6 - Métricas de Avaliação de Modelos
As métricas de avaliação são usadas para medir o desempenho e a eficácia de modelos de Aprendizado de Máquina em tarefas de classificação e outras tarefas de previsão, proporcionando avaliar a qualidade das previsões do modelo e entender sua capacidade de generalização para novos dados.
Algumas das métricas mais comuns incluem:
- Precisão (Precision): A precisão é a proporção de exemplos positivos corretamente classificados em relação a todos os exemplos classificados como positivos (verdadeiros positivos e falsos positivos). Uma alta precisão indica que o modelo tem poucos falsos positivos, ou seja, ele é bom em classificar corretamente os exemplos positivos, mas pode ter muitos falsos negativos. Fórmula: $precisão = \frac{TP}{TP + FP}$
- Revocação (Recall ou Sensibilidade): A revocação é a proporção de exemplos positivos corretamente classificados em relação a todos os exemplos positivos no conjunto de dados (verdadeiros positivos e falsos negativos).Uma alta revocação indica que o modelo é bom em identificar a maioria dos exemplos positivos, mas pode gerar muitos falsos positivos. Fórmula: $revocação = \frac{TP}{TP + FN}$
- Escore F1 (F1S - F1 Score): O escore F1 é uma métrica que combina precisão e revocação em uma única medida. É a média harmônica entre a precisão e a revocação.O escore F1 é útil quando há um desequilíbrio significativo entre as classes, pois equilibra a importância das duas métricas. Fórmula: ${f1s} = 2 . \frac{precisão _x revocação}{precisão + revocação}$.
- Acurácia (Accuracy): A acurácia é a proporção de exemplos corretamente classificados em relação ao total de exemplos no conjunto de dados. A acurácia é uma métrica geral que funciona bem quando as classes são balanceadas, mas pode ser enganosa quando há um desequilíbrio significativo entre as classes. Fórmula: $acurácia = \frac{TP + TN}{TP + TN + FP + FN}$.
- Especificidade (Specificity): A especificidade é a proporção de exemplos negativos corretamente classificados em relação a todos os exemplos negativos no conjunto de dados (verdadeiros negativos e falsos positivos). A especificidade é especialmente importante quando a classe negativa é a classe de interesse. Fórmula: $especificidade = \frac{TN}{TN + FP}$
- Erro Quadrático Médio (MSE - Mean Squared Error): MSE é uma métrica comumente usada em problemas de regressão. Ele mede o erro médio quadrático entre as previsões do modelo e os valores reais. Fórmula: $mse = \sum_{(i=0)}^n {(alvo_{verdadeiro} - alvo_{previsto})^2}$, onde $alvo_{verdadeiro}$ representa os valores reais do conjunto de dados e $alvo_{previsto}$ representa as previsões feitas pelo modelo.
- Matriz de Confusão (CM - Confusion Matrix): CM é uma tabela usada para avaliar o desempenho de um modelo de Aprendizado de Máquina em problemas de classificação
- Curva ROC (Receiver Operating Characteristic) e Área Sob a Curva (AUC - Area Under the Curve): Métricas de avaliação muito utilizadas em problemas de classificação binária.
É importante selecionar a métrica de avaliação adequada para cada problema específico, levando em consideração as características dos dados, o desequilíbrio de classes e os objetivos do projeto.
Por exemplo, em problemas de detecção de fraudes, é importante ter alta revocação, mesmo que isso signifique sacrificar a precisão.
Além disso, é recomendado usar mais de uma métrica de avaliação para obter uma compreensão completa do desempenho do modelo.
6.1 - Precisão
6.2 - Revocação
6.3 - Escore-F1
6.4 - Acurácia
6.5 - Especificidade
6.6 - Erro Quadrático Médio
6.7 - Matriz de Confusão
A Matriz de Confusão (CM - Confusion Matrix) é uma tabela usada para avaliar o desempenho de um modelo de Aprendizado de Máquina em problemas de classificação, que permite a visualização do número de previsões corretas e incorretas feitas pelo modelo para cada classe do problema.
A matriz de confusão é especialmente útil quando se trabalha com problemas de classificação binária, ou seja, problemas em que há apenas duas classes a serem previstas, como "sim" ou "não", "positivo" ou "negativo", "verdadeiro" ou "falso", etc. No entanto, ela também pode ser adaptada para problemas de classificação multiclasse.
A matriz de confusão possui quatro elementos principais:
- Verdadeiros Positivos (TP - True Positives): Representa o número de exemplos que foram corretamente classificados como positivos pelo modelo. São os casos em que o modelo previu corretamente a classe positiva.
