

3 - Python para Aprendizado de Máquina
Adentrar o mundo do Python avançado é como abrir uma porta para um reino de possibilidades infinitas na busca por excelência em Aprendizado de Máquina (ML - Machine Learning).
Nesse emocionante território, o conhecimento básico é apenas a chave que abre a entrada, e o que você encontra lá dentro é uma sinfonia de poderosos conceitos, técnicas e ferramentas que elevam o ML a uma arte de vanguarda.
Aqui, não nos contentamos com fórmulas prontas. Avançar é questionar, desafiar e remodelar. É entender que, embora a regressão e a classificação sejam os primeiros acordes, os verdadeiros solos estão nos modelos profundos e complexos que moldam o futuro. Com bibliotecas como TensorFlow e PyTorch, nós esculpimos redes neurais e camadas profundas capazes de entender os dados mais intricados e fazer previsões precisas que eram inimagináveis há apenas alguns anos.
Mas não se engane: Python avançado é como um quebra-cabeças, e o ML é a peça mais brilhante e complexa desse quebra-cabeças. Aqui, não nos limitamos a um único tipo de algoritmo. Em vez disso, dançamos com árvores de decisão e florestas aleatórias, exploramos o mundo misterioso das máquinas de vetor de suporte e deciframos os segredos ocultos nas redes Bayesianas.
É claro, nessa jornada, a transformação dos dados é uma arte em si mesma. Usamos as mãos habilidosas da normalização e padronização para criar harmonia nos nossos conjuntos de dados. Com a elegância do PolynomialFeatures, polimos nossas características até que brilhem com insights ocultos, enquanto as técnicas de redução de dimensionalidade, como o PCA, transformam o excesso de informações em uma sinfonia de insights claros e concisos.
Quando exploramos as profundezas, a validação cruzada não é apenas um conceito, mas uma prática sagrada. Dividimos nossos dados, treinamos e testamos, garantindo que nosso modelo não apenas cante bem em um palco, mas que também mantenha a harmonia em todo o concerto.
E enquanto nos deleitamos com os resultados, a ética nos lembra de que a tecnologia avançada traz responsabilidade. Abraçamos a ética de ponta a ponta, questionando os vieses, considerando os impactos e nos esforçando para tornar nossa busca pelo conhecimento uma contribuição positiva para a sociedade.
Python avançado com ML é uma jornada, e o trajeto é iluminado pelo brilho da inovação. À medida que desvendamos o enigma das redes neurais convolucionais, sentimentos profundos de realização e curiosidade nos impulsionam adiante.
Portanto, avance sem medo, pois aqui, a vanguarda tecnológica é sua aliada. Seja a magia dos algoritmos de otimização ou a maravilha das redes generativas adversárias, o futuro se desdobra diante de nós em um ritmo acelerado. Então, pegue o código, abrace o conhecimento e desafie os limites do que é possível em Python avançado com ML.
O ML em Python é alimentada por um ecossistema robusto de bibliotecas e ferramentas que oferecem uma ampla gama de algoritmos, técnicas e recursos para treinar, avaliar e implantar modelos.
Vamos explorar os detalhes técnicos desse ecossistema:
- Bibliotecas Principais: O Python oferece várias bibliotecas líderes em ML, amplamente utilizadas por cientistas de dados e engenheiros de machine learning em todo o mundo, formando o núcleo do ecossistema de ML em Python, e oferecendo as ferramentas necessárias para você desenvolver, treinar e avaliar modelos de ML com eficácia e eficiência.
- Scikit-Learn: O Scikit-Learn é uma biblioteca amplamente usada para ML clássico. Ela oferece uma ampla variedade de algoritmos para tarefas como regressão, classificação, agrupamento e seleção de modelos. Além disso, fornece ferramentas para pré-processamento de dados e avaliação de modelos, tornando-a essencial para projetos de ML.
- TensorFlow: TensorFlow é uma biblioteca de ML de código aberto desenvolvida pelo Google. É especialmente poderosa para treinar redes neurais profundas e implementar modelos de aprendizado profundo. Sua flexibilidade e suporte à computação em GPUs o tornam uma escolha popular para projetos de aprendizado profundo.
- Keras: Keras é uma API de alto nível que roda em cima de bibliotecas de ML, como o TensorFlow. Ela simplifica a criação de redes neurais artificiais, permitindo que você desenvolva modelos complexos com menos código. Keras é conhecida por sua usabilidade e é ótima para iniciantes e desenvolvedores avançados.
- PyTorch: PyTorch é outra biblioteca de ML voltada para aprendizado profundo. É elogiada por sua flexibilidade e facilidade de depuração. PyTorch adota uma abordagem mais dinâmica para a construção de modelos, tornando-o uma escolha popular entre pesquisadores e desenvolvedores.
