
13 - Aprendizado Profundo (DL - Deep Learning)
O Aprendizado Profundo (DL - Deep Learning) no campo do Aprendizado de Máquina (ML - Machine Learning) é uma abordagem revolucionária que tem transformado a capacidade de computadores entenderem e processarem dados complexos.
Utilizando redes neurais profundas, compostas por camadas de unidades de processamento, o DL é capaz de aprender representações de dados cada vez mais abstratas e complexas.
Isso tem levado a avanços significativos em tarefas como reconhecimento de imagens, processamento de linguagem natural (NLP - Natural Language Processing) e muito mais.
À medida que os modelos se tornam mais profundos e as técnicas de treinamento se aprimoram, o DL continua a moldar o futuro da inteligência artificial e a encontrar aplicações em uma ampla gama de setores.
O DL se concentra em treinar modelos de redes neurais artificiais para realizar tarefas complexas de aprendizado a partir de dados brutos, e tem sido uma das tecnologias mais revolucionárias na área de inteligência artificial nas últimas décadas, impulsionando avanços significativos em diversas áreas, como visão computacional, NLP, reconhecimento de fala, jogos, entre outros.
Aqui estão os principais aspectos e conceitos do DL:
- Bibliotecas e Frameworks: Para implementar modelos de DL, os cientistas de dados e engenheiros usam bibliotecas e frameworks populares como TensorFlow, Keras e PyTorch, que oferecem ferramentas poderosas e flexíveis para construir, treinar e implantar modelos de DL.
- Redes Neurais Artificiais: O DL se baseia em redes neurais artificiais, que são modelos inspirados na estrutura e funcionamento do cérebro humano. Essas redes consistem em várias camadas de neurônios, cada um realizando operações simples, mas quando organizados em camadas, são capazes de aprender representações complexas dos dados.
- Camadas e Arquiteturas: As redes neurais de DL são compostas por várias camadas, incluindo camadas de entrada, camadas ocultas e camadas de saída. Existem diferentes arquiteturas de redes neurais, como Redes Neurais Convolucionais (CNNs - Convolutional Neural Networks) para visão computacional, Redes Neurais Recorrentes (RNNs - Recurrent Neural Networks) para sequências de dados e Redes Neurais Generativas (GANs - Generative Adversarial Networks) para geração de conteúdo.
- Aprendizado de Características (Feature Learning): Um dos principais aspectos do DL é sua capacidade de aprender características relevantes e significativas diretamente dos dados brutos. Isso significa que os modelos de DL podem aprender representações hierárquicas das características dos dados, o que torna o processo de extração de características manual menos necessário.
- Retropropagação (Backpropagation): O treinamento de redes neurais em DL é geralmente realizado usando o algoritmo de retropropagação (Backpropagation), que ajusta os pesos e viéses (bias) das conexões entre os neurônios com base nos erros obtidos durante o processo de treinamento.
- Transferência de Aprendizado (Transfer Learning): Uma técnica comum no DL é a transferência de aprendizado, que consiste em aproveitar modelos pré-treinados em grandes conjuntos de dados para tarefas específicas. Isso permite economizar tempo e recursos de treinamento e alcançar melhores resultados, especialmente quando os dados de treinamento são limitados.
- Aprendizados Supervisionado e Não Supervisionado: O DL pode ser aplicado tanto em tarefas de aprendizado supervisionado (com rótulos) quanto em tarefas de aprendizado não supervisionado (sem rótulos). Para o aprendizado supervisionado, as redes são treinadas com pares esperados de entrada e saída, enquanto no aprendizado não supervisionado, as redes aprendem a partir de dados não rotulados.
- Hardware: O treinamento de redes neurais profundas requer grandes quantidades de dados e poder computacional. Treinar modelos complexos pode ser computacionalmente intensivo e requer hardware especializado, como GPUs - Graphics Processing Units (Unidades de Processamento Gráfico) e TPUs - Tensor Processing Units (Unidades de Processamento de Tensores).
As técnicas de DL são aplicadas em uma variedade de campos e setores, devido à sua capacidade de lidar com tarefas complexas e aprender representações significativas diretamente dos dados brutos.
Algumas das principais áreas de aplicação incluem:
- Visão Computacional: O DL é amplamente usado em tarefas de visão computacional, como classificação de imagens, detecção de objetos, segmentação de imagens, reconhecimento facial, identificação de padrões, processamento de vídeo e muito mais.
- Processamento de Linguagem Natural (NLP - Natural Language Processing): As técnicas de DL são aplicadas em tarefas de NLP, como classificação de texto, tradução automática, resumo de texto, análise de sentimentos, processamento de voz e compreensão de linguagem natural.
- Reconhecimento de Fala: O DL é usado em sistemas de reconhecimento de fala para converter o discurso em texto, o que é amplamente utilizado em assistentes virtuais, sistemas de transcrição, controle de dispositivos por voz e muito mais.
- Jogos: Técnicas de DL têm sido usadas para treinar modelos que podem superar humanos em jogos complexos, como Go, xadrez, Dota 2 e StarCraft II.
- Saúde: Em aplicações médicas, o DL é usado para diagnóstico médico, detecção de doenças em imagens médicas (por exemplo, câncer de mama), análise de dados clínicos e previsão de resultados médicos.
- Setor Automotivo: No setor automotivo, o DL é aplicado em sistemas de condução autônoma para processar dados de sensores, tomar decisões em tempo real e ajudar a prevenir acidentes.
- Finanças: Em finanças, técnicas de DL são usadas para análise de risco, detecção de fraudes em transações financeiras, previsão de preços de ativos e otimização de investimentos.
- Indústria: Na indústria, o DL é aplicado em automação de processos, controle de qualidade, manutenção preditiva, visão computacional em robôs, entre outras aplicações.
Exemplo de visão Computacional:
No vídeo, à esquerda temos a simulação de 3 câmeras e à direita uma janela rodando em paralelo, em uma thread separada, detectando a presença de pessoas nas imagens das câmeras.
Essas são apenas algumas das inúmeras áreas onde as técnicas de DL têm sido aplicadas com sucesso. A flexibilidade e o poder das redes neurais artificiais possibilitam sua utilização em uma ampla variedade de problemas e cenários, tornando o DL uma das tecnologias mais impactantes e em constante crescimento no campo da inteligência artificial.
Existem várias bibliotecas Python especializadas em DL que oferecem ferramentas poderosas para construir, treinar e implantar modelos de redes neurais.
Algumas das principais bibliotecas são:
- TensorFlow: Desenvolvida pelo Google Brain, o TensorFlow é uma das bibliotecas mais populares e amplamente utilizadas para DL, proporcionando uma arquitetura flexível que permite criar modelos complexos de redes neurais, suporte a GPUs para acelerar o treinamento e implantação em diferentes plataformas.
- Keras: Keras é uma biblioteca de alto nível construída em cima do TensorFlow (e outras bibliotecas de DL, como Theano e Microsoft Cognitive Toolkit). Ele oferece uma API simples e intuitiva que facilita a construção rápida de modelos de redes neurais.
- PyTorch: Desenvolvido pelo Facebook, o PyTorch é outra biblioteca popular de DL. Ele se destaca por sua flexibilidade e facilidade de depuração, sendo amplamente adotado tanto em pesquisas acadêmicas quanto em aplicações industriais.
- MXNet: O MXNet é uma biblioteca escalável para DL, que oferece suporte a diferentes tipos de hardware, incluindo CPUs, GPUs e TPUs. Ele é conhecido por sua eficiência e desempenho em treinamento de modelos em grande escala.
- Caffe: O Caffe é uma biblioteca popular usada principalmente em visão computacional. Ele foi desenvolvido pela equipe da Universidade da Califórnia em Berkeley e é conhecido por sua velocidade e facilidade de uso.
- Theano: Embora o desenvolvimento oficial do Theano tenha sido encerrado, ele ainda é usado em algumas aplicações. O Theano foi uma das primeiras bibliotecas de DL em Python e serviu como base para o desenvolvimento de outras bibliotecas, como o Keras.
- CNTK (Microsoft Cognitive Toolkit): Desenvolvido pela Microsoft, o CNTK é outra biblioteca que oferece suporte a treinamento e inferência em redes neurais profundas. Ele se destaca por sua eficiência e suporte a múltiplas GPUs.
Essas são algumas das principais bibliotecas Python especializadas em DL. Cada uma delas tem suas características únicas e vantagens, e a escolha depende das necessidades específicas do projeto, da preferência pessoal e do suporte de hardware disponível. Muitas vezes, as bibliotecas são usadas em conjunto para aproveitar o melhor de cada uma delas.
O DL é uma poderosa abordagem de ML que tem tido um impacto significativo em várias áreas, permitindo que máquinas realizem tarefas complexas e alcancem resultados impressionantes em visão computacional, NLP e muitas outras aplicações. Seu contínuo desenvolvimento e avanços têm levado a conquistas notáveis em inteligência artificial e, por isso, o DL é amplamente adotado em projetos e pesquisas em todo o mundo.
13.1 - Introdução às Redes Neurais
As Redes Neurais Artificiais (ANNs - Artificial Neural Networks) representam um dos pilares do ML, sendo fundamentais para tarefas de classificação, regressão e muito mais. Inspiradas pelo funcionamento do cérebro humano, ANNs consistem em camadas de neurônios interconectados, que processam informações e aprendem a partir de dados. No entanto, a capacidade de ANNs de modelar relações em dados tabulares e sequenciais é limitada.
Para lidar com dados de imagem, as Redes Neurais Convolucionais (CNNs - Convolutional Neural Networks) surgiram como uma revolução. Com suas camadas convolucionais, as CNNs extraem características espaciais de imagens, tornando-as ideais para tarefas de visão computacional, como reconhecimento de objetos e segmentação de imagens. Elas são altamente eficazes na captura de padrões visuais complexos.
Enquanto ANNs e CNNs brilham em tarefas relacionadas a dados tabulares e imagens, as Redes Neurais Recorrentes (RNNs - Recurrent Neural Networks) são projetadas para lidar com dados sequenciais, como texto e séries temporais. As RNNs têm memória interna e podem capturar dependências temporais em dados, tornando-os adequados para tarefas de NLP, tradução automática e previsão de séries temporais.
As ANNs formam a base do ML e são amplamente aplicadas em muitas tarefas, as CNNs são a escolha principal para tarefas de visão computacional, enquanto as RNNs são cruciais para tarefas envolvendo dados sequenciais. A combinação dessas arquiteturas permite abordar uma ampla gama de problemas de ML, tornando as redes neurais uma ferramenta versátil na era da inteligência artificial.
