12 - Aprendizado por Reforço
O Aprendizado por Reforço (RL - Reinforcement Learning) é um tipo de aprendizado de máquina (ML) em que o agente (modelo) aprende a tomar melhores decisões em um ambiente ao longo do tempo, sendo recompensado por suas ações.
O agente é colocado no ambiente e recebe uma série de ações que pode realizar, tentando então escolher as ações que o levem a receber a maior recompensa, aprendendo com suas escolhas e com as recompensas que recebe, sendo eventualmente capaz de tomar melhores decisões.
O RL é um dos tipos mais importantes de ML, uma ferramenta poderosa que pode ser usada para aprender a tomar decisões em ambientes complexos e resolver uma ampla variedade de problemas em diferentes áreas, como jogos, robótica e finanças.
No RL, o objetivo é desenvolver um sistema (agente) que melhore seu desempenho com base nas interações com o ambiente.
Uma vez que a informação sobre o estado atual do ambiente normalmente também inclui o chamado sinal de recompensa, podemos pensar na aprendizagem por reforço como um campo relacionado à aprendizagem supervisionada.
No entanto, na aprendizagem por reforço, esse feedback não é o rótulo ou valor correto da verdade básica, mas uma medida de quão bem a ação foi medida por uma função de recompensa.
Através de sua interação com o ambiente, um agente pode então usar o aprendizado por reforço para aprender uma série de ações que maximizam essa recompensa por meio de uma abordagem exploratória de tentativa e erro ou planejamento deliberativo.
Aqui estão alguns exemplos de como o RL pode ser aplicado ao ML:
- Jogos: Ensinar um agente a jogar jogos, como o xadrez, o Go ou o Dota 2.
- Robótica: Ensinar e treinar robôs a realizar tarefas complexas em ambientes desafiadores, como andar, pegar objetos ou jogar esportes.
- Finanças: Usado na tomada de decisões financeiras, como investir e administrar carteiras de investimentos em ações, títulos ou moedas estrangeiras.
- Medicina: Usado para desenvolver novos tratamentos médicos, diagnosticar doenças e tomar outras decisões clínicas.
- Transporte: Usado para melhorar o fluxo de tráfego, desenvolver novos sistemas de transporte e tomar outras decisões de transporte.
RL é um processo de duas etapas:
- Exploração: O agente explora o ambiente, tentando diferentes ações e observando os resultados.
- Aproveitamento: O agente aprende com suas experiências e começa a tomar decisões que maximizam suas recompensas.
O desempenho do agente é avaliado comparando as recompensas que ele recebe com as recompensas que ele receberia se soubesse o melhor curso de ação.
É importante observar que o RL pode ser muito lento e pode exigir um grande número de interações com o ambiente.
Os principais tipos de RL são:
- Baseado em Valor: O aprendizado por reforço valor-baseado é um tipo de RL em que o agente aprende a avaliar o valor de diferentes estados do ambiente. O agente usa então essas avaliações para escolher as ações que o levam a estados de maior valor.
- Baseado em Política: O aprendizado por reforço política-baseado é um tipo de RL em que o agente aprende uma política, que é uma função que mapeia estados do ambiente em ações. O agente usa então essa política para escolher as ações que o levam a estados de maior valor.
- Baseado em Gradiente de Política:: O aprendizado por política-gradiente aprende a gerar uma política ótima, que mapeia estados do ambiente em ações. O agente usa então essa política para escolher as ações que o levam a estados de maior valor.
- Q-learning: O Q-learning é um algoritmo de aprendizado por reforço valor-baseado que aprende a avaliar o valor de cada estado, de diferentes pares estado-ação. O Q-learning é um algoritmo poderoso que pode ser usado para resolver uma ampla variedade de problemas de RL.
- SARSA: O SARSA é um algoritmo de aprendizado por reforço política-baseado que aprende uma política que mapeia estados do ambiente em ações. O SARSA é um algoritmo poderoso que pode ser usado para resolver uma ampla variedade de problemas de RL.
- Diferença temporal: (Temporal-difference learning) : O aprendizado temporal-diferença aprende a estimar o valor de cada estado com base em observações passadas.
Estes são apenas alguns dos muitos tipos de RL.
Aqui estão as etapas para aplicar o RL para o ML:
- Defina o Problema: O primeiro passo é definir o problema que você deseja resolver com o RL. Você precisa identificar o ambiente, o agente e as ações que o agente pode realizar.
- Selecione o Algoritmo: Existem muitos algoritmos diferentes de RL disponíveis, então você precisa selecionar um que seja adequado para o seu problema. Você precisa considerar o tamanho do espaço de estados, o número de ações possíveis e o grau de incerteza no ambiente.
