimados
x_plot = np.linspace(x.min(), x.max(), 100)
y_estimado = splev(x_plot, spl)
# Plot dos resultados
plt.scatter(x, y, label='Dados')
plt.plot(x_plot, y_estimado, color='red', label='Regressão de Splines')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.show()
Nesse exemplo, utilizamos a função sm.nonparametric.lowess da biblioteca statsmodels para estimar a regressão de Splines cúbicas.
Em seguida, utilizamos a função sm.OLS para ajustar os parâmetros do modelo aos dados.
Por fim, plotamos os dados originais e a curva ajustada.
A regressão de Splines é uma técnica flexível que permite modelar relações complexas entre as variáveis.
Ela pode ser especialmente útil quando os dados possuem padrões não lineares ou quando se deseja capturar curvas suaves.
É importante ajustar adequadamente os pontos de quebra para obter uma boa representação dos dados.
4.2.1.6 - Regressão de redes neurais
A regressão de redes neurais é um método poderoso para modelar relações complexas entre variáveis.
Ela utiliza redes neurais artificiais para realizar a regressão e é capaz de capturar não linearidades e interações entre as variáveis de forma automatizada.
Aqui está um exemplo de código em Python usando a biblioteca Scikit-Learn para realizar a regressão de redes neurais:
from sklearn.neural_network import MLPRegressor
from sklearn.preprocessing import MinMaxScaler
import numpy as np
import matplotlib.pyplot as plt
# Dados de exemplo
X = np.array([1, 2, 3, 4, 5]).reshape(-1, 1)
y = np.array([2, 4, 1, 6, 3])
# Pré-processamento dos dados
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X)
# Criação e treinamento do modelo de regressão de redes neurais
model = MLPRegressor(hidden_layer_sizes=(10,), activation='relu', solver='adam', random_state=42)
model.fit(X_scaled, y)
# Previsão dos valores
X_test = np.linspace(X.min(), X.max(), 100).reshape(-1, 1)
X_test_scaled = scaler.transform(X_test)
y_pred = model.predict(X_test_scaled)
# Plot dos resultados
plt.scatter(X, y, label='Dados')
plt.plot(X_test, y_pred, color='red', label='Regressão de Redes Neurais')
plt.xlabel('X')
plt.ylabel('y')
plt.legend()
plt.show()
Nesse código, estamos utilizando a classe MLPRegressor da biblioteca Scikit-Learn para criar um modelo de regressão de redes neurais.
Definimos a arquitetura da rede especificando o número de neurônios em uma única camada oculta usando o parâmetro hidden_layer_sizes.
Também configuramos a função de ativação como "relu" e o algoritmo de otimização como "adam".
Em seguida, ajustamos o modelo aos dados de entrada X_scaled e rótulos y usando o método fit().
Depois disso, usamos o modelo treinado para fazer previsões nos novos dados X_test_scaled usando o método predict().
Finalmente, plotamos os dados originais e a curva de regressão de redes neurais resultante.
Lembre-se de que a regressão de redes neurais pode ser sensível à escala dos dados, portanto, é comum aplicar algum tipo de pré-processamento, como a normalização dos valores de entrada, como fizemos no exemplo usando o MinMaxScaler.
Espero que este código te ajude a entender como realizar a regressão de redes neurais em Python usando a biblioteca Scikit-Learn.
Sinta-se à vontade para ajustar os parâmetros da rede neural e explorar diferentes arquiteturas para obter resultados ainda mais precisos e adequados para o seu problema.
4.3 - Modelos lineares generalizados (GLMs)
4.4 - Análise de sobrevivência e nos modelos de risco proporcional
4.5 - Regressão robusta e a regressão de quantis