As GANs (Redes Generativas Adversariais) são uma arquitetura especial de rede neural usada para a geração de dados, como imagens, e têm características únicas em comparação com ANNs, CNNs e RNNs
13.1.1 - Redes Neurais Artificiais (ANN - Artificial Neural Networks)
13.1.2 - Redes Neurais Convolucionais (CNNs - Convolutional Neural Networks)
As Redes Neurais Convolucionais (CNNs - Convolutional Neural Networks) são um tipo especializado de ANNs que se destacam em tarefas de visão computacional, como classificação de imagens, detecção de objetos e segmentação semântica.
Elas foram inspiradas pela organização do córtex visual no cérebro humano e têm demonstrado um desempenho impressionante em diversas aplicações.
As CNNs são projetadas para trabalhar com dados que têm uma estrutura espacial, como imagens, e têm a capacidade de aprender representações hierárquicas e invariantes da translação de características dos dados.
Isso é possível devido a duas operações principais que as CNNs empregam: convolução e agrupamento (pooling).
Conceitos das CNNs:
- Aplicação: Usadas principalmente em visão computacional para classificação de imagens, detecção de objetos e processamento de imagens.
- Estrutura: Projetadas para dados de grade, como imagens, com camadas de convolução que preservam a estrutura espacial. Usam convolução para extrair características espaciais em dados de grade.
- Arquitetura: As CNNs geralmente têm uma arquitetura empilhada com várias camadas de convolução, seguidas por camadas de agrupamento e camadas totalmente conectadas no final. Algumas arquiteturas famosas incluem a LeNet, AlexNet, VGG, ResNet, Inception e muitas outras.
- Uso de Memória: Não possuem memória interna; operações locais.
- Paralelismo: Paralelismo limitado nas camadas de convolução.
Camadas nas CNNs:
- Camada de Convolução (Conv2D): Essa camada aplica filtros de convolução a uma entrada para extrair características locais em imagens, como bordas, texturas e padrões mais complexos e outros atributos importantes para a tarefa de classificação ou detecção. A convolução é a operação central em uma CNN. Ela consiste em aprender aplicando um conjunto de filtros (ou kernels) sobre a imagem de entrada para extrair características relevantes. Os filtros são pequenas janelas deslizantes que se movem pela imagem, calculando o produto escalar entre si e a região da imagem que está sendo analisada. Isso produz um mapa de características que ressalta padrões específicos presentes na imagem.
- Camadas de Agrupamento (Pooling) (MaxPooling2D, AveragePooling2D): As camadas de agrupamento (pooling, também conhecidas como camadas de subamostragem) são usadas para reduzir a dimensionalidade dos mapas de características, reduzindo a resolução espacial, mantendo as características mais relevantes e tornar a rede computacionalmente mais eficiente. A operação de agrupamento, geralmente agrupamento máximo (max pooling), seleciona o valor máximo em uma região da imagem, descartando o restante. Isso ajuda a preservar as informações mais relevantes e a reduzir o efeito da variação espacial. O MaxPooling2D, por exemplo, mantém o valor máximo em uma região, enquanto o AveragePooling2D usa a média.
- Camada de Normalização de Lotes (Batch Normalization): Essa camada normaliza os valores nas camadas anteriores, o que pode acelerar o treinamento e torná-lo mais estável.
- Camada de Ativação (ReLU): A função de ativação ReLU - Rectified Linear Unit (Unidade Linear Retificada) é frequentemente usada após as camadas de convolução e outras para introduzir não linearidade na rede.
- Camadas Totalmente Conectadas (Dense): Em redes profundas, as Camadas Totalmente Conectadas (Fully Connected Layers) são camadas densas totalmente conectadas, usadas para realizar classificação final ou outras tarefas. Após as camadas de convolução e de agrupamento, os dados são achatados e alimentados em camadas totalmente conectadas, semelhantes às utilizadas em redes neurais tradicionais. Essas camadas finais são responsáveis por fazer a classificação ou regressão com base nas características extraídas anteriormente.
Podemos observar como funciona uma CNN na prática com o diagrama abaixo:
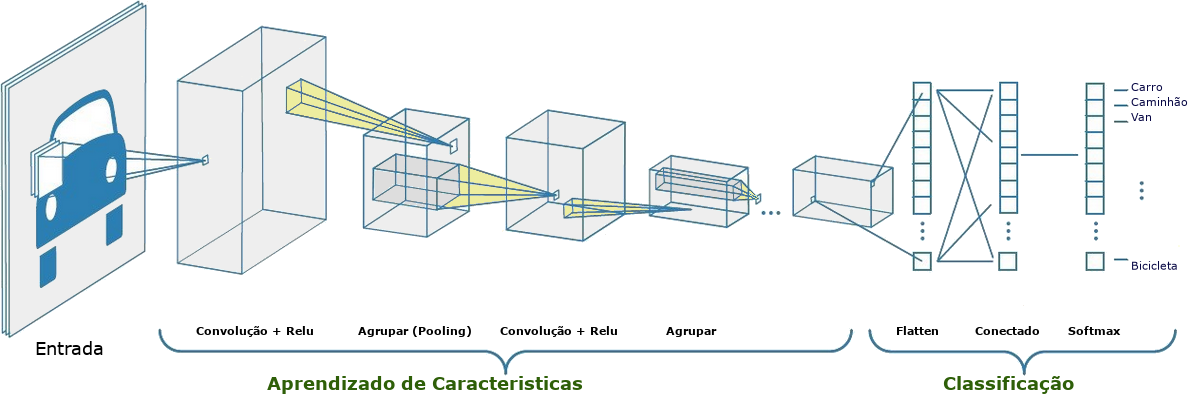
Na primeira etapa, entrada, a rede irá receber uma imagem já pré-processada, geralmente a imagem é representada em 3 camadas RGB ou em tons de cinza.
Em seguida, na etapa de aprendizado de características (feature learning), estas serão aprendidas pelos processos de convolução e agrupamento.
O processo de convolução consiste em utilizar um filtro, também chamado de kernel, para percorrer várias pequenas matrizes na imagem e identificar suas características mais importantes.
Quanto ao agrupamento (pooling), que pode ser interpretado como uma camada simplificadora da camada anterior, atua reduzindo o tamanho dos mapas de características gerados pelas camadas de convolução, para que o processo seja otimizado no decorrer da rede.
Na última etapa, classificação, a rede usará um Perceptron de Múltiplas Camadas (MLP - Multi-Layer Perceptron), ou uma camada totalmente conectada, para realizar a classificação baseando-se nas características obtidas na etapa de aprendizagem de características.
Perceptrons de múltiplas camadas são uma classe de redes neurais artificiais que consistem em múltiplas camadas de neurônios interconectados, incluindo uma camada de entrada, uma ou mais camadas ocultas e uma camada de saída. Cada neurônio em uma camada está conectado a todos os neurônios na camada seguinte, tornando os MLPs capazes de aprender representações complexas de dados. São amplamente utilizados para tarefas de classificação, regressão e outras tarefas de aprendizado supervisionado, devido à sua capacidade de modelar relações não lineares nos dados. O treinamento de MLPs geralmente envolve algoritmos de retropropagação, que ajustam os pesos das conexões para minimizar uma função de perda, permitindo que o modelo faça previsões precisas.
Aqui está um exemplo de como as classes de camadas do Keras podem ser usadas em uma arquitetura de CNN:
from tensorflow.keras.layers import Conv2
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.models import Sequential
from tensorflow.keras.datasets import mnist
(x_treino, y_treino), (x_teste, y_teste) = mnist.load_data()
modelo = Sequential()
modelo.add(Conv2(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
modelo.add(MaxPooling2D((2, 2)))
modelo.add(Flatten())
modelo.add(Dense(128, activation='relu'))
modelo.add(Dense(10, activation='softmax'))
modelo.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
modelo.fit(x_treino, y_treino, epochs=10)
modelo.evaluate(x_teste, y_teste)
modelo.predict(x_teste)As CNNs têm tido um impacto significativo em tarefas de visão computacional e se mostraram altamente eficazes em reconhecimento de padrões em imagens.
Além disso, suas arquiteturas têm sido adaptadas para outros tipos de dados estruturados, como séries temporais e dados de áudio.
Devido ao seu poder de representação e aprendizado de características relevantes, as CNNs são amplamente utilizadas em uma variedade de aplicações, desde carros autônomos até diagnóstico médico e muito mais.
13.1.3 - Redes Neurais Recorrentes (RNNs - Recurrent Neural Networks)
13.1.4 - Redes Neurais Generativas (GANs - Generative Adversarial Networks)
13.2 - Conceitos Importantes
13.3 - Camadas e Arquiteturas
13.4 - Frameworks e Bibliotecas
13.5 - Hardware
13.6 - Desafios
13.7 - Keras
13.8 - Exemplos com Keras
São apresentados 4 exemplos usando as bibliotecas Keras.
São exemplos para classificar spams, imagens de cães, gatos e outras categorias e imagens de dígitos.
13.8.1 - Classificar Spams
Este código primeiro carrega os dados de treinamento e teste do conjunto de dados Reuters.
O conjunto de dados Reuters é um conjunto de dados com aproximadamente 10 mil mensagens de notícias classificadas em 46 categorias diferentes.
O código então normaliza os dados dividindo cada caractere por 255. Em seguida, o código cria um modelo de rede neural.
Este modelo é uma rede neural simples com duas camadas ocultas, cada uma com 128 neurônios.
A camada de saída tem 10 neurônios, um para cada classe no conjunto de dados. O código então compila o modelo, definindo o otimizador, a função de perda e as métricas.
Em seguida, o código treina o modelo, alimentando os dados de treinamento.
Por fim, o código avalia o desempenho do modelo, alimentando os dados de teste.
O código imprime a acurácia do modelo, que é a porcentagem de mensagens de notícias que o modelo classificou corretamente.
import numpy as np # álgebra linear
import pandas as pd # processamento de dados, CSV
from keras.datasets import reuters # conjuntos de dados e alvosCarregar e dividir os dados de treinamento e teste.
(dados_treino, alvos_treino), (dados_teste, alvos_teste) = reuters.load_data(num_words=10000)Usando o backend TensorFlow.
Dê uma olhada nos dados.
Conjuntos de dados e alvos de treino.
Dados de treino:
print('*** Dados do conjunto de treino')
print(f'Dimensões: {dados_treino.shape}')
print()
print(dados_treino)Alvos de treino:
print('*** Alvos do conjunto de treino')
print(f'Dimensões: {alvos_treino.shape}')
print()
print(alvos_treino)Conjuntos de dados e alvos de teste.
Dados de teste:
print('*** Dados do conjunto de teste')
print(f'Dimensões: {dados_teste.shape}')
print()
print(dados_teste)Alvos de teste:
print('*** Alvos do conjunto de teste')
print(f'Dimensões: {alvos_teste.shape}')
print()
print(alvos_teste)Cada exemplo é uma lista de inteiros (índices de palavras).