- Implemente o Algoritmo: Depois de selecionar um algoritmo, você precisa implementá-lo. Isso pode ser feito usando uma biblioteca de ML ou escrevendo seu próprio código.
- Treine o Agente: O agente precisa ser treinado para aprender a tomar as melhores decisões. Isso pode ser feito fornecendo ao agente um conjunto de dados de exemplos ou permitindo que ele explore o ambiente por conta própria.
- Teste o Agente: Depois que o agente for treinado, você precisa testá-lo para ver se ele pode tomar as melhores decisões em um ambiente novo.
- Implemente o Agente: Depois que o agente for testado e for satisfatório, você pode implementá-lo em um ambiente real.
O RL é um campo ativo de pesquisa e os pesquisadores estão constantemente desenvolvendo novos métodos de RL.
À medida que o campo de ML continuar a evoluir, o RL desempenhará um papel cada vez mais importante na solução dos problemas mais desafiadores do mundo.
12.1 - Exemplo: Jogo CartPole
12.2 - Projeto Avançado: Blackjac com Q-Learning
Neste tutorial, exploraremos e resolveremos o ambiente Blackjack-v1 do framework OpenAI Gym.
O Blackjack é um dos jogos de cartas de cassino mais populares, que também é famoso por ser vencível sob certas condições.
Esta versão do jogo usa um baralho infinito (tiramos as cartas com reposição), então contar cartas não será uma estratégia viável em nosso jogo simulado.
A documentação completa pode ser encontrada em https://gymnasium.farama.org/environments/toy_text/blackjack
- Objetivo: Para ganhar, a soma da sua carta deve ser maior que a do dealer sem ultrapassar 21.
- Ações: os agentes podem escolher entre duas ações:
- stand (0): o jogador não pega mais cartas
- hit (1): o jogador receberá outra carta, porém o jogador pode ultrapassar 21 e estourar
- Abordagem: Para resolver esse ambiente sozinho, você pode escolher seu algoritmo RL discreto favorito. A solução apresentada usa Q-learning (um algoritmo RL sem modelo).
Importação de bibliotecas e frameworks
from __future__ import annotations
import gym
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
from collections import defaultdict
from tqdm import tqdmCriação do ambiente
Vamos começar criando o ambiente de blackjack, seguindo as regras de Sutton & Barto.
env = gym.make('Blackjack-v1', sab=True)Outras versões do jogo podem ser encontradas abaixo para você experimentar.
Outras possíveis configurações de ambiente são:
env = gym.make('Blackjack-v1', natural=True, sab=False)Se deve dar uma recompensa adicional por começar com um blackjack natural, ou seja, começar com um ás e dez (a soma é 21).
env = gym.make('Blackjack-v1', natural=False, sab=False)As regras exatas descritas no livro de Sutton e Barto devem ser seguidas. Se `sab` for `True`, o argumento de palavra-chave `natural` será ignorado.
Inicialização do ambiente
Em primeiro lugar, iniciamos um episódio com a função env.reset(), redefinindo o ambiente para uma posição inicial e retornando um arquivo de observacao.
A variável feito será útil posteriormente para verificação se um jogo foi encerrado (ou seja, se o jogador ganhou ou perdeu).
Iniciamos o ambiente para obter e imprimir a primeira observação.
feito = False
observacao, info = env.reset()
print(observacao)A observação é uma tupla com 3 valores:
- A soma atual dos jogadores
- Valor da carta virada para cima do dealer
- Booleano se o jogador possui um ás utilizável (Um ás é utilizável se contar como 11 sem rebentar)
Executar uma ação
Depois de receber nossa primeira observação, vamos usar a função env.step() apenas para interagir com o ambiente. Esta função recebe uma ação como entrada e a executa no ambiente.
Como essa ação altera o estado do ambiente, ela nos retorna quatro variáveis úteis:
- proximo_estado: é a observação que o agente receberá após realizar a ação.
- recompensa: é a recompensa que o agente receberá após realizar a ação.
- terminou: Esta é uma variável booleana que indica se o ambiente foi finalizado ou não.
- truncou: Esta é uma variável booleana que também indica se o episódio terminou por truncamento precoce, ou seja, um limite de tempo foi atingido.
- info: Este é um dicionário que pode conter informações adicionais sobre o ambiente.
As variáveis proximo_estado, recompensa, terminou e truncou são autoexplicativas, mas a variável info requer alguma explicação adicional. Esta variável contém um dicionário que pode ter algumas informações extras sobre o ambiente, mas no ambiente Blackjack-v1 você pode ignorá-lo. Por exemplo, em ambientes Atari, o dicionário de informações possui uma chave que nos diz quantas vidas o agente ainda possui. Se o agente tiver 0 vidas, o episódio acabou.