- XGBoost: XGBoost é uma biblioteca dedicada ao algoritmo de gradient boosting. Essa técnica avançada melhora a precisão do modelo ao combinar muitos modelos de aprendizado fracos. XGBoost é conhecido por sua eficácia em competições de ciência de dados e é amplamente usado para problemas de regressão e classificação.
- LightGBM: LightGBM é outra biblioteca focada em gradient boosting. Ele se destaca por sua eficiência e velocidade, sendo uma escolha sólida para conjuntos de dados grandes. LightGBM é especialmente útil quando você precisa de resultados rápidos e de alta qualidade.
- Pandas: Pandas é uma biblioteca fundamental para manipulação e análise de dados. É frequentemente usada para carregar, limpar, transformar e explorar dados antes de treinar modelos de ML. As estruturas de dados do Pandas, como o DataFrame, tornam a manipulação de dados mais eficiente e intuitiva.
- NumPy: O NumPy é uma biblioteca fundamental para computação científica em Python. Ele fornece suporte para arrays multidimensionais e funções matemáticas que são essenciais para manipulação de dados numéricos. O NumPy é amplamente utilizado para realizar operações eficientes em dados numéricos, o que é essencial em projetos de ML.
- Matplotlib: Matplotlib é uma biblioteca de visualização de dados em Python. Ela permite criar gráficos estáticos, gráficos de dispersão, histogramas e muitos outros tipos de visualizações. Essas visualizações são úteis para entender seus dados, avaliar modelos e comunicar resultados de forma eficaz.
- Pré-processamento de Dados: Antes de treinar modelos, os dados geralmente precisam ser limpos e transformados. Isso pode envolver preenchimento de valores ausentes, normalização, codificação de variáveis categóricas e muito mais. As bibliotecas como Scikit-Learn e Pandas oferecem ferramentas para essas tarefas.
- Escolha do Modelo: A escolha do modelo depende do problema que você está resolvendo. Para problemas de classificação, você pode optar por algoritmos como regressão logística, máquinas de vetor de suporte ou árvores de decisão. Para problemas de regressão, regressão linear e algoritmos de árvore são comuns. Além disso, algoritmos de aprendizado profundo (redes neurais) são ideais para problemas complexos de visão computacional, processamento de linguagem natural e muito mais.
- Treinamento e Avaliação: Para treinar um modelo, você divide seus dados em conjuntos de treinamento e teste. O modelo é treinado usando os dados de treinamento e, em seguida, avaliado nos dados de teste para medir sua performance. Métricas como precisão, recall, F1-score, erro médio quadrado, entre outras, são usadas para avaliar a eficácia do modelo.
- Ajuste de Hiperparâmetros: Cada algoritmo possui hiperparâmetros que precisam ser ajustados para obter o melhor desempenho. Isso pode ser feito por tentativa e erro, ou com técnicas como busca em grade ou busca aleatória.
- Validação Cruzada: A validação cruzada é usada para estimar o desempenho do modelo em dados não vistos. Ela envolve dividir os dados em várias partes (dobras) e treinar/avaliar o modelo em diferentes combinações de dobras.
- Regularização: Para evitar o sobreajuste (overfitting, quando o modelo se adapta demais aos dados de treinamento), a regularização é usada. Ela penaliza modelos mais complexos, incentivando a simplicidade.
- Visualização de Dados e Modelos: Bibliotecas como Matplotlib, Seaborn e TensorBoard permitem visualizar dados, métricas de desempenho e até mesmo a estrutura das redes neurais.
- Implantação de Modelos: Uma vez que você treinou um modelo, você pode implantá-lo para fazer previsões em novos dados. Isso pode ser feito usando bibliotecas como DJango, Flask, FastAPI, ou até mesmo plataformas de nuvem como AWS, Azure e Google Cloud.
- Aprendizado Contínuo: O ML é um campo em constante evolução. Manter-se atualizado com novas técnicas, algoritmos e melhores práticas é fundamental para obter o melhor desempenho dos seus modelos.
Lembre-se, o ML é tanto uma arte quanto uma ciência. Explorar e experimentar são partes essenciais do processo. Com o Python avançado como seu aliado, você tem as ferramentas para desvendar os padrões ocultos nos dados e transformá-los em conhecimento e insights valiosos.
3.1 - Scikit-Learn
O Scikit-Learn é uma das bibliotecas mais populares para aprendizado de máquina em Python, oferece uma ampla gama de algoritmos e ferramentas para realizar tarefas de aprendizado de máquina, desde pré-processamento de dados até avaliação de modelos.
Vamos detalhar algumas das principais funcionalidades do Scikit-Learn:
- Pré-processamento: O Scikit-Learn oferece funções para lidar com tarefas de pré-processamento, como lidar com valores ausentes (Imputer), normalização (StandardScaler), codificação de variáveis categóricas (OneHotEncoder), entre outras.