Podemos transformá-lo novamente em palavras usando o método get_word_index(), que retorna um dicionário de palavras e seus respectivos índices.
No exemplo a seguir a variável indice_palavra é um dicionário de palavras e seus respectivos índices.
indice_palavra = reuters.get_word_index()
print("*** Tamanho dicionário de palavras/índices:", len(indice_palavra))
print(list(índice_palavra.items())[:10]) # 10 primeiros elementosA variável indice_palavra_reversa é um dicionário de índices e as respectivas palavras, criado a partir da inversão das colunas palavra/indice dos itens de em indice_palavra para indice/palavra nos itens de indice_palavra_reversa.
indice_palavra_reversa = dict([(valor,chave) for (chave, valor) in indice_palavra.items()])
print(list(indice_palavra_reversa.items())[-10:]) # 10 primeiros elementosOs valores numéricos utilizados em dados_treino podem assim ser usados para representar palavras, encontradas no dicionário da variável indice_palavra_reversa.
noticias_decodificadas = ' '.join([indice_palavra_reversa.get(i - 3, '?') for i in dados_treino[0]])
print(noticias_decodificadas)O rótulo associado a um exemplo é um número inteiro entre 0 e 45 (índice de tópico).
Preparando os dados
Vamos vetorizar os dados de treinamento usando o tensor inteiro e o train_label usando a codificação one-hot.
A codificação one-hot (one-hot encoding), também chamada de codificação categórica, é um formato amplamente utilizado para dados categóricos.
def vetorizar_sequencias(sequencias, dimension=10000):
resultados = np.zeros((len(sequencias),dimension))
for i,sequencia in enumerate(sequencias):
resultados[i,sequencia] = 1
return resultados
dados_treino = vetorizar_sequencias(dados_treino)
dados_teste = vetorizar_sequencias(dados_teste)
print('*** Amostra de dados de treino:')
print(dados_treino[0])
print()
print('*** Amostra de dados de teste:')
print(dados_teste[0])Função to_categorical() integrada com a codificação one-hot
from keras.utils import to_categorical
rotulos_treino_one_hot = to_categorical(alvos_treino)
rotulos_teste_one_hot = to_categorical(alvos_teste)
print(f'uma amostra de rótulos one-hot: {rotulos_treino_one_hot[0]}')Construindo a rede
Na construção das pilhas de camadas Dense, cada camada só pode acessar as informações da saída da camada anterior.
Se uma das camadas deixar "cair" alguma informação sobre a classificação, cada camada poderá se tornar um gargalo de informações.
É por isso que usaremos camadas maiores.
from keras import models
from keras import layers
modelo = models.Sequential()
modelo.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
modelo.add(layers.Dense(64, activation='relu'))
modelo.add(layers.Dense(46, activation='softmax'))
modelo.compile(
optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])Validando nossa abordagem
Vamos dividir dados_treino em dados_treino_parciais e valores_dados.
Vamos colocar 1000 amostras de dados_treino em valores_dados.
valores_dados = dados_treino[:1000]
dados_treino_parciais = dados_treino[1000:]
valores_alvos = rotulos_treino_one_hot[:1000]
alvos_treino_parciais = rotulos_treino_one_hot[1000:]
history = modelo.fit(
dados_treino_parciais,
alvos_treino_parciais,
epochs=20,
batch_size=512,
validation_data=(valores_dados,valores_alvos))Plotando a perda de treinamento e validação
import matplotlib.pyplot as plt
perdas = history.history['loss']
valores_perda = history.history['val_loss']
episodios = range(1,len(perdas) + 1)
plt.clf()
plt.plot(episodios, perdas, 'r', label='Perdas de treinamento')
plt.plot(episodios, valores_perda, 'b', label='Perdas de validação')
plt.title('Perda de treinamento versus perda de validação')
plt.xlabel('Episódios')
plt.ylabel('Perdas')
plt.legend()
plt.show()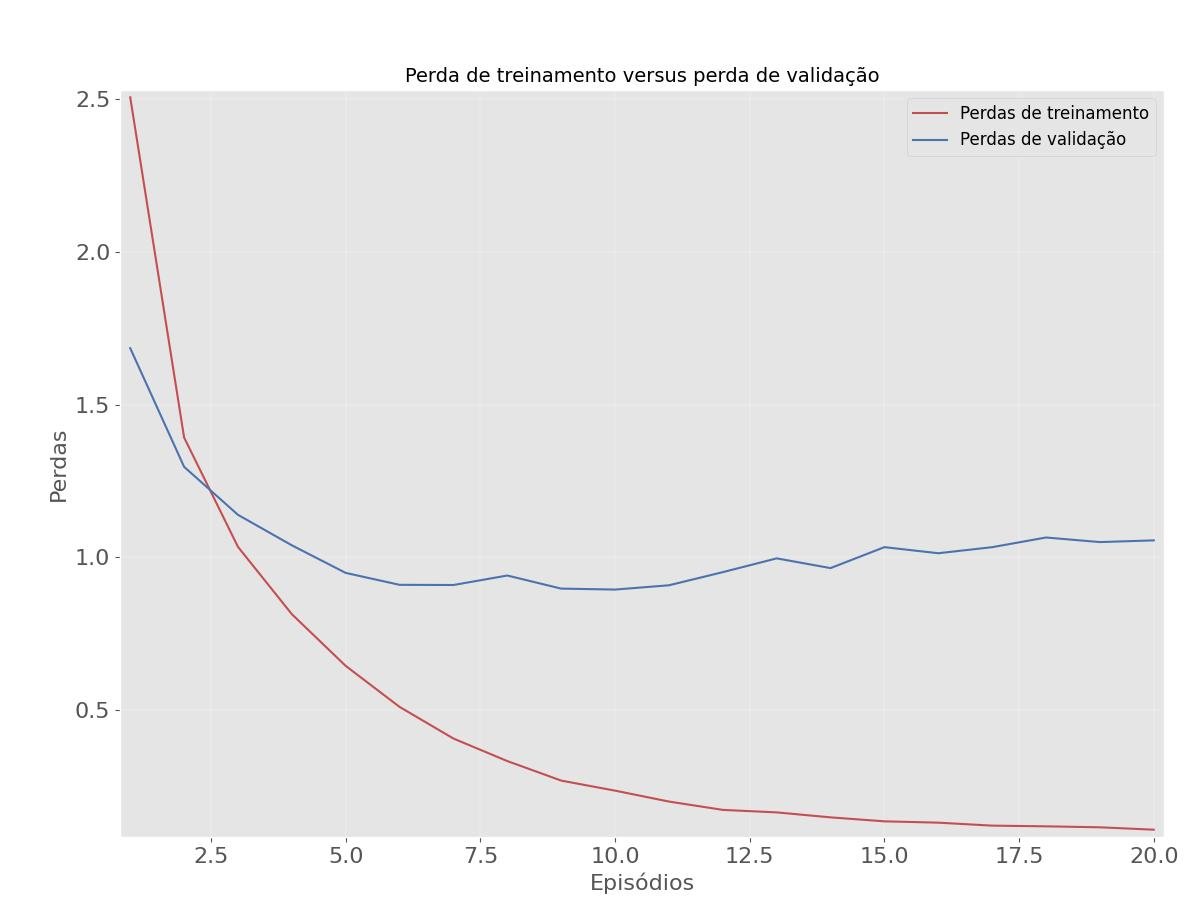
Traçando a precisão do treinamento e da validação.
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
plt.clf()
plt.plot(episodios, acc, 'r', label='Acurácia do treinamento')
plt.plot(episodios, val_acc, 'b', label='Acurácia de validação')
plt.xlabel('Episódios')
plt.ylabel('Acurácia')
plt.legend()
plt.show()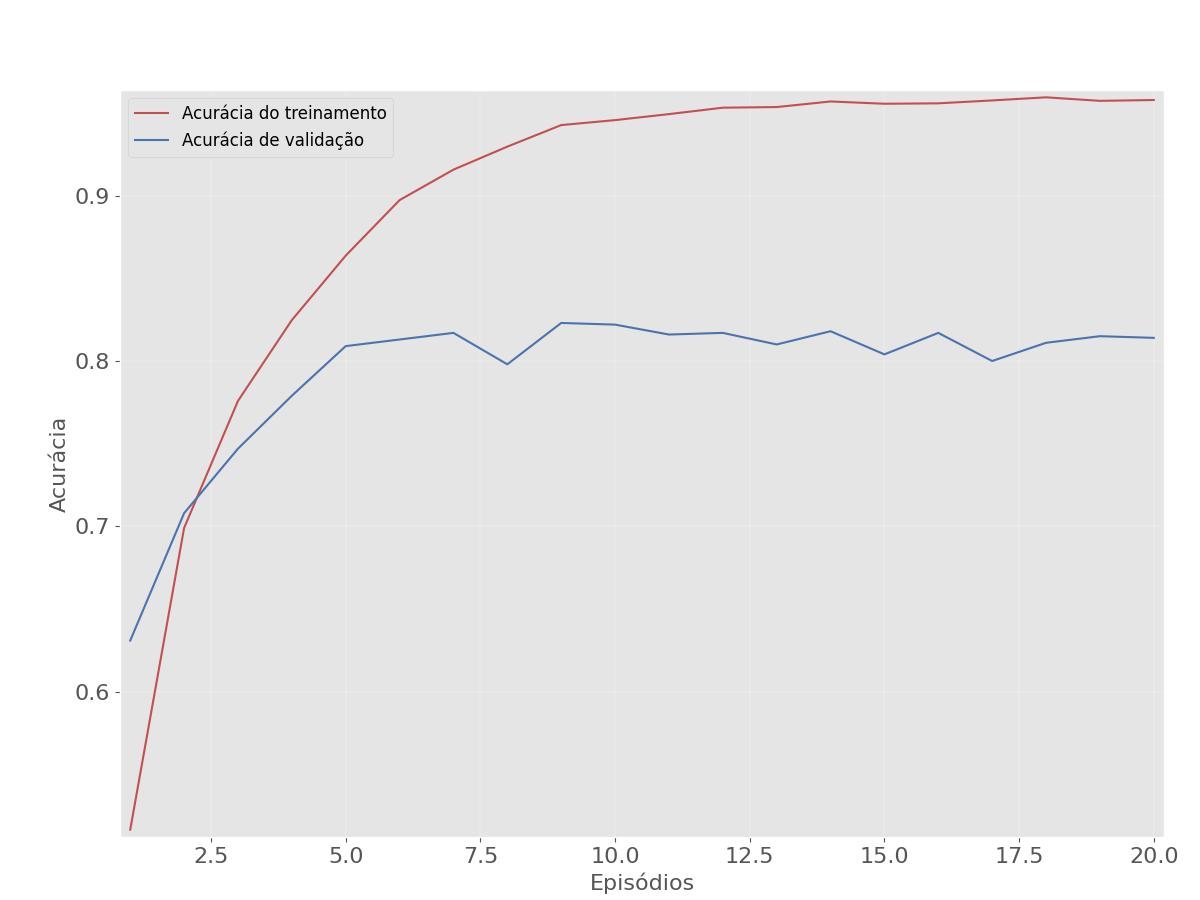
Recalculando:
modelo = models.Sequential()
modelo.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
modelo.add(layers.Dense(64, activation='relu'))
modelo.add(layers.Dense(46, activation='softmax'))
modelo.compile(
optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
modelo.fit(dados_treino_parciais,
alvos_treino_parciais,
epochs=9,
batch_size=512,
validation_data=(valores_dados,valores_alvos))Avalie o modelo.
resultados = modelo.evaluate(dados_teste, rotulos_teste_one_hot)Imprima os resultados.
print(resultados)A perda é uma medida que indica o quão bem o modelo está performando na tarefa.