Observe que não é uma boa ideia chamar env.render() seu laço de treinamento porque a renderização retarda muito o treinamento. Em vez disso, tente criar um laço extra para avaliar e mostrar o agente após o treinamento.
# Amostrar uma ação aleatória entre todas e exibir a ação
acao = env.action_space.sample()
print("Ação: ",acao)
# executar a ação no ambiente, receber e exibir as informações
observacao, recompensa, terminou, truncou, info = env.step(bool(acao))
print("Observação: ",observacao)
print("Recompensa: ",recompensa)
print("Terminou: ",terminou)
print("Truncou: ",truncou)
print("Info: ",info)Uma vez que terminou = True ou truncou = True, devemos parar o episódio atual e começar um novo com env.reset(). Se você continuar executando ações sem redefinir o ambiente, ele ainda responderá, mas a saída não será útil para o treinamento (pode até ser prejudicial se o agente aprender com dados inválidos).
Construir o agente
Vamos construir um agente Q-learning para resolver o Blackjack-v1!
Vamos precisar de algumas funções para escolher uma ação e atualizar os valores de ação dos agentes. Para garantir que os agentes explorem o ambiente, uma solução possível é a estratégia epsilon-greedy, onde escolhemos uma ação aleatória com a porcentagem epsilon e a ação avida (ou gulosa) 1 - epsilon (atualmente avaliada como a melhor).
Primeiro declaramos a classeAgenteBlackjack com os métodos __init__, buscar_acao, alterar_valores_q_acao e reduzir_epsilon.
class AgenteBlackjack:
def __init__(
self, taxa_aprendizado: float,
epsilon_inicial: float, epsilon_reducao: float,
epsilon_final: float, fator_desconto: float = 0.95):
""" Inicialize um agente RL com um dicionário vazio de valores Q de
valores de ação de estado (valores_q), uma taxa de aprendizado e um epsilon."""
""" Args:
taxa_aprendizado: A taxa de aprendizado
epsilon_inicial: O valor inicial de epsilon
epsilon_reducao: A taxa de redução de epsilon
epsilon_final: A taxa final de epsilon
fator_desconto: O fator de desconto para o valor de computação de Q-Learning
"""
self.valores_q = defaultdict(lambda: np.zeros(env.action_space.n))
self.taxa_aprendizado = taxa_aprendizado
self.fator_desconto = fator_desconto
self.epsilon = epsilon_inicial
self.epsilon_reducao = epsilon_reducao
self.epsilon_final = epsilon_final
self.erro_treinamento = []
def buscar_acao(self, obs: tuple[int, int, bool]) -> int:
""" Retorna a melhor ação com probabilidade (1 - épsilon)
caso contrário, uma ação aleatória com probabilidade épsilon para garantir a exploração.
"""
if np.random.random() < self.epsilon:
# com probabilidade épsilon retornar um acao aleatório para explorar o ambiente
return env.action_space.sample()
else:
# com probabilidade (1 - épsilon) agir avidamente (explorar)
return int(np.argmax(self.valores_q[obs]))
def alterar_valores_q_acao(
self, obs: tuple[int, int, bool], acao: int,
recompensa: float, terminou: bool, proxima_observacao: tuple[int, int, bool]):
""" Altera os valores-Q de uma ação """
valor_q_futuro = (not terminou) * np.max(self.valores_q[proxima_observacao])
diferenca_temporal = (recompensa + self.fator_desconto * valor_q_futuro - self.valores_q[obs][acao])
self.valores_q[obs][acao] = (self.valores_q[obs][acao] + self.taxa_aprendizado * diferenca_temporal)
self.erro_treinamento.append(diferenca_temporal)
def reduzir_epsilon(self):
self.epsilon = max(self.epsilon_final, self.epsilon - epsilon_reducao)Instancie o objeto da classe AgenteBlackjack na variável agente.
# hyperparameters
taxa_aprendizado = 0.01
n_episodios = 100_000
epsilon_inicial = 1.0
epsilon_reducao = epsilon_inicial / (n_episodios / 2) # reduzir a exploração com o tempo
epsilon_final = 0.1
agente = AgenteBlackjack(
taxa_aprendizado=taxa_aprendizado,
epsilon_inicial=epsilon_inicial,
epsilon_reducao=epsilon_reducao,
epsilon_final=epsilon_final,
)Ótimo, vamos treinar!
Informação: Os hiperparâmetros atuais são configurados para treinar rapidamente um agente decente. Se você deseja convergir para a política ideal, tente aumentar os n_episodios em 10x e diminuir a taxa_aprendizado (por exemplo, para 0,001).