- Falsos Positivos (FP - False Positives): Representa o número de exemplos que foram erroneamente classificados como positivos pelo modelo. São os casos em que o modelo previu a classe positiva, mas a classe real era negativa.
- Verdadeiros Negativos (TN - True Negatives): Representa o número de exemplos que foram corretamente classificados como negativos pelo modelo. São os casos em que o modelo previu corretamente a classe negativa.
- Falsos Negativos (FN - False Negatives): Representa o número de exemplos que foram erroneamente classificados como negativos pelo modelo. São os casos em que o modelo previu a classe negativa, mas a classe real era positiva.
A matriz de confusão é organizada da seguinte forma:
| Classe Real | ||
| Classe Previsão | Positivo | Negativo |
| Positivo | TP | FP | Negativo | FN | TN |
A partir dos valores na matriz de confusão, podemos calcular diversas métricas de avaliação, como precisão, revocação, F1-Score, acurácia, especificidade, etc.
Essas métricas são fundamentais para entender o desempenho do modelo e a sua capacidade de generalização para novos dados.
A matriz de confusão é uma ferramenta importante para o diagnóstico do desempenho do modelo em diferentes classes e permite uma análise mais detalhada das previsões, auxiliando na identificação de possíveis problemas, como o modelo estando enviesado para uma classe específica ou tendo dificuldade em detectar certas classes.
Exemplo:
Este código cria uma matriz de confusão a partir dos rótulos verdadeiros (alvo_verdadeiro) e dos rótulos previstos (alvo_previsto) e, em seguida, gera um gráfico de calor usando a biblioteca seaborn para visualizar a matriz de confusão.
Certifique-se de substituir alvo_verdadeiro e alvo_previsto pelos seus próprios rótulos verdadeiros e previstos. Isso permitirá que você crie uma matriz de confusão personalizada para a sua tarefa de classificação.
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
# Dados de exemplo
alvo_verdadeiro = [1, 0, 1, 1, 0, 1, 0, 0, 1, 0] # Rótulos verdadeiros
alvo_previsto = [1, 0, 1, 0, 1, 1, 0, 1, 1, 0] # Rótulos previstos
# Crie a matriz de confusão
confusion = confusion_matrix(alvo_verdadeiro, alvo_previsto)
# Crie um gráfico de calor para visualizar a matriz de confusão
plt.figure(figsize=(6, 6))
sns.heatmap(confusion, annot=True, fmt='d', cmap='Blues', cbar=False, square=True, xticklabels=['Negativo', 'Positivo'], yticklabels=['Negativo', 'Positivo'])
plt.xlabel('Previsto')
plt.ylabel('Verdadeiro')
plt.title('Matriz de Confusão')
plt.show()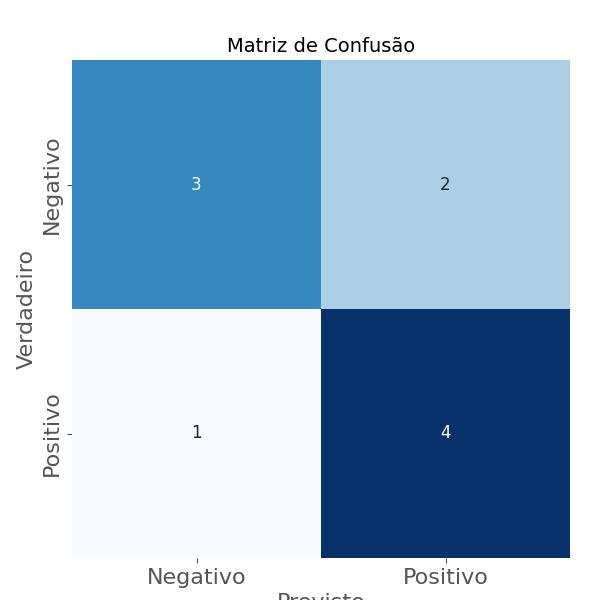
6.8 - Curva ROC e Área Sob a Curva (AUC)
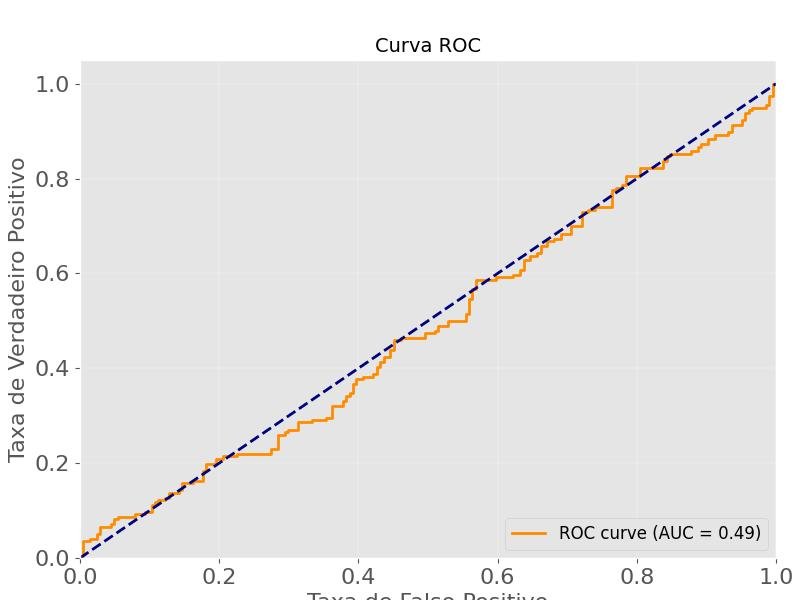
A Curva ROC (Receiver Operating Characteristic) e a Área Sob a Curva (AUC - Area Under the Curve) são métricas de avaliação muito utilizadas em problemas de classificação binária.