Neste caso, a perda é relativamente alta, indicando que o modelo está tendo dificuldades em fazer previsões precisas.
Uma perda de aproximadamente 1 é considerada relativamente alta para muitos problemas de classificação.
Isso pode sugerir que o modelo está tendo dificuldades em se ajustar aos dados de treinamento e está cometendo erros significativos.
A acurácia (ou precisão) é uma métrica que expressa a porcentagem de classificações corretas em relação ao total de amostras no conjunto de teste.
No exemplo, a precisão é de cerca de 78%, o que significa que o modelo está classificando corretamente aproximadamente 78% das amostras no conjunto de teste.
A interpretação dos resultados depende do contexto da tarefa e das expectativas de desempenho. Neste caso, os valores sugerem que o modelo não está performando tão bem quanto em alguns outros cenários.
A perda relativamente alta pode indicar problemas com o treinamento do modelo, como sobreajuste (ajuste excessivo, overfitting) ou subajuste (underfitting), que podem ser resolvidos ajustando os hiperparâmetros do modelo.
A precisão de 78% também indica que o modelo está cometendo erros em cerca de 22% das previsões, o que pode ou não ser aceitável, dependendo da natureza da tarefa.
Portanto, seria aconselhável realizar uma análise mais aprofundada do modelo, ajustar hiperparâmetros, explorar diferentes arquiteturas de rede ou realizar outras ações para melhorar o desempenho, caso seja necessário.
Modelo com gargalo de informações
Modelos com camadas intermediárias com menos de 46 unidades ocultas.
modelo = models.Sequential()
modelo.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
modelo.add(layers.Dense(4, activation='relu'))
modelo.add(layers.Dense(46, activation='softmax'))
modelo.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
modelo.fit(dados_treino_parciais,
alvos_treino_parciais,
epochs=20,
batch_size=128,
validation_data=(valores_dados, valores_alvos))
resultados = modelo.evaluate(dados_teste, rotulos_teste_one_hot)Imprima os resultados.
print(resultados)Utilizando mais neurônios que o necessário em uma camada Dense.
modelo = models.Sequential()
modelo.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
modelo.add(layers.Dense(128, activation='relu'))
modelo.add(layers.Dense(46, activation='softmax'))
modelo.compile(
optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
modelo.fit(
dados_treino_parciais,
alvos_treino_parciais,
epochs=20,
batch_size=128,
validation_data=(valores_dados, valores_alvos))
resultados = modelo.evaluate(dados_teste, rotulos_teste_one_hot)print(resultados)Com apenas duas camadas Dense.
modelo = models.Sequential()
modelo.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
modelo.add(layers.Dense(46, activation='softmax'))
modelo.compile(
optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
modelo.fit(
dados_treino_parciais,
alvos_treino_parciais,
epochs=20,
batch_size=128,
validation_data=(valores_dados, valores_alvos))
resultados = modelo.evaluate(dados_teste, rotulos_teste_one_hot)Imprima os resultados:
print(resultados)13.8.2 - Classificar Imagens com CIFAR-10
13.8.3 - CIFAR-100 Usando Vision Transformers (ViT)
No artigo acadêmico An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, os autores mencionam que os Tranformadores de Visão (ViT - Vision Transformers) são ávidos por dados.
Portanto, pré-treinar um ViT em um conjunto de dados de grande porte como JFT300M e ajustá-lo em conjuntos de dados de tamanho médio (como ImageNet) é a única maneira de superar os modelos de rede neural convolucional de última geração.
JFT-300M é um conjunto de dados interno do Google usado para treinar modelos de classificação de imagens, rotuladas usando-se um algoritmo com uma mistura complexa de sinais brutos da web, conexões entre páginas da web e feedback do usuário, resultando em mais de um bilhão de rótulos para 300 milhões de imagens (uma única imagem pode ter vários rótulos). Dos bilhões de rótulos de imagens, aproximadamente 375 milhões são selecionados por meio de um algoritmo que visa maximizar a precisão dos rótulos das imagens selecionadas.
A camada de autoatenção do ViT carece de viés indutivo de localidade (a noção de que os pixels da imagem são correlacionados localmente e que seus mapas de correlação são invariantes à tradução). Esta é a razão pela qual os ViTs precisam de mais dados. Por outro lado, as CNNs analisam as imagens através de janelas deslizantes espaciais, o que as ajuda a obter melhores resultados com conjuntos de dados menores.
As camadas de autoatenção (self-attention), são componentes fundamentais em arquiteturas de modelos como o Transformador (Transformer) e também são usadas nas Redes Neurais Convolucionais (CNNs) de ViT, desempenhando um papel crucial na extração de informações contextuais dos dados e permitindo que o modelo se concentre em partes relevantes da entrada durante o processamento.
Em um contexto de ViT, essas camadas de autoatenção são particularmente interessantes porque permitem que o modelo lide com imagens de forma eficaz, capturando as relações entre pixels ou correções (patches) de maneira eficaz e permitindo que o modelo aprenda a atenção em patchs de maneira semelhante à sua aplicação em dados sequenciais, como texto. Isso permite que as ViTs capturem relações espaciais e semânticas em imagens.
As camadas de autoatenção funcionam da seguinte forma:
- Entrada Fracionada: Na ViT, a imagem de entrada é dividida em patches (pequenas partes retangulares) que são tratados como sequências. Cada patch é incorporado em um espaço vetorial.
- Autoatenção Multi-Cabeça: As camadas de autoatenção são compostas por várias cabeças de autoatenção que operam paralelamente. Cada cabeça aprende a atenção em relação a diferentes aspectos da entrada.
- Aprendizado de Pesos: Em cada cabeça de autoatenção, os pesos são aprendidos para determinar a importância das relações entre os patches. Os pesos refletem a similaridade entre os patches, permitindo que o modelo dê mais peso a regiões relevantes da imagem.
- Composição do Contexto: Os resultados das várias cabeças de autoatenção são combinados para formar um contexto global que captura as interações entre todos os patches da imagem.
- Processamento em Camadas: Várias camadas de autoatenção são empilhadas em uma arquitetura, permitindo que o modelo processe informações em várias etapas e capture características complexas.
No artigo acadêmico Vision Transformer for Small-Size Datasets, os autores se propuseram a resolver o problema do viés indutivo de localidade em ViTs.
As ideias principais são:
- Tokenização de correção por deslocamento
- Autoatenção da localidade
Este exemplo implementa as ideias do artigo. Grande parte deste exemplo é inspirada na classificação de imagens com ViT.
Observação: Este exemplo requer o TensorFlow 2.6 ou superior, bem como os complementos do TensorFlow, que podem ser instalados usando o seguinte comando:
pip install -qq -U tensorflow-addonsImportar as bibliotecas
Importe as bibliotecas necessárias.
import math
import numpy as np
import tensorflow as tf
from tensorflow import keras
import tensorflow_addons as tfa
import matplotlib.pyplot as plt
from tensorflow.keras import layersConfigurar o Keras
Configure a semente para reproduzibilidade.
SEED = 42
keras.utils.set_random_seed(SEED)Preparar dados
Prepare os dados com o número de classes e dimensões de entrada.
NUM_CLASSES = 100
DIMENSOES_ENTRADA = (32, 32, 3)Carregar dados(ViT)
Carregue os conjuntos de dados e alvos de treino e teste, usando o dataset CIFAR-100.
(dados_treino, alvos_treino), (dados_teste, alvos_teste) = keras.datasets.cifar100.load_data()Imprima as dimensões dos dados.
print(f"dados_treino shape: {dados_treino.shape} - alvos_treino shape: {alvos_treino.shape}")
print(f"dados_teste shape: {dados_teste.shape} - alvos_teste shape: {alvos_teste.shape}")Configurar os hiperparâmetros
Os hiperparâmetros cumprimem diferentes papéis, sinta-se à vontade para ajustar os hiperparâmetros.
# Dados
TAM_BUFFER = 512
TAM_LOTE = 256
# Aumento de dados
TAM_IMAGEM = 72
TAM_CORRECAO = 6
NUM_CORRECOES = (TAM_IMAGEM // TAM_CORRECAO) ** 2
# Otimizador
TAXA_APRENDIZADO = 0.001
PESO_DECAIMENTO = 0.0001
# Treinamento
EPISODIOS = 50
# Arquitetura
NORMA_CAMADA_EPS = 1e-6
CAMADAS_TRANFORMACAO = 8
DIM_PROJECAO = 64
NUM_CABECAS = 4
UNIDADES_TRANSFORMADORAS = [
DIM_PROJECAO * 2,
DIM_PROJECAO,
]
UNIDADES_CABECA_MLP = [2048, 1024]Aumentar dados
Um trecho do jornal:
"De acordo com o DeiT, várias técnicas são necessárias para treinar ViTs com eficácia.
Assim, aplicamos aumentos de dados como CutMix, Mixup, Auto Augment, Repeated Augment a todos os modelos."
Neste exemplo, focaremos apenas na novidade da abordagem e não na reprodução dos resultados do artigo.
Por esta razão, não utilizamos os esquemas de aumento de dados mencionados.
Sinta-se à vontade para adicionar ou remover o pipeline de aumento.
aumento_dados = keras.Sequential(
[
layers.Normalization(),
layers.Resizing(TAM_IMAGEM, TAM_IMAGEM),
layers.RandomFlip("horizontal"),
layers.RandomRotation(factor=0.02),
layers.RandomZoom(height_factor=0.2, width_factor=0.2),
],
name="data_augmentation",
)
# Calcule a média e a variância dos dados de treinamento para normalização.
aumento_dados.layers[0].adapt(dados_treino)Implementar tokenização de correção por deslocamento (STP)
Em um pipeline ViT, as imagens de entrada são divididas em patchs que são então projetados linearmente em tokens.
A tokenização de correção por deslocamento (SPT - Shift Patch Tokenization) é introduzida para combater o baixo campo receptivo dos ViTs.