Para treinar o agente, vamos deixar o agente jogar um episódio (um jogo completo é chamado de episódio) de cada vez e, em seguida, atualizar seus valores Q após cada episódio.
O agente terá que vivenciar muitos episódios para explorar suficientemente o ambiente.
Laço de treinamento
Agora devemos estar prontos para construir o laço de treinamento.
env = gym.wrappers.RecordEpisodeStatistics(env, deque_size=n_episodios)
for episode in tqdm(range(n_episodios)):
obs, info = env.reset()
feito = False
# jogue um episódio
while not feito:
acao = agente.buscar_acao(obs)
proxima_observacao, recompensa, terminou, truncou, info = env.step(bool(acao))
# atualizar o agente
agente.alterar_valores_q_acao(obs, acao, recompensa, terminou, proxima_observacao)
# atualizar se o ambiente foi finalizado e a observação atual é a última
feito = terminou or truncou
obs = proxima_observacao
agente.reduzir_epsilon()Visualizando o treinamento :
comprimento_rolamento = 500
fig, axs = plt.subplots(ncols=3, figsize=(12, 5))
# computar e atribuir uma média movel dos dados para fornecer um gráfico mais suave
uns = np.ones(comprimento_rolamento)
def envolver(titulo, ax, array, uns=uns, comprimento_rolamento=comprimento_rolamento):
media_movel = np.convolve(array, uns, mode="same") / comprimento_rolamento
ax.set_title(titulo)
ax.plot(range(len(media_movel)), media_movel)
envolver("Recompensas por Episódio",axs[0],np.array(env.return_queue).flatten())
envolver("Tamanho dos Episódios",axs[1],np.array(env.length_queue).flatten())
envolver("Erro de Treinamento",axs[2],np.array(agente.erro_treinamento))
plt.tight_layout()
plt.show()
Criar a grade de valores e a grade de políticas a partir de um agente, visualizando a política:
def criar_grades(agente, usable_ace=False):
# Converte os valores de ação para valores de estado
# e controi um dicionário de política que mapeia observações para ações
valor_estado = defaultdict(float)
policy = defaultdict(int)
for obs, action_values in agente.valores_q.items():
valor_estado[obs] = float(np.max(action_values))
policy[obs] = int(np.argmax(action_values))
contagem_jogadores, contagem_dealers = np.meshgrid(
# Contagem de jogadores, cartas na mão do dealer
np.arange(12, 22),
np.arange(1, 11),
)
# Criar a grade de valores para plotagem
valor = np.apply_along_axis(
lambda obs: valor_estado[(obs[0], obs[1], usable_ace)],
axis=2,
arr=np.dstack([contagem_jogadores, contagem_dealers]),
)
valor_grade = contagem_jogadores, contagem_dealers, valor
# Criar a grade de políticas para plotagem
politica_grade = np.apply_along_axis(
lambda obs: policy[(obs[0], obs[1], usable_ace)],
axis=2,