- Seleção de Modelos Supervisionado e Não Supervisionado: O Scikit-Learn suporta algoritmos de aprendizado supervisionado (classificação, regressão) e não supervisionado (agrupamento, redução de dimensionalidade).
- Algoritmos Diversificados: Ele oferece uma variedade de algoritmos, incluindo regressão linear, regressão logística, máquinas de vetor de suporte (SVM), árvores de decisão, k-means, PCA, entre outros.
- Treinamento e Avaliação de Modelos:
- Interface Uniforme: Todos os algoritmos de aprendizado de máquina no Scikit-Learn seguem uma interface uniforme. Você pode usar os métodos .fit() para treinar modelos e .predict() para fazer previsões.
- Métricas de Avaliação: A biblioteca oferece uma variedade de métricas de avaliação, como precisão, recall, F1-score, erro médio quadrado, coeficiente de determinação (R²) e muitos outros.
- Validação Cruzada: O Scikit-Learn oferece funções para realizar validação cruzada, como cross_val_score(), que ajuda a avaliar o desempenho do modelo em diferentes conjuntos de treinamento/teste.
- Seleção de Hiperparâmetros com Busca em Grade: O Scikit-Learn oferece ferramentas para realizar uma busca em grade, onde você pode especificar um conjunto de hiperparâmetros e ele tentará todas as combinações possíveis para encontrar a melhor configuração.
- Pipeline de Modelagem: O Scikit-Learn permite criar pipelines de modelagem, onde você pode encadear várias etapas, como pré-processamento, seleção de modelos e avaliação, tornando o processo mais eficiente e organizado.
- Manipulação de Dados: Você pode usar o Scikit-Learn para dividir seus dados em conjuntos de treinamento e teste, bem como para dividir conjuntos de dados em lotes menores para treinamento incremental.
- Visualização: Embora o foco principal do Scikit-Learn não seja a visualização, ele oferece algumas ferramentas básicas para visualizar os resultados dos modelos.
- Integração com Outras Bibliotecas: O Scikit-Learn é facilmente integrado com outras bibliotecas populares como NumPy e Pandas, permitindo uma manipulação eficaz de dados.
- Documentação Rica e Detalhada: A documentação oficial do Scikit-Learn é extensa, incluindo guias, tutoriais e exemplos detalhados.
- Comunidade Ativa: O projeto é de código aberto e tem uma comunidade ativa, o que significa que você pode encontrar suporte e recursos online facilmente.
O Scikit-Learn é uma ferramenta poderosa para explorar e experimentar com algoritmos de aprendizado de máquina. Sua interface consistente e ampla gama de funcionalidades tornam-no uma escolha popular para iniciantes e especialistas em aprendizado de máquina.
3.1.1 - Preparação de dados
3.1.2 - Seleção de modelos