As etapas para SPT são as seguintes:
- Carregar a imagem.
- Deslocá-la em direções diagonais.
- Concatenar as imagens deslocadas diagonalmente com a imagem original.
- Extrair patchs das imagens concatenadas.
- Achatar a dimensão espacial de todas correcões.
- Normalizar em camadas os patchs achatados e então projetá-las.

class TokenizacaoCorrecaoDeslocamento(layers.Layer):
def __init__(
self,
tamanho_imagem = TAM_IMAGEM,
tamanho_correcao = TAM_CORRECAO,
num_correcoes = NUM_CORRECOES,
dim_projecao = DIM_PROJECAO,
vanilla = False,
**kwargs,
):
super().__init__(**kwargs)
self.vanilla = vanilla # Sinalizador para mudar para extrator de correção Vanilla.
self.tamanho_imagem = tamanho_imagem
self.tamanho_correcao = tamanho_correcao
self.half_patch = tamanho_correcao // 2
self.correcoes_achatadas = layers.Reshape((num_correcoes, -1))
self.projecao = layers.Dense(units=dim_projecao)
self.normas_camada = layers.LayerNormalization(epsilon=NORMA_CAMADA_EPS)
# Amortecedor de corte por deslocamento
def crop_shift_pad(self, imagens, mode):
# Construir as imagens diagonais deslocadas
if mode == "left-up":
altura_corte = self.half_patch
largura_corte = self.half_patch
altura_deslocamento = 0
largura_deslocamento = 0
elif mode == "left-down":
altura_corte = 0
largura_corte = self.half_patch
altura_deslocamento = self.half_patch
largura_deslocamento = 0
elif mode == "right-up":
altura_corte = self.half_patch
largura_corte = 0
altura_deslocamento = 0
largura_deslocamento = self.half_patch
else:
altura_corte = 0
largura_corte = 0
altura_deslocamento = self.half_patch
largura_deslocamento = self.half_patch
# Corte as imagens deslocadas e preencha-as
corte = tf.image.crop_to_bounding_box(
imagens,
offset_height = altura_corte,
offset_width = largura_corte,
target_height = self.tamanho_imagem - self.half_patch,
target_width = self.tamanho_imagem - self.half_patch,
)
amortecedor_deslocamento = tf.image.pad_to_bounding_box(
corte,
offset_height = altura_deslocamento,
offset_width = largura_deslocamento,
target_height = self.tamanho_imagem,
target_width = self.tamanho_imagem,
)
return amortecedor_deslocamento
def call(self, imagens):
if not self.vanilla:
# Concatenar as imagens deslocadas com a imagem original
imagens = tf.concat(
[
imagens,
self.crop_shift_pad(imagens, mode="left-up"),
self.crop_shift_pad(imagens, mode="left-down"),
self.crop_shift_pad(imagens, mode="right-up"),
self.crop_shift_pad(imagens, mode="right-down"),
],
axis=-1,
)
# Corrija as correcoes achatando e projetando as imagens
correcoes = tf.image.extract_patches(
images = imagens,
sizes = [1, self.tamanho_correcao, self.tamanho_correcao, 1],
strides = [1, self.tamanho_correcao, self.tamanho_correcao, 1],
rates = [1, 1, 1, 1],
padding = "VALID",
)
correcoes_planas = self.correcoes_achatadas(correcoes)
if not self.vanilla:
# Normalize a camada dos <i>patchs</i> planos e projete-as linearmente
tokens = self.normas_camada(correcoes_planas)
tokens = self.projecao(tokens)
else:
# Projete linearmente os <i>patchs</i> planos
tokens = self.projecao(correcoes_planas)
return (tokens, correcoes)Visualizar as correcões
O gráfico a seguir mostra as correções projetadas.
# Obtenha uma imagem aleatória do conjunto de dados de treinamento e redimensione a imagem
imagem = dados_treino[np.random.choice(range(dados_treino.shape[0]))]
imagem_redimensionada = tf.image.resize(
tf.convert_to_tensor([imagem]), size=(TAM_IMAGEM, TAM_IMAGEM)
)
# Corretor Vanilla (<i>Vanilla Patch Maker</i>): Isso pega uma imagem e a divide em correcoes como no artigo ViT original
(token, correcao) = TokenizacaoCorrecaoDeslocamento(vanilla=True)(imagem_redimensionada / 255.0)
(token, correcao) = (token[0], correcao[0])
# Desloque a imagem em direções diagonais.
n = correcao.shape[0]
contagem = 1
plt.figure(figsize=(4, 4))
for linha in range(n):
for coluna in range(n):
plt.subplot(n, n, contagem)
contagem = contagem + 1
imagem = tf.reshape(correcao[linha][coluna], (TAM_CORRECAO, TAM_CORRECAO, 3))
plt.imshow(imagem)
plt.axis("off")
plt.show()
Tokenização de Patchs por Deslocamento (SPT - Shifted Patch Tokenization)
Esta camada pega a imagem e a desloca diagonalmente e depois extrai correções das imagens concatenadas.
(token, correcao) = TokenizacaoCorrecaoDeslocamento(vanilla=False)(imagem_redimensionada / 255.0)
(token, correcao) = (token[0], correcao[0])
n = correcao.shape[0]
imagens_deslocadas = ["ORIGINAL", "ESQUERDA-SUPERIOR", "ESQUERDA-INFERIOR", "DIREITA_SUPERIOR", "DIREITA-INFERIOR"]
for indice, nome in enumerate(imagens_deslocadas):
print(nome)
contagem = 1
plt.figure(figsize=(4, 4))
for linha in range(n):
for coluna in range(n):
plt.subplot(n, n, contagem)
contagem = contagem + 1
imagem = tf.reshape(correcao[linha][coluna], (TAM_CORRECAO, TAM_CORRECAO, 5 * 3))
plt.imshow(imagem[..., 3 * indice : 3 * indice + 3])
plt.axis("off")
plt.show()




Implementar a camada de codificação de correção
Esta camada aceita correções projetadas e então adiciona informações posicionais a eles.
class CodificadorCorrecao(layers.Layer):
def __init__(
self, num_correcoes=NUM_CORRECOES, dim_projecao=DIM_PROJECAO, **kwargs
):
super().__init__(**kwargs)
self.num_correcoes = num_correcoes
self.incorporacao_posicao = layers.Embedding(
input_dim=num_correcoes, output_dim=dim_projecao
)
self.posicoes = tf.range(start=0, limit=self.num_correcoes, delta=1)
def call(self, correcoes_codificadas):
posicoes_codificadas = self.incorporacao_posicao(self.posicoes)
correcoes_codificadas = correcoes_codificadas + posicoes_codificadas
return correcoes_codificadasImplementar autoatenção local
A equação de atenção regular é indicada abaixo.
atenção(Q,K,V) = softmax(QK^T/sqrt(dk))V
- O módulo de atenção recebe uma consulta, chave e valor.
- Primeiro, calculamos a semelhança entre a consulta e a chave por meio de um produto escalar.
- Em seguida, o resultado é dimensionado pela raiz quadrada da dimensão principal.
- A escala evita que a função softmax tenha um gradiente excessivamente pequeno.
- Softmax é então aplicado ao produto escalar escalado para produzir os pesos de atenção.
- O valor é então modulado através dos pesos de atenção.
Na autoatenção, consulta, chave e valor vêm da mesma entrada.
O produto escalar resultaria em grandes relações de auto-token, em vez de relações entre tokens.
Isso também significa que o softmax oferece probabilidades mais altas às relações auto-token do que às relações inter-token.
Para combater isso, os autores propõem mascarar a diagonal do produto escalar. Dessa forma, forçamos o módulo de atenção a prestar mais atenção às relações entre tokens.
O fator de escala é uma constante no módulo de atenção regular.
Isto atua como um 'termo de temperatura' que pode modular a função softmax.
Os autores sugerem um termo de temperatura que pode ser aprendido em vez de uma constante.

As duas dicas acima tornam-se a Autoatenção da Localidade.
Subclassificamos layers.MultiHeadAttention e implementamos a temperatura treinável.
A máscara de atenção é construída posteriormente.
class AtencaoMultiCabecaLSA(tf.keras.layers.MultiHeadAttention):
def __init__(self, **kwargs):
super().__init__(**kwargs)
# O termo de temperatura treinável. O valor inicial
# é a raiz quadrada da dimensão principal.
self.tau = tf.Variable(math.sqrt(float(self._key_dim)), trainable=True)
def _compute_attention(self, consulta, chave, valor, attention_mask=None, training=None):
consulta = tf.multiply(consulta, 1.0 / self.tau)
escores_atencao = tf.einsum(self._dot_product_equation, chave, consulta)
escores_atencao = self._masked_softmax(escores_atencao, attention_mask)
abandono_escores_atencao = self._dropout_layer(
escores_atencao, training=training
)
saida_atencao = tf.einsum(
self._combine_equation, abandono_escores_atencao, valor
)
return saida_atencao, escores_atencaoImplementar o MLP
Implemente o Perceptron Multi-Camadas (MLP - Multi-Layer Perceptron).
def mlp(x, unidades_escondidas, taxa_abandono):
for unidades in unidades_escondidas:
x = layers.Dense(unidades, activation=tf.nn.gelu)(x)
x = layers.Dropout(taxa_abandono)(x)
return x
# Construir a máscara de atenção diagonal
mascara_atencao_diagonal = 1 - tf.eye(NUM_CORRECOES)
mascara_atencao_diagonal = tf.cast([mascara_atencao_diagonal], dtype=tf.int8)Implementar o ViT
def criar_classificador_vit(vanilla=False):
entradas = layers.Input(shape=DIMENSOES_ENTRADA)
# Dados aumentados
aumentado = aumento_dados(entradas)