arr=np.dstack([contagem_jogadores, contagem_dealers]),
)
return valor_grade, politica_gradeCriar uma plotagem usando uma grade de valores e uma grade de políticas.
def criar_plotagens(valor_grade, politica_grade, title: str):
# Criar uma nova figura com 2 subplots (esquerda: valores de estado, direita: política)
contagem_jogadores, contagem_dealers, valor = valor_grade
fig = plt.figure(figsize=plt.figaspect(0.4))
fig.suptitle(title, fontsize=16)
# Plotar os valores de estado
ax1 = fig.add_subplot(1, 2, 1, projection="3d")
ax1.plot_surface(
contagem_jogadores,
contagem_dealers,
valor,
rstride=1,
cstride=1,
cmap="viridis",
edgecolor="none",
)
plt.xticks(range(12, 22), range(12, 22))
plt.yticks(range(1, 11), ["A"] + list(range(2, 11)))
ax1.set_title(f"Valores de Estado: {title}")
ax1.set_xlabel("Soma do jogador")
ax1.set_ylabel("Dealer mostrando")
ax1.zaxis.set_rotate_label(False)
ax1.set_zlabel("Valor", fontsize=14, rotation=90)
ax1.view_init(20, 220)
# Plotar a política
fig.add_subplot(1, 2, 2)
ax2 = sns.heatmap(politica_grade, linewidth=0, annot=True, cmap="Accent_r", cbar=False)
ax2.set_title(f"Política: {title}")
ax2.set_xlabel("Soma do jogador")
ax2.set_ylabel("Dealer mostrando")
ax2.set_xticklabels(range(12, 22))
ax2.set_yticklabels(["A"] + list(range(2, 11)), fontsize=12)
# Adicionar a legenda
legend_elements = [
Patch(facecolor="lightgreen", edgecolor="black", label="Hit"),
Patch(facecolor="grey", edgecolor="black", label="Stick"),
]
ax2.legend(handles=legend_elements, bbox_to_anchor=(1.3, 1))
return figValores de estado e a política com uso de ás (ás conta como 11)
valor_grade, politica_grade = criar_grades(agente, usable_ace=True)
fig1 = criar_plotagens(valor_grade, politica_grade, title="Com uso de ás")
plt.show()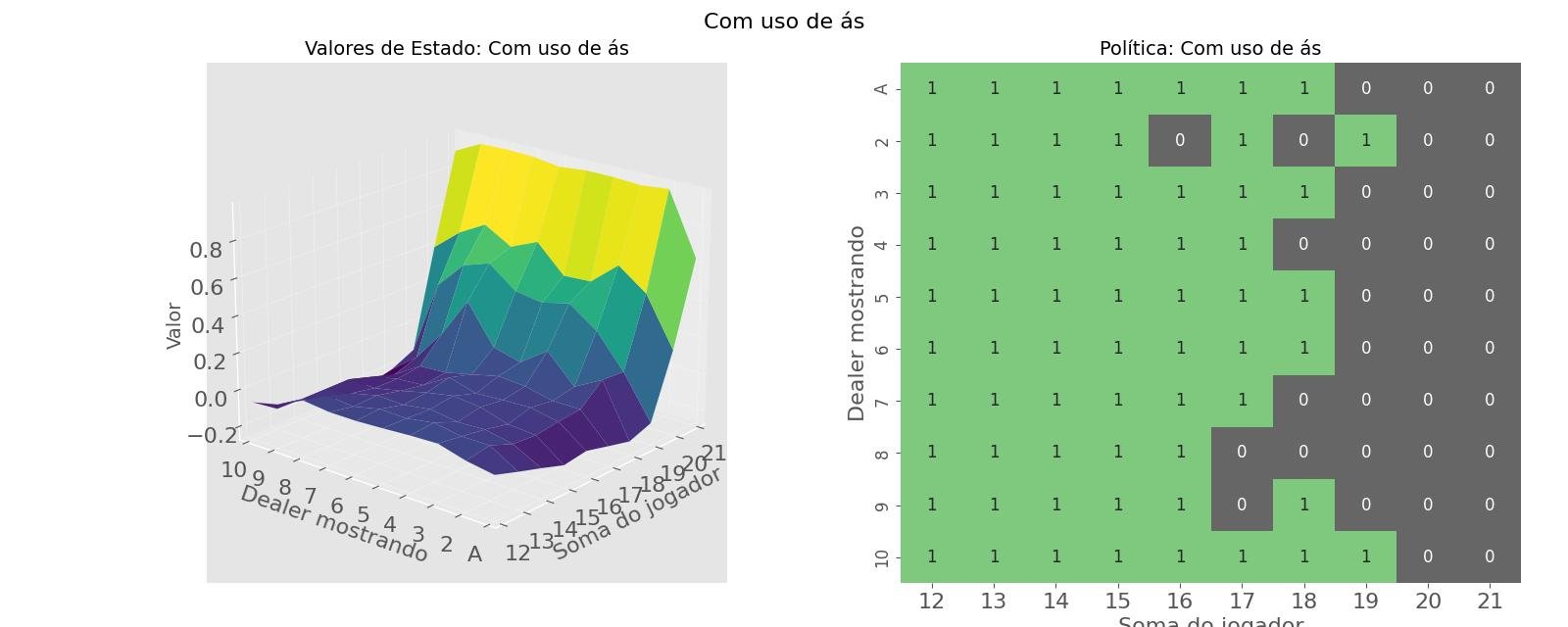
Valores de estado e a política sem uso de ás (ás conta como 1)
valor_grade, politica_grade = criar_grades(agente, usable_ace=False)
fig2 = criar_plotagens(valor_grade, politica_grade, title="Sem uso de ás")
plt.show()
É uma boa prática chamar env.close() ao final do seu script, para que quaisquer recursos utilizados pelo ambiente sejam encerrados.
env.close()O Q-learning é um algoritmo de reforço que aprende a avaliar o valor de cada estado. O algoritmo de política gradiente aprende a gerar uma política ótima. O aprendizado temporal-diferença aprende a estimar o valor de cada estado com base em observações passadas.
O código acima é um exemplo de como o Q-learning pode ser usado para aprender a jogar o jogo CartPole. O código pode ser modificado para usar outros algoritmos de reforço, como o algoritmo de política gradiente ou o aprendizado temporal-diferença.