A Curva ROC é uma representação gráfica do desempenho do modelo à medida que o limiar de classificação é variado, e a AUC é a área sob essa curva.
Para construir a Curva ROC, o modelo é executado em diferentes limiares de decisão e, para cada limiar, é calculada a taxa de verdadeiros positivos (TPR - True Positive Rate) e a taxa de falsos positivos (FPR - False Positive Rate).
A Curva ROC é criada plotando os valores de TPR (eixo y), em função dos valores de FPR (eixo x) para os diferentes limiares de classificação. Quanto mais próxima a curva ROC estiver do canto superior esquerdo do gráfico, melhor será o desempenho do modelo.
É uma representação gráfica que ilustra a taxa de verdadeiros positivos (revocação) em função da taxa de falsos positivos ao variar o limiar de classificação do modelo.
- Taxa de Verdadeiros Positivos (TPR - True Positive Rate): É a proporção de exemplos positivos corretamente classificados em relação ao total de exemplos positivos (verdadeiros positivos + falsos negativos). Fórmula: $TPR = \frac{TP}{TP + FN}$
- Taxa de Falsos Positivos (FPR - False Positive Rate): É a proporção de exemplos negativos incorretamente classificados como positivos em relação ao total de exemplos negativos (verdadeiros negativos + falsos positivos). Fórmula: $FPR = \frac{FP}{FP + TN}$
A Área Sob a Curva (AUC) é uma métrica numérica que representa a área sob a Curva ROC.
A AUC é um número entre 0 e 1, sendo que um modelo com AUC igual a 1 é considerado perfeito (classifica corretamente todos os exemplos), e um modelo com AUC igual a 0.5 é equivalente a um classificador aleatório.
Em geral, quanto maior a AUC, melhor é o desempenho do modelo na classificação das duas classes.
A AUC é uma métrica útil para problemas de classificação binária, especialmente quando as classes estão desbalanceadas ou quando a taxa de verdadeiros positivos e falsos positivos são igualmente importantes para a avaliação do modelo.
A Curva ROC e a AUC são métricas robustas e amplamente utilizadas para avaliar e comparar o desempenho de diferentes modelos de classificação em problemas binários, permitindo uma avaliação mais abrangente do desempenho do modelo em diferentes limiares de classificação, fornecendo uma visão completa da capacidade de discriminação do modelo entre as classes positiva e negativa.
Exemplo:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, roc_auc_score, auc
data = {
'caracteristica1': np.random.rand(2000),
'caracteristica2': np.random.rand(2000),
'alvo': np.random.randint(0, 2, 2000)
}
df = pd.DataFrame(data)
# Dividindo os dados em conjunto de treinamento e teste
X = df[['caracteristica1', 'caracteristica2']]
y = df['alvo']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Treinando um modelo de regressão logística (você pode substituir por seu próprio modelo)
model = LogisticRegression()
model.fit(X_train, y_train)
# Obtendo as probabilidades previstas para a classe positiva
y_scores = model.predict_proba(X_test)[:, 1]
# Calculando a curva ROC
fpr, tpr, _ = roc_curve(y_test, y_scores)
# Calculando a AUC (Área sob a Curva ROC)
roc_auc = auc(fpr, tpr)
# Plotando a curva ROC
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('Taxa de Falso Positivo')
plt.ylabel('Taxa de Verdadeiro Positivo')
plt.title('Curva ROC')
plt.legend(loc='lower right')
plt.show()