# Criar patches.
(tokens, _) = TokenizacaoCorrecaoDeslocamento(vanilla=vanilla)(aumentado)
# Codificar correções.
correcoes_codificadas = CodificadorCorrecao()(tokens)
# Crie múltiplas camadas do bloco Transformer.
for _ in range(CAMADAS_TRANFORMACAO):
# Normalização de camada 1
x1 = layers.LayerNormalization(epsilon=1e-6)(correcoes_codificadas)
# Crie uma camada de atenção com várias cabeças.
if not vanilla:
saida_atencao = AtencaoMultiCabecaLSA(
num_heads=NUM_CABECAS, key_dim=DIM_PROJECAO, dropout=0.1)(
x1, x1, attention_mask=mascara_atencao_diagonal)
else:
saida_atencao = layers.MultiHeadAttention(
num_heads=NUM_CABECAS, key_dim=DIM_PROJECAO, dropout=0.1)(
x1, x1)
# Pular conexão 1
x2 = layers.Add()([saida_atencao, correcoes_codificadas])
# Normalização de camada 2
x3 = layers.LayerNormalization(epsilon=1e-6)(x2)
# MLP - Multi-Layer Perceptron (Perceptron Multi-Camada)
x3 = mlp(x3, unidades_escondidas=UNIDADES_TRANSFORMADORAS, taxa_abandono=0.1)
# Pular conexão 2
correcoes_codificadas = layers.Add()([x3, x2])
# Crie um tensor [tamanho do lote, dimensão de projeção].
representacao = layers.LayerNormalization(epsilon=1e-6)(correcoes_codificadas)
representacao = layers.Flatten()(representacao)
representacao = layers.Dropout(0.5)(representacao)
# Adicionar MLP
caracteristicas = mlp(representacao, unidades_escondidas=UNIDADES_CABECA_MLP, taxa_abandono=0.5)
# Classificar as saídas.
saidas = layers.Dense(NUM_CLASSES)(caracteristicas)
# Criar o modelo Keras
modelo = keras.Model(entradas=entradas, outputs=saidas)
return modeloCompilar, treinar e avaliar o modelo
class coseno_aquecimento(keras.optimizers.schedules.LearningRateSchedule):
def __init__(
self, taxa_base_aprendizado, total_passos, taxa_aprendizado_aquecimento, passos_aquecimento
):
super().__init__()
self.taxa_base_aprendizado = taxa_base_aprendizado
self.total_passos = total_passos
self.taxa_aprendizado_aquecimento = taxa_aprendizado_aquecimento
self.passos_aquecimento = passos_aquecimento
self.pi = tf.constant(np.pi)
def __call__(self, step):
if self.total_passos < self.passos_aquecimento:
raise ValueError("Total_steps deve ser maior ou igual a passos_aquecimento.")
cos_lr_recozido = tf.cos(
self.pi
* (tf.cast(step, tf.float32) - self.passos_aquecimento)
/ float(self.total_passos - self.passos_aquecimento)
)
taxa_aprendizado = 0.5 * self.taxa_base_aprendizado * (1 + cos_lr_recozido)
if self.passos_aquecimento > 0:
if self.taxa_base_aprendizado < self.taxa_aprendizado_aquecimento:
raise ValueError(
"taxa_base_aprendizado deve ser maior ou igual a "
"taxa_aprendizado_aquecimento."
)
slope = (self.taxa_base_aprendizado - self.taxa_aprendizado_aquecimento) / self.passos_aquecimento
taxa_aquecimento = slope * tf.cast(step, tf.float32) + self.taxa_aprendizado_aquecimento
taxa_aprendizado = tf.where(step < self.passos_aquecimento, taxa_aquecimento, taxa_aprendizado)
return tf.where(step > self.total_passos, 0.0, taxa_aprendizado, name="learning_rate")A função executar_experimento() recebe um modelo e executa o treinamento.
def executar_experimento(modelo):
total_passos = int((len(dados_treino) / TAM_LOTE) * EPISODIOS)
percentagem_episodio_aquecimento = 0.10
passos_aquecimento = int(total_passos * percentagem_episodio_aquecimento)
scheduled_lrs = coseno_aquecimento(
learning_rate_base = TAXA_APRENDIZADO,
warmup_steps = total_passos,
warmup_learning_rate = 0.0,
warmup_steps = passos_aquecimento,
)
otimizador = tfa.optimizers.AdamW(
learning_rate = TAXA_APRENDIZADO,
weight_decay = PESO_DECAIMENTO
)
modelo.compile(
optimizer = otimizador,
loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics = [
keras.metrics.SparseCategoricalAccuracy(name="acuracia"),
keras.metrics.SparseTopKCategoricalAccuracy(5, name="acuracia-top-5"),
],
)
historia = modelo.fit(
x=dados_treino,
y=alvos_treino,
batch_size=TAM_LOTE,
epochs=EPISODIOS,
validation_split=0.1,
)
_, acuracia, acuracia_top_5 = modelo.evaluate(dados_teste, alvos_teste, batch_size=TAM_LOTE)
print(f"Acurácia do teste: {round(acuracia * 100, 2)}%")
print(f"Acurácia do teste top-5: {round(acuracia_top_5 * 100, 2)}%")
return historiaExecute experimentos com o ViT Vanilla
vit = criar_classificador_vit(vanilla=True)
historia = executar_experimento(vit)Epoch 1/50
176/176 [==============================] - 22s 83ms/step - loss: 4.4912 - acuracia: 0.0427 acuracia-top-5: 0.1549 - val_loss: 3.9409 - val_acuracia: 0.1030 - val_acuracia-top-5: 0.3036
Epoch 2/50
176/176 [==============================] - 14s 77ms/step - loss: 3.9749 - acuracia: 0.0897 acuracia-top-5: 0.2802 - val_loss: 3.5721 - val_acuracia: 0.1550 - val_acuracia-top-5: 0.4058
Epoch 3/50
176/176 [==============================] - 14s 77ms/step - loss: 3.7129 - acuracia: 0.1282 acuracia-top-5: 0.3601 - val_loss: 3.3235 - val_acuracia: 0.2022 - val_acuracia-top-5: 0.4788
Epoch 4/50
176/176 [==============================] - 14s 77ms/step - loss: 3.5518 - acuracia: 0.1544 acuracia-top-5: 0.4078 - val_loss: 3.2432 - val_acuracia: 0.2132 - val_acuracia-top-5: 0.5056
Epoch 5/50
176/176 [==============================] - 14s 77ms/step - loss: 3.4098 - acuracia: 0.1828 acuracia-top-5: 0.4471 - val_loss: 3.0910 - val_acuracia: 0.2462 - val_acuracia-top-5: 0.5376
Epoch 6/50
176/176 [==============================] - 14s 77ms/step - loss: 3.2835 - acuracia: 0.2037 acuracia-top-5: 0.4838 - val_loss: 2.9803 - val_acuracia: 0.2704 - val_acuracia-top-5: 0.5606
Epoch 7/50
176/176 [==============================] - 14s 77ms/step - loss: 3.1756 - acuracia: 0.2205 acuracia-top-5: 0.5113 - val_loss: 2.8608 - val_acuracia: 0.2802 - val_acuracia-top-5: 0.5908
Epoch 8/50
176/176 [==============================] - 14s 77ms/step - loss: 3.0585 - acuracia: 0.2439 acuracia-top-5: 0.5432 - val_loss: 2.8055 - val_acuracia: 0.2960 - val_acuracia-top-5: 0.6144
Epoch 9/50
176/176 [==============================] - 14s 77ms/step - loss: 2.9457 - acuracia: 0.2654 acuracia-top-5: 0.5697 - val_loss: 2.7034 - val_acuracia: 0.3210 - val_acuracia-top-5: 0.6242
Epoch 10/50
176/176 [==============================] - 14s 77ms/step - loss: 2.8458 - acuracia: 0.2863 acuracia-top-5: 0.5918 - val_loss: 2.5899 - val_acuracia: 0.3416 - val_acuracia-top-5: 0.6500
Epoch 11/50
176/176 [==============================] - 14s 77ms/step - loss: 2.7530 - acuracia: 0.3052 acuracia-top-5: 0.6191 - val_loss: 2.5275 - val_acuracia: 0.3526 - val_acuracia-top-5: 0.6660
Epoch 12/50
176/176 [==============================] - 14s 77ms/step - loss: 2.6561 - acuracia: 0.3250 acuracia-top-5: 0.6355 - val_loss: 2.5111 - val_acuracia: 0.3544 - val_acuracia-top-5: 0.6554
Epoch 13/50
176/176 [==============================] - 14s 77ms/step - loss: 2.5833 - acuracia: 0.3398 acuracia-top-5: 0.6538 - val_loss: 2.3931 - val_acuracia: 0.3792 - val_acuracia-top-5: 0.6888
Epoch 14/50
176/176 [==============================] - 14s 77ms/step - loss: 2.4988 - acuracia: 0.3594 acuracia-top-5: 0.6724 - val_loss: 2.3695 - val_acuracia: 0.3868 - val_acuracia-top-5: 0.6958
Epoch 15/50
176/176 [==============================] - 14s 77ms/step - loss: 2.4342 - acuracia: 0.3706 acuracia-top-5: 0.6877 - val_loss: 2.3076 - val_acuracia: 0.4072 - val_acuracia-top-5: 0.7074
Epoch 16/50
176/176 [==============================] - 14s 77ms/step - loss: 2.3654 - acuracia: 0.3841 acuracia-top-5: 0.7024 - val_loss: 2.2346 - val_acuracia: 0.4202 - val_acuracia-top-5: 0.7174
Epoch 17/50
176/176 [==============================] - 14s 77ms/step - loss: 2.3062 - acuracia: 0.3967 acuracia-top-5: 0.7130 - val_loss: 2.2277 - val_acuracia: 0.4206 - val_acuracia-top-5: 0.7190
Epoch 18/50
176/176 [==============================] - 14s 77ms/step - loss: 2.2415 - acuracia: 0.4100 acuracia-top-5: 0.7271 - val_loss: 2.1605 - val_acuracia: 0.4398 - val_acuracia-top-5: 0.7366
Epoch 19/50
176/176 [==============================] - 14s 77ms/step - loss: 2.1802 - acuracia: 0.4240 acuracia-top-5: 0.7386 - val_loss: 2.1533 - val_acuracia: 0.4428 - val_acuracia-top-5: 0.7382
Epoch 20/50
176/176 [==============================] - 14s 77ms/step - loss: 2.1264 - acuracia: 0.4357 acuracia-top-5: 0.7486 - val_loss: 2.1395 - val_acuracia: 0.4428 - val_acuracia-top-5: 0.7404
Epoch 21/50
176/176 [==============================] - 14s 77ms/step - loss: 2.0856 - acuracia: 0.4442 acuracia-top-5: 0.7564 - val_loss: 2.1025 - val_acuracia: 0.4512 - val_acuracia-top-5: 0.7448