12.3 - Projeto Avançado: Controle de Ar Condicionado
Esse código é um exemplo de implementação de um ambiente de aprendizado de máquina usando a biblioteca OpenAI Gym.
O ambiente é uma sala com um sistema de ar condicionado (AC) controlado por um agente de aprendizado de máquina.
O objetivo do agente é regular a temperatura dentro da sala para que ela se mantenha próxima a uma temperatura de configuração (T_set).
Esse ambiente é projetado para permitir que um agente de aprendizado de máquina aprenda a controlar o sistema de ar condicionado para manter a temperatura interna da sala próxima à temperatura desejada (T_set).
O agente pode escolher uma ação que afeta a potência do AC, e ele é recompensado com base na diferença entre a temperatura interna e a temperatura desejada.
O objetivo do agente é maximizar a recompensa, ou seja, manter a temperatura da sala o mais próxima possível de T_set.
Importar Bibliotecas
- import numpy as np: Importa a biblioteca NumPy e a apelida como 'np'.
- import random: Importa a biblioteca Random para geração de números aleatórios.
- import matplotlib.pyplot as plt: Importa a biblioteca Matplotlib para plotagem de gráficos.
- import time: Importa a biblioteca Time para lidar com o tempo.
- import gym: Importa a biblioteca Gym, que é usada para criar ambientes de aprendizado por reforço.
- from stable_baselines3 import DQN, A2C, PPO, DDPG: Importa algoritmos de aprendizado por reforço da biblioteca Stable Baselines3. Neste caso, estão sendo importados DQN, A2C, PPO e DDPG, que são algoritmos populares de aprendizado profundo por reforço.
from gym import spaces: Importa o módulo 'spaces' da biblioteca Gym, que é usado para definir os espaços de observação e ação do ambiente.
import numpy as np
import random
import time
import gym
from gym import spaces
from stable_baselines3 import DQN, A2C, PPO, DDPG
import matplotlib.pyplot as pltClasse Quarto
Essa classe representa a sala controlada pelo sistema de ar condicionado.
- __init__: Inicializar os parâmetros do ambiente, como capacidade térmica (mC), constante de transferência de calor (K), potência máxima do AC (Q_AC_Max), tempo de simulação (tempo_simulacao) e passo de controle (tempo_passo).
- reiniciar: Redefinir o ambiente, com uma temperatura inicial especificada (T_in).
- agendar: Criar um perfil de temperatura interna para a sala e define um perfil de temperatura externa (T_out) ao longo do tempo.
- alterar_Tin: Atualizar a temperatura interna da sala com base na ação de controle do AC.
class Quarto:
def __init__(self, mC=300, K=20, Q_AC_Max = 1500, tempo_simulacao = 12*60*60, tempo_passo = 300):
self.tempo_passo = tempo_passo
self.max_iteracao = int(tempo_simulacao/self.tempo_passo)
self.Q_AC_Max = Q_AC_Max
self.mC = mC
self.K = K
def reiniciar(self,T_in = 20):
self.iteracao = 0
self.agendar()
self.T_in = T_in
def agendar(self):
self.T_set = 25
self.T_out = np.empty(self.max_iteracao)
self.T_out[:int(self.max_iteracao/2)] = 28
self.T_out[int(self.max_iteracao/2):int(self.max_iteracao)]= 32
def alterar_Tin(self, action):
self.Q_AC = action*self.Q_AC_Max #
self.T_in = self.T_in - 0.001*(self.tempo_passo / self.mC) * (self.K*(self.T_in-self.T_out[self.iteracao])+self.Q_AC)
self.iteracao += 1Classe Quarto_GymAC
Essa classe é uma implementação de um ambiente do Gym.
Métodos:
- __init__: inicializa o ambiente do Gym com parâmetros semelhantes aos da classe Quarto.
- reset: redefine o ambiente e gera uma temperatura inicial aleatória.
- step: executa um passo no ambiente com uma ação de controle especificada, atualiza a temperatura interna e calcula a recompensa do agente.
- render: é usado para renderizar o ambiente (não implementado).