3.1.3 - Treinamento e avaliação de modelos
3.1.4 - Hiperparâmetros
3.1.5 - Pipeline de Modelagem
3.1.6 - Manipulação de Dados
3.1.7 - Visualização
Aqui está um exemplo de código usando o Scikit-Learn para treinar um modelo de regressão linear e, em seguida, visualizar os resultados:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Gerar dados de exemplo
np.random.seed(0)
dados_aleatorios = np.random.rand(100, 1) * 10
alvos_aleatorios = 2 * dados_aleatorios + 1 + np.random.randn(100, 1)
# Dividir os dados em conjunto de treinamento e teste
dados_treino, dados_teste, alvos_treino, alvos_teste = train_test_split(
dados_aleatorios, alvos_aleatorios, test_size=0.2, random_state=0)
# Treinar o modelo de regressão linear
reglin = LinearRegression()
reglin.fit(dados_treino, alvos_treino)
# Fazer previsões no conjunto de teste
alvos_previstos = reglin.predict(dados_teste)
# Calcular o erro médio quadrado
mse = mean_squared_error(alvos_teste, alvos_previstos)
# Ajustar tamanhos de fonte
plt.rc('font', size=12) # Tamanho da fonte das etiquetas dos eixos e título
plt.rc('axes', titlesize=14) # Tamanho da fonte do título do gráfico
# Visualizar os resultados
plt.scatter(dados_teste, alvos_teste, color='blue', label='Dados de teste')
plt.plot(dados_teste, alvos_previstos, color='red', linewidth=2, label='Regressão Linear')
plt.xlabel('Dados', fontsize=12)
plt.ylabel('Alvos', fontsize=12)
plt.title(f'Regressão Linear - MSE: {mse:.2f}')
plt.legend()
plt.show()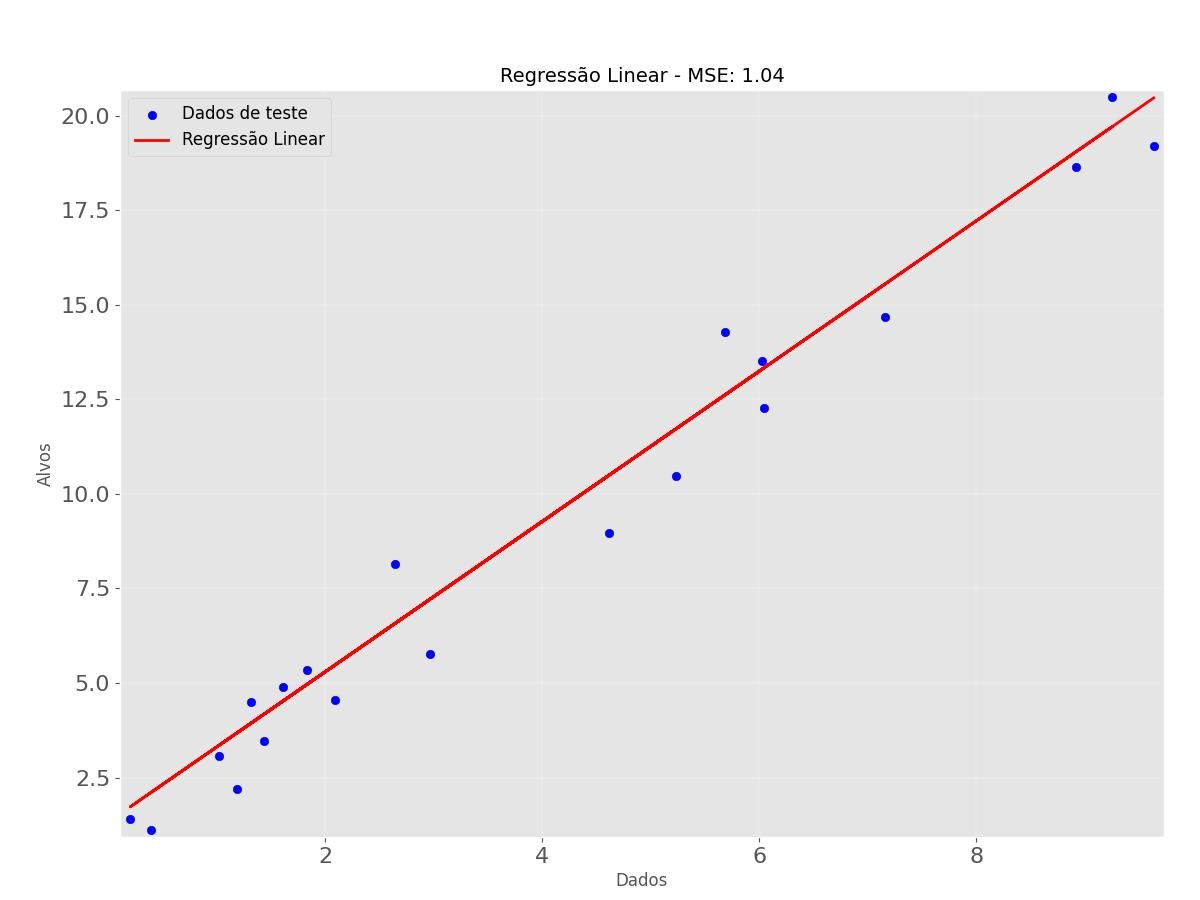
Neste exemplo, estamos gerando dados de exemplo, dividindo-os em conjuntos de treinamento e teste, treinando um modelo de regressão linear, fazendo previsões e, finalmente, visualizando os resultados usando a biblioteca matplotlib.
O código inclui os seguintes passos:
- Importamos as bibliotecas necessárias, incluindo numpy, matplotlib, train_test_split, LinearRegression e mean_squared_error do Scikit-Learn.
- Geramos dados de exemplo usando numpy, incluindo uma relação linear com ruído.
- Dividimos os dados em conjunto de treinamento e teste usando train_test_split.
- Treinamos um modelo de regressão linear usando LinearRegression.
- Fazemos previsões no conjunto de teste.
- Calculamos o erro médio quadrado (MSE) entre as previsões e os valores reais.
- Visualizamos os dados de teste e a linha de regressão linear usando matplotlib.
Este exemplo demonstra como usar o Scikit-Learn para treinar um modelo de regressão linear e visualizar os resultados para avaliar o desempenho do modelo.
3.2 - Keras
3.3 - TensorFlow
3.4 - PyTorch
3.5 - XGBoost
3.6 - LightGBM
3.7 - Pandas
3.8 - Numpy
3.9 - Matplotlib
3.10 - Seaborn