Epoch 22/50
176/176 [==============================] - 14s 77ms/step - loss: 2.0320 - acuracia: 0.4566 acuracia-top-5: 0.7668 - val_loss: 2.0677 - val_acuracia: 0.4600 - val_acuracia-top-5: 0.7534
Epoch 23/50
176/176 [==============================] - 14s 77ms/step - loss: 1.9903 - acuracia: 0.4666 acuracia-top-5: 0.7761 - val_loss: 2.0273 - val_acuracia: 0.4650 - val_acuracia-top-5: 0.7610
Epoch 24/50
176/176 [==============================] - 14s 77ms/step - loss: 1.9398 - acuracia: 0.4772 acuracia-top-5: 0.7877 - val_loss: 2.0253 - val_acuracia: 0.4694 - val_acuracia-top-5: 0.7636
Epoch 25/50
176/176 [==============================] - 14s 78ms/step - loss: 1.9027 - acuracia: 0.4865 acuracia-top-5: 0.7933 - val_loss: 2.0584 - val_acuracia: 0.4606 - val_acuracia-top-5: 0.7520
Epoch 26/50
176/176 [==============================] - 14s 77ms/step - loss: 1.8529 - acuracia: 0.4964 acuracia-top-5: 0.8010 - val_loss: 2.0128 - val_acuracia: 0.4752 - val_acuracia-top-5: 0.7654
Epoch 27/50
176/176 [==============================] - 14s 77ms/step - loss: 1.8161 - acuracia: 0.5047 acuracia-top-5: 0.8111 - val_loss: 1.9630 - val_acuracia: 0.4898 - val_acuracia-top-5: 0.7746
Epoch 28/50
176/176 [==============================] - 13s 77ms/step - loss: 1.7792 - acuracia: 0.5136 acuracia-top-5: 0.8140 - val_loss: 1.9931 - val_acuracia: 0.4780 - val_acuracia-top-5: 0.7640
Epoch 29/50
176/176 [==============================] - 14s 77ms/step - loss: 1.7268 - acuracia: 0.5211 acuracia-top-5: 0.8250 - val_loss: 1.9748 - val_acuracia: 0.4854 - val_acuracia-top-5: 0.7708
Epoch 30/50
176/176 [==============================] - 14s 77ms/step - loss: 1.7115 - acuracia: 0.5298 acuracia-top-5: 0.8265 - val_loss: 1.9669 - val_acuracia: 0.4884 - val_acuracia-top-5: 0.7796
Epoch 31/50
176/176 [==============================] - 14s 77ms/step - loss: 1.6795 - acuracia: 0.5361 acuracia-top-5: 0.8329 - val_loss: 1.9428 - val_acuracia: 0.4972 - val_acuracia-top-5: 0.7852
Epoch 32/50
176/176 [==============================] - 14s 77ms/step - loss: 1.6411 - acuracia: 0.5448 acuracia-top-5: 0.8412 - val_loss: 1.9318 - val_acuracia: 0.4952 - val_acuracia-top-5: 0.7864
Epoch 33/50
176/176 [==============================] - 14s 77ms/step - loss: 1.6015 - acuracia: 0.5547 acuracia-top-5: 0.8466 - val_loss: 1.9233 - val_acuracia: 0.4996 - val_acuracia-top-5: 0.7882
Epoch 34/50
176/176 [==============================] - 14s 77ms/step - loss: 1.5651 - acuracia: 0.5655 acuracia-top-5: 0.8525 - val_loss: 1.9285 - val_acuracia: 0.5082 - val_acuracia-top-5: 0.7888
Epoch 35/50
176/176 [==============================] - 14s 77ms/step - loss: 1.5437 - acuracia: 0.5672 acuracia-top-5: 0.8570 - val_loss: 1.9268 - val_acuracia: 0.5028 - val_acuracia-top-5: 0.7842
Epoch 36/50
176/176 [==============================] - 14s 77ms/step - loss: 1.5103 - acuracia: 0.5748 acuracia-top-5: 0.8620 - val_loss: 1.9262 - val_acuracia: 0.5014 - val_acuracia-top-5: 0.7890
Epoch 37/50
176/176 [==============================] - 14s 77ms/step - loss: 1.4784 - acuracia: 0.5822 acuracia-top-5: 0.8690 - val_loss: 1.8698 - val_acuracia: 0.5130 - val_acuracia-top-5: 0.7948
Epoch 38/50
176/176 [==============================] - 14s 77ms/step - loss: 1.4449 - acuracia: 0.5922 acuracia-top-5: 0.8728 - val_loss: 1.8734 - val_acuracia: 0.5136 - val_acuracia-top-5: 0.7980
Epoch 39/50
176/176 [==============================] - 14s 77ms/step - loss: 1.4312 - acuracia: 0.5928 acuracia-top-5: 0.8755 - val_loss: 1.8736 - val_acuracia: 0.5150 - val_acuracia-top-5: 0.7956
Epoch 40/50
176/176 [==============================] - 14s 77ms/step - loss: 1.3996 - acuracia: 0.5999 acuracia-top-5: 0.8808 - val_loss: 1.8718 - val_acuracia: 0.5178 - val_acuracia-top-5: 0.7970
Epoch 41/50
176/176 [==============================] - 14s 77ms/step - loss: 1.3859 - acuracia: 0.6075 acuracia-top-5: 0.8817 - val_loss: 1.9097 - val_acuracia: 0.5084 - val_acuracia-top-5: 0.7884
Epoch 42/50
176/176 [==============================] - 14s 77ms/step - loss: 1.3586 - acuracia: 0.6119 acuracia-top-5: 0.8860 - val_loss: 1.8620 - val_acuracia: 0.5148 - val_acuracia-top-5: 0.8010
Epoch 43/50
176/176 [==============================] - 14s 77ms/step - loss: 1.3384 - acuracia: 0.6154 acuracia-top-5: 0.8911 - val_loss: 1.8509 - val_acuracia: 0.5202 - val_acuracia-top-5: 0.8014
Epoch 44/50
176/176 [==============================] - 14s 78ms/step - loss: 1.3090 - acuracia: 0.6236 acuracia-top-5: 0.8954 - val_loss: 1.8607 - val_acuracia: 0.5242 - val_acuracia-top-5: 0.8020
Epoch 45/50
176/176 [==============================] - 14s 78ms/step - loss: 1.2873 - acuracia: 0.6292 acuracia-top-5: 0.8964 - val_loss: 1.8729 - val_acuracia: 0.5208 - val_acuracia-top-5: 0.8056
Epoch 46/50
176/176 [==============================] - 14s 77ms/step - loss: 1.2658 - acuracia: 0.6367 acuracia-top-5: 0.9007 - val_loss: 1.8573 - val_acuracia: 0.5278 - val_acuracia-top-5: 0.8066
Epoch 47/50
176/176 [==============================] - 14s 77ms/step - loss: 1.2628 - acuracia: 0.6346 acuracia-top-5: 0.9023 - val_loss: 1.8240 - val_acuracia: 0.5292 - val_acuracia-top-5: 0.8112
Epoch 48/50
176/176 [==============================] - 14s 78ms/step - loss: 1.2396 - acuracia: 0.6431 acuracia-top-5: 0.9057 - val_loss: 1.8342 - val_acuracia: 0.5362 - val_acuracia-top-5: 0.8096
Epoch 49/50
176/176 [==============================] - 14s 77ms/step - loss: 1.2163 - acuracia: 0.6464 acuracia-top-5: 0.9081 - val_loss: 1.8836 - val_acuracia: 0.5246 - val_acuracia-top-5: 0.8044
Epoch 50/50
176/176 [==============================] - 14s 77ms/step - loss: 1.1919 - acuracia: 0.6541 acuracia-top-5: 0.9122 - val_loss: 1.8513 - val_acuracia: 0.5336 - val_acuracia-top-5: 0.8048
40/40 [==============================] - 1s 26ms/step - loss: 1.8172 - acuracia: 0.5310 acuracia-top-5: 0.8053
Acurácia do teste: 53.1%
Acurácia do teste top-5: 80.53%Execute experimentos com Tokenização de Patchs por Deslocamento (SPT - Shifted Patch Tokenization) e autoatenção de localidade modificada ViT.
vit_sl = criar_classificador_vit(vanilla=False)
historia = executar_experimento(vit_sl)Epoch 1/50
176/176 [==============================] - 23s 90ms/step - loss: 4.4889 - acuracia: 0.0450 acuracia-top-5: 0.1559 - val_loss: 3.9364 - val_acuracia: 0.1128 - val_acuracia-top-5: 0.3184
Epoch 2/50
176/176 [==============================] - 15s 85ms/step - loss: 3.9806 - acuracia: 0.0924 acuracia-top-5: 0.2798 - val_loss: 3.6392 - val_acuracia: 0.1576 - val_acuracia-top-5: 0.4034
Epoch 3/50
176/176 [==============================] - 15s 84ms/step - loss: 3.7713 - acuracia: 0.1253 acuracia-top-5: 0.3448 - val_loss: 3.3892 - val_acuracia: 0.1918 - val_acuracia-top-5: 0.4622
Epoch 4/50
176/176 [==============================] - 15s 85ms/step - loss: 3.6297 - acuracia: 0.1460 acuracia-top-5: 0.3859 - val_loss: 3.2856 - val_acuracia: 0.2194 - val_acuracia-top-5: 0.4970
Epoch 5/50
176/176 [==============================] - 15s 85ms/step - loss: 3.4955 - acuracia: 0.1706 acuracia-top-5: 0.4239 - val_loss: 3.1359 - val_acuracia: 0.2412 - val_acuracia-top-5: 0.5308
Epoch 6/50
176/176 [==============================] - 15s 85ms/step - loss: 3.3781 - acuracia: 0.1908 acuracia-top-5: 0.4565 - val_loss: 3.0535 - val_acuracia: 0.2620 - val_acuracia-top-5: 0.5652
Epoch 7/50
176/176 [==============================] - 15s 85ms/step - loss: 3.2540 - acuracia: 0.2123 acuracia-top-5: 0.4895 - val_loss: 2.9165 - val_acuracia: 0.2782 - val_acuracia-top-5: 0.5800
Epoch 8/50
176/176 [==============================] - 15s 85ms/step - loss: 3.1442 - acuracia: 0.2318 acuracia-top-5: 0.5197 - val_loss: 2.8592 - val_acuracia: 0.2984 - val_acuracia-top-5: 0.6090
Epoch 9/50
176/176 [==============================] - 15s 85ms/step - loss: 3.0348 - acuracia: 0.2504 acuracia-top-5: 0.5440 - val_loss: 2.7378 - val_acuracia: 0.3146 - val_acuracia-top-5: 0.6294
Epoch 10/50
176/176 [==============================] - 15s 84ms/step - loss: 2.9311 - acuracia: 0.2681 acuracia-top-5: 0.5704 - val_loss: 2.6274 - val_acuracia: 0.3362 - val_acuracia-top-5: 0.6446
Epoch 11/50
176/176 [==============================] - 15s 85ms/step - loss: 2.8214 - acuracia: 0.2925 acuracia-top-5: 0.5986 - val_loss: 2.5557 - val_acuracia: 0.3458 - val_acuracia-top-5: 0.6616