- close: close é usado para fechar o ambiente (não implementado).
class Quarto_GymAC(gym.Env):
metadata = {'render.modes' : ['human']}
def __init__(self, mC=300, K=20, Q_AC_Max = 1000, tempo_simulacao = 12*60*60, tempo_passo = 300):
super(Quarto_GymAC, self).__init__()
self.AC_sim = Quarto(mC=300, K=20, Q_AC_Max = 1000, tempo_simulacao = 12*60*60, tempo_passo = 300)
self.time_step = tempo_passo
self.Q_AC_Max = Q_AC_Max
self.action_space = spaces.Box(low = -1, high = 1, shape=(1,))
self.observation_space = spaces.Box(low = -100, high = 100, shape =(1,))
self.observacao = np.empty(1)
def reset(self):
self.AC_sim.reiniciar(T_in = np.random.randint(20, 30))
self.iter = 0
self.observacao[0] = self.AC_sim.T_in - self.AC_sim.T_set
return self.observacao
def step(self, action):
self.AC_sim.alterar_Tin(action=action)
self.observacao[0] = self.AC_sim.T_in - self.AC_sim.T_set
self.iter += 1
if self.iter >= self.AC_sim.max_iteracao:
done = True
else:
done = False
self.reward = np.exp(-(abs(10*self.observacao)))[0]
info = {}
return self.observacao, self.reward, done, info
def render(self, mode='human'):
pass
def close (self):
passCriação do ambiente e do modelo de aprendizado
- env = GymACRoom(): Cria uma instância do ambiente GymACRoom, que foi definido na primeira parte do código.
- model = A2C(policy='MlpPolicy', env=env, verbose=0, learning_rate=0.001): Cria um modelo de aprendizado por reforço usando o algoritmo A2C (Advantage Actor-Critic). O modelo é inicializado com uma política de rede neural feedforward ('MlpPolicy') e configurações como verbose (nível de verbosidade) igual a 0 e taxa de aprendizado igual a 0.001. O modelo será treinado para aprender a controlar o ambiente.
env = Quarto_GymAC()
model = A2C(policy = 'MlpPolicy', env=env, verbose=0, learning_rate=0.001)Treinamento do modelo
- model.learn(total_timesteps=10000): Treina o modelo por um número total de etapas de tempo especificado (total_timesteps). Neste caso, o modelo é treinado por 10.000 etapas de tempo, durante as quais ele aprenderá a realizar ações no ambiente para otimizar a recompensa.
model.learn(total_timesteps = 10000)Execução do modelo treinado
- done = False: Inicializa a variável "done" como False, que indica se o episódio no ambiente terminou.
- env = GymACRoom(): Cria uma nova instância do ambiente.
- obs = env.reset(): Inicializa o ambiente e obtém a primeira observação.
- action_profile, reward_profile, temperatue_set e temperature_achieved são listas vazias que serão usadas para registrar informações durante a execução do modelo.
done = False
env = Quarto_GymAC()
obs = env.reset()
perfil_acao = []
perfil_recompensa = []
temperatura_definicao = []
temperatura_alcancada = []Loop de execução do ambiente com o modelo treinado
Um loop é usado para executar o ambiente com o modelo treinado até que o episódio esteja concluído (done=True).
- while not done:: Enquanto o episódio não estiver concluído.
- act = model.predict(obs): O modelo prevê uma ação com base na observação atual.
- obs, reward, done, info = env.step(act[0]): A ação prevista é executada no ambiente, resultando em uma nova observação, uma recompensa, uma indicação de término do episódio e informações adicionais.
- perfil_acao.append(act[0][0]): Registra a ação tomada pelo modelo.
- perfil_recompensa.append(env.observacao[0]): Registra a recompensa recebida pelo modelo.
- temperatura_alcancada.append(env.AC_sim.T_in[0]): Registra a temperatura desejada pelo modelo.
- temperatura_definicao.append(env.AC_sim.T_set): Registra a temperatura definida pelo modelo.
As informações sobre a ação, a recompensa, a temperatura desejada (temperatue_set) e a temperatura atingida (temperature_achieved) são registradas em suas respectivas listas a cada etapa de tempo.