Epoch 12/50
176/176 [==============================] - 15s 85ms/step - loss: 2.7244 - acuracia: 0.3100 acuracia-top-5: 0.6168 - val_loss: 2.4763 - val_acuracia: 0.3564 - val_acuracia-top-5: 0.6804
Epoch 13/50
176/176 [==============================] - 15s 85ms/step - loss: 2.6476 - acuracia: 0.3255 acuracia-top-5: 0.6358 - val_loss: 2.3946 - val_acuracia: 0.3678 - val_acuracia-top-5: 0.6940
Epoch 14/50
176/176 [==============================] - 15s 85ms/step - loss: 2.5518 - acuracia: 0.3436 acuracia-top-5: 0.6584 - val_loss: 2.3362 - val_acuracia: 0.3856 - val_acuracia-top-5: 0.7038
Epoch 15/50
176/176 [==============================] - 15s 85ms/step - loss: 2.4620 - acuracia: 0.3632 acuracia-top-5: 0.6776 - val_loss: 2.2690 - val_acuracia: 0.4006 - val_acuracia-top-5: 0.7222
Epoch 16/50
176/176 [==============================] - 15s 85ms/step - loss: 2.4010 - acuracia: 0.3749 acuracia-top-5: 0.6908 - val_loss: 2.1937 - val_acuracia: 0.4216 - val_acuracia-top-5: 0.7338
Epoch 17/50
176/176 [==============================] - 15s 85ms/step - loss: 2.3330 - acuracia: 0.3911 acuracia-top-5: 0.7041 - val_loss: 2.1519 - val_acuracia: 0.4286 - val_acuracia-top-5: 0.7370
Epoch 18/50
176/176 [==============================] - 15s 85ms/step - loss: 2.2600 - acuracia: 0.4069 acuracia-top-5: 0.7171 - val_loss: 2.1212 - val_acuracia: 0.4356 - val_acuracia-top-5: 0.7460
Epoch 19/50
176/176 [==============================] - 15s 85ms/step - loss: 2.1967 - acuracia: 0.4169 acuracia-top-5: 0.7320 - val_loss: 2.0748 - val_acuracia: 0.4470 - val_acuracia-top-5: 0.7580
Epoch 20/50
176/176 [==============================] - 15s 85ms/step - loss: 2.1397 - acuracia: 0.4302 acuracia-top-5: 0.7450 - val_loss: 2.1152 - val_acuracia: 0.4362 - val_acuracia-top-5: 0.7416
Epoch 21/50
176/176 [==============================] - 15s 85ms/step - loss: 2.0929 - acuracia: 0.4396 acuracia-top-5: 0.7524 - val_loss: 2.0044 - val_acuracia: 0.4652 - val_acuracia-top-5: 0.7680
Epoch 22/50
176/176 [==============================] - 15s 85ms/step - loss: 2.0423 - acuracia: 0.4521 acuracia-top-5: 0.7639 - val_loss: 2.0628 - val_acuracia: 0.4488 - val_acuracia-top-5: 0.7544
Epoch 23/50
176/176 [==============================] - 15s 85ms/step - loss: 1.9771 - acuracia: 0.4661 acuracia-top-5: 0.7750 - val_loss: 1.9380 - val_acuracia: 0.4740 - val_acuracia-top-5: 0.7836
Epoch 24/50
176/176 [==============================] - 15s 84ms/step - loss: 1.9323 - acuracia: 0.4752 acuracia-top-5: 0.7848 - val_loss: 1.9461 - val_acuracia: 0.4732 - val_acuracia-top-5: 0.7768
Epoch 25/50
176/176 [==============================] - 15s 85ms/step - loss: 1.8913 - acuracia: 0.4844 acuracia-top-5: 0.7914 - val_loss: 1.9230 - val_acuracia: 0.4768 - val_acuracia-top-5: 0.7886
Epoch 26/50
176/176 [==============================] - 15s 84ms/step - loss: 1.8520 - acuracia: 0.4950 acuracia-top-5: 0.7999 - val_loss: 1.9159 - val_acuracia: 0.4808 - val_acuracia-top-5: 0.7900
Epoch 27/50
176/176 [==============================] - 15s 85ms/step - loss: 1.8175 - acuracia: 0.5046 acuracia-top-5: 0.8076 - val_loss: 1.8977 - val_acuracia: 0.4896 - val_acuracia-top-5: 0.7876
Epoch 28/50
176/176 [==============================] - 15s 85ms/step - loss: 1.7692 - acuracia: 0.5133 acuracia-top-5: 0.8146 - val_loss: 1.8632 - val_acuracia: 0.4940 - val_acuracia-top-5: 0.7920
Epoch 29/50
176/176 [==============================] - 15s 85ms/step - loss: 1.7375 - acuracia: 0.5193 acuracia-top-5: 0.8206 - val_loss: 1.8686 - val_acuracia: 0.4926 - val_acuracia-top-5: 0.7952
Epoch 30/50
176/176 [==============================] - 15s 85ms/step - loss: 1.6952 - acuracia: 0.5308 acuracia-top-5: 0.8280 - val_loss: 1.8265 - val_acuracia: 0.5024 - val_acuracia-top-5: 0.7996
Epoch 31/50
176/176 [==============================] - 15s 85ms/step - loss: 1.6631 - acuracia: 0.5379 acuracia-top-5: 0.8348 - val_loss: 1.8665 - val_acuracia: 0.4942 - val_acuracia-top-5: 0.7854
Epoch 32/50
176/176 [==============================] - 15s 85ms/step - loss: 1.6329 - acuracia: 0.5466 acuracia-top-5: 0.8401 - val_loss: 1.8364 - val_acuracia: 0.5090 - val_acuracia-top-5: 0.7996
Epoch 33/50
176/176 [==============================] - 15s 85ms/step - loss: 1.5960 - acuracia: 0.5537 acuracia-top-5: 0.8465 - val_loss: 1.8171 - val_acuracia: 0.5136 - val_acuracia-top-5: 0.8034
Epoch 34/50
176/176 [==============================] - 15s 85ms/step - loss: 1.5815 - acuracia: 0.5578 acuracia-top-5: 0.8476 - val_loss: 1.8020 - val_acuracia: 0.5128 - val_acuracia-top-5: 0.8042
Epoch 35/50
176/176 [==============================] - 15s 85ms/step - loss: 1.5432 - acuracia: 0.5667 acuracia-top-5: 0.8566 - val_loss: 1.8173 - val_acuracia: 0.5142 - val_acuracia-top-5: 0.8080
Epoch 36/50
176/176 [==============================] - 15s 85ms/step - loss: 1.5110 - acuracia: 0.5768 acuracia-top-5: 0.8594 - val_loss: 1.8168 - val_acuracia: 0.5124 - val_acuracia-top-5: 0.8066
Epoch 37/50
176/176 [==============================] - 15s 85ms/step - loss: 1.4890 - acuracia: 0.5816 acuracia-top-5: 0.8641 - val_loss: 1.7861 - val_acuracia: 0.5274 - val_acuracia-top-5: 0.8120
Epoch 38/50
176/176 [==============================] - 15s 85ms/step - loss: 1.4672 - acuracia: 0.5849 acuracia-top-5: 0.8660 - val_loss: 1.7695 - val_acuracia: 0.5222 - val_acuracia-top-5: 0.8106
Epoch 39/50
176/176 [==============================] - 15s 85ms/step - loss: 1.4323 - acuracia: 0.5939 acuracia-top-5: 0.8721 - val_loss: 1.7653 - val_acuracia: 0.5250 - val_acuracia-top-5: 0.8164
Epoch 40/50
176/176 [==============================] - 15s 85ms/step - loss: 1.4192 - acuracia: 0.5975 acuracia-top-5: 0.8754 - val_loss: 1.7727 - val_acuracia: 0.5298 - val_acuracia-top-5: 0.8154
Epoch 41/50
176/176 [==============================] - 15s 85ms/step - loss: 1.3897 - acuracia: 0.6055 acuracia-top-5: 0.8805 - val_loss: 1.7535 - val_acuracia: 0.5328 - val_acuracia-top-5: 0.8122
Epoch 42/50
176/176 [==============================] - 15s 85ms/step - loss: 1.3702 - acuracia: 0.6087 acuracia-top-5: 0.8828 - val_loss: 1.7746 - val_acuracia: 0.5316 - val_acuracia-top-5: 0.8116
Epoch 43/50
176/176 [==============================] - 15s 85ms/step - loss: 1.3338 - acuracia: 0.6185 acuracia-top-5: 0.8894 - val_loss: 1.7606 - val_acuracia: 0.5342 - val_acuracia-top-5: 0.8176
Epoch 44/50
176/176 [==============================] - 15s 85ms/step - loss: 1.3171 - acuracia: 0.6200 acuracia-top-5: 0.8920 - val_loss: 1.7490 - val_acuracia: 0.5364 - val_acuracia-top-5: 0.8164
Epoch 45/50
176/176 [==============================] - 15s 85ms/step - loss: 1.3056 - acuracia: 0.6276 acuracia-top-5: 0.8932 - val_loss: 1.7535 - val_acuracia: 0.5388 - val_acuracia-top-5: 0.8156
Epoch 46/50
176/176 [==============================] - 15s 85ms/step - loss: 1.2876 - acuracia: 0.6289 acuracia-top-5: 0.8952 - val_loss: 1.7546 - val_acuracia: 0.5320 - val_acuracia-top-5: 0.8154
Epoch 47/50
176/176 [==============================] - 15s 85ms/step - loss: 1.2764 - acuracia: 0.6350 acuracia-top-5: 0.8970 - val_loss: 1.7177 - val_acuracia: 0.5382 - val_acuracia-top-5: 0.8200
Epoch 48/50
176/176 [==============================] - 15s 85ms/step - loss: 1.2543 - acuracia: 0.6407 acuracia-top-5: 0.9001 - val_loss: 1.7330 - val_acuracia: 0.5438 - val_acuracia-top-5: 0.8198
Epoch 49/50
176/176 [==============================] - 15s 84ms/step - loss: 1.2191 - acuracia: 0.6470 acuracia-top-5: 0.9042 - val_loss: 1.7316 - val_acuracia: 0.5436 - val_acuracia-top-5: 0.8196
Epoch 50/50
176/176 [==============================] - 15s 85ms/step - loss: 1.2186 - acuracia: 0.6457 acuracia-top-5: 0.9066 - val_loss: 1.7201 - val_acuracia: 0.5486 - val_acuracia-top-5: 0.8218
40/40 [==============================] - 1s 30ms/step - loss: 1.6760 - acuracia: 0.5611 acuracia-top-5: 0.8227
Acurácia do teste: 56.11%
Acurácia do teste top-5: 82.27%Notas Finais
Com a ajuda de Shifted Patch Tokenization e Locality Self Attention, obtivemos um modelo de 65% de acurácia no CIFAR100.
As ideias sobre estas técnicas são muito intuitivas e fáceis de implementar.
Os autores também abordam diferentes estratégias de mudança para SPT no suplemento do artigo.
Foi utilizada a plataforma de GPUs de Jarvislabs.ai para aceleração do algorítmo.
13.8.4 - Classificar Dígitos
13.9 - Projeto Avançado