while not done:
act = model.predict(obs)
obs, reward, done, info = env.step(act[0])
perfil_acao.append(act[0][0])
perfil_recompensa.append(env.observacao[0])
temperatura_alcancada.append(env.AC_sim.T_in[0])
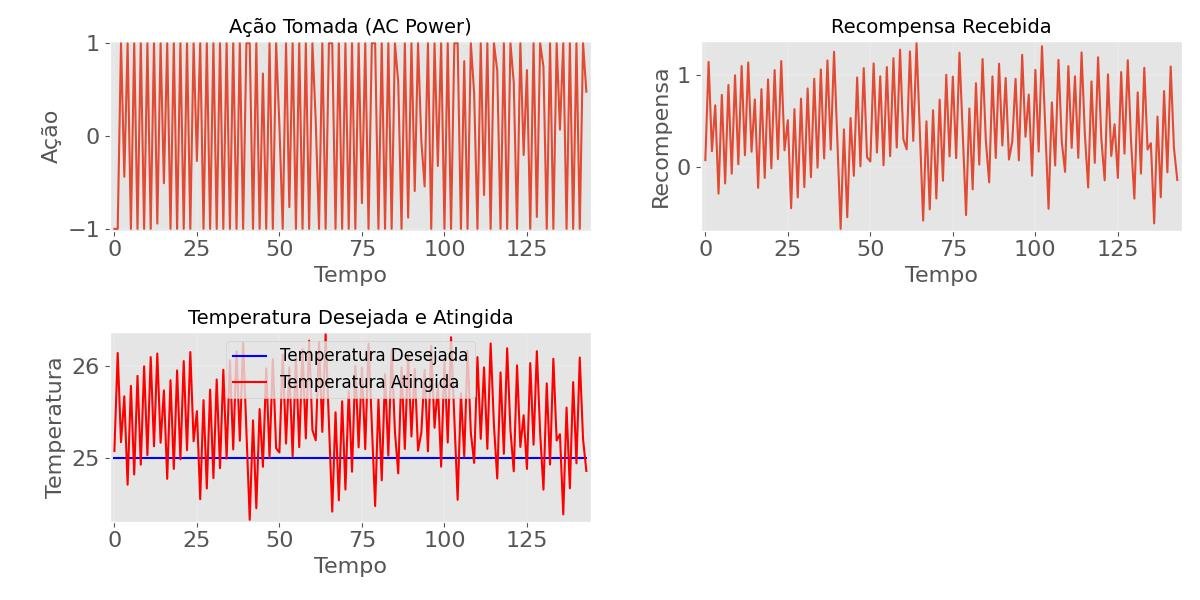
temperatura_definicao.append(env.AC_sim.T_set)Esse código executa o modelo treinado no ambiente GymACRoom e registra várias informações relevantes, como as ações tomadas pelo modelo, as recompensas recebidas e as temperaturas desejadas e atingidas ao longo do tempo.
Isso permite a análise do desempenho do agente de aprendizado de máquina no controle do sistema de ar condicionado da sala.
def graficos_1(perfil_acao, perfil_recompensa, temperatura_definicao, temperatura_alcancada):
# Gráfico da ação tomada (perfil_acao)
plt.figure(figsize=(12, 6))
plt.subplot(2, 2, 1)
plt.plot(perfil_acao)
plt.title('Ação Tomada (AC Power)')
plt.xlabel('Tempo')
plt.ylabel('Ação')
# Gráfico da recompensa recebida (perfil_recompensa)
plt.subplot(2, 2, 2)
plt.plot(perfil_recompensa)
plt.title('Recompensa Recebida')
plt.xlabel('Tempo')
plt.ylabel('Recompensa')
# Gráfico da temperatura desejada (temperature_set) e temperatura atingida (temperatura_alcancada)
plt.subplot(2, 2, 3)
plt.plot(temperatura_definicao, label='Temperatura Desejada', color='blue')
plt.plot(temperatura_alcancada, label='Temperatura Atingida', color='red')
plt.title('Temperatura Desejada e Atingida')
plt.xlabel('Tempo')
plt.ylabel('Temperatura')
plt.legend()
# Mostrar todos os gráficos
plt.tight_layout()
plt.show()
def graficos_2(perfil_acao, perfil_recompensa, temperatura_definicao, temperatura_alcancada):
# Gráfico da ação tomada (perfil_acao)
plt.figure(figsize=(12, 4))
plt.subplot(141)
plt.plot(perfil_acao)
plt.title('Ação Tomada (AC Power)')
plt.xlabel('Tempo')
plt.ylabel('Ação')
# Gráfico da recompensa recebida (perfil_recompensa)
plt.subplot(142)
plt.plot(perfil_recompensa)
plt.title('Recompensa Recebida')
plt.xlabel('Tempo')
plt.ylabel('Recompensa')
# Gráfico da temperatura desejada (temperature_set)
plt.subplot(143)
plt.plot(temperatura_definicao)
plt.title('Temperatura Desejada')
plt.xlabel('Tempo')
plt.ylabel('Temperatura (°C)')
# Gráfico da temperatura atingida (temperatura_alcancada)
plt.subplot(144)
plt.plot(temperatura_alcancada)
plt.title('Temperatura Atingida')
plt.xlabel('Tempo')
plt.ylabel('Temperatura (°C)')
# Mostrar todos os gráficos
plt.tight_layout()
plt.show()graficos_1(perfil_acao, perfil_recompensa, temperatura_definicao, temperatura_alcancada)
graficos_2(perfil_acao, perfil_recompensa, temperatura_definicao, temperatura_alcancada